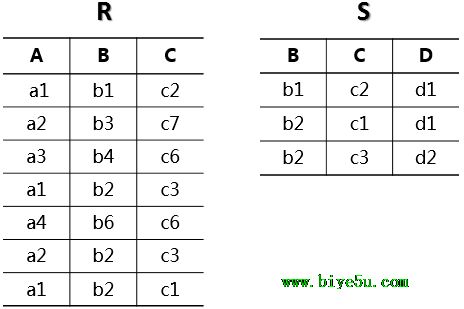
如果使用了目录数据库的方式,在master shutdown阶段需要delete或者update dead master的记录。在new master激活阶段,可以insert/update new master的记录。还有,可以做任何你需要做的事,使得应用可以写入new master。比如,SET GLOBAL read_only=0,创建拥有write权限的数据库用户,等等。
如果使用了目录数据库的方式,在master shutdown阶段需要delete或者update dead master的记录。在new master激活阶段,可以insert/update new master的记录。还有,可以做任何你需要做的事,使得应用可以写入new master。比如,SET GLOBAL read_only=0,创建拥有write权限的数据库用户,等等。