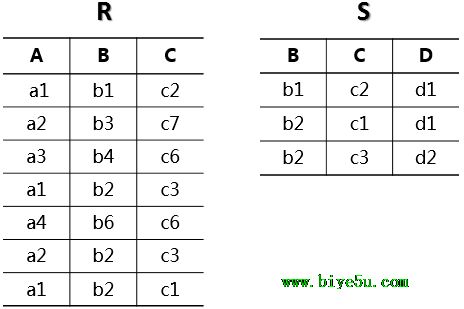
越来越多现代分布式云服务,通过解耦计算与存储,以及跨越多节点复制的方式实现了弹性与可伸缩性。这样做,可以让我们进行某些操作,例如替换失误或者不可达的主机,添加复制节点,写入节点与复制节点的故障转移,拓展或者收缩数据库实例的大小等等。在这种环境下,传统的数据库系统所面临的IO瓶颈发生改变。因为IO可以分散到多租户集群中的多个节点和多个磁盘中,导致单个磁盘和节点不在是热点。相反,瓶颈转移到发起这些IO请求的数据库层与执行这些IO请求的存储层之间的网络中。除了每秒包数(packets per second , PPS)以及带宽这种基本瓶颈外,一个高性能的数据库会向发起存储机群并行的写入,从而放大了网络流量。某个异常存储节点的性能,磁盘或者网络通路,都会严重影响响应时间。
现在我们考虑AZ+1情况是否能提供足够的持久性问题。在这个模型中要提供足够的持久性,就必须保证两次独立故障发生的概率(平均故障时间,Mean Time to Failure, MTTF)足够低于修复这些故障的时间(Mean Time to Repair, MTTR)。如果两次故障的概率够高,我们可能看到可用区失效,打破了冲裁。减少独立失效的MTTF,哪怕是一点点,都是很困难的。相反,我们更关注减少MTTR,缩短两次故障的脆弱的时间窗口。我们是这样做的:将数据库卷切分成小的固定大小的段,目前是10G大小。每份数据项以6路复制到保护组(protection Group,PG)中,每个保护组由6个10GB的段组成,分散在3个可用区中。每个可用区持有2个段。一个存储卷是一组相连的PG集合,在物理上的实现是,采用亚马逊弹性计算云(ES2)提供的虚拟机附加SSD,组成的大型存储节点机群。组成存储卷PG随着卷的增长而分配。目前我们支持的卷没有开启复制的情况下可增长达64TB。
考虑到数据库知道那些读操作没有完成,可以在任何时间在每个PG的基础上计算出最小的读取点LSN(Minimum Read Point LSN). 如果有存储节点交流写的可读副本,用来建立所有节点每个PG的最小读取点,那么这个值就叫做保护组最小读取点LSN(Protection Group Min Read Point LSN, PGMRPL). PGMRPL用来标识“低位水线”,低于这个“低位水线”的PG日志记录都是不必要的。换句话说,每个存储段必须保证没有低于PGMRPL的读取点的页读请求。每个存储节点可以从数据库了解到PGMRPL,因此,可以收集旧日志,物化这些页到磁盘中,再安全回收日志垃圾。
现代web应用框架,如Ruby on Rails,都整合了ORM(object-relational mapping, 对象-关系映射)。导致对于应用开发人员来说,数据库模式改变非常容易,但是对DBA来说,如何升级数据库模式就成为一种挑战。在Rail应用中,我们有关于DBA的第一手资料:“数据库迁移“,对于DBA来说是"一周做大把的迁移“,或者是采用一些回避策略,用以保证将来迁移的不那么痛苦。而Mysql提供了自由的模式升级语义,大部分的修改的实现方式是全表复制。频繁的DDL操作是一个务实的现实,我们实现了一种高效的在线DDL,使用(a)基于每页的数据库版本化模式,使用模式历史信息,按需对单独页进行解码。(b)使用写时修改(modify-on-write)原语,实现对单页的最新模式懒更新。
Brailis等人研究了高可用事务系统(Highly Available Transactions, HATs)的问题。他们已经证明分区或者高网络延迟,并不会导致不可用性。可串行化、snapshot隔离级、可重复读隔离级与HAT不兼容。然而其他的隔离级可以达到高可用性。Aurora提供了所有的隔离级,它给了一个简单的假设,即任何时候都只有一个写节点产生日志,日志更新的LSN,是在单个有序域中分配的。