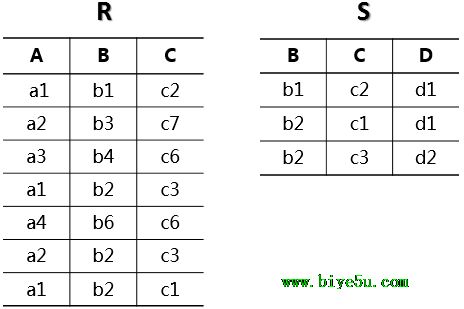
web应用为了记录点击次数,可以设计一个点击次数表,create table hit_counter(cnt int unsigned not null);由于只有一条记录这样锁争用太严重,想到了什么解决方案,同concurrenthashmap一样做锁拆分。
表结构修改为:
create table hit_counter(slot tinyint unsigned not null primary key,cnt int unsigned not null);--phpfensi.com
预先放入100条数据,这样修改的时候可以使用如下语句,update hit_counter set cnt = cnt+1 where slot = RAND()*100;获取的时候求和就可以了,select sum(cnt) cnt from hit_counter;不知道iteye的博客计数是不是也采用了类似的设计.