上一次很多朋友写文字屏蔽说到要用正则表达,其实不是我不想用(我正则用得不是很多,看过我之前爬虫的都知道,我直接用BeautifulSoup的网页标签去找内容,因为容易理解也方便,),而是正则用好用精通的很难(看过正则表的应该都知道,里面符号对应的方法规则有很多,很灵活),对于接触编程不久的朋友们来说很可能在编程的过程上浪费很多时间,今天我把经常会用到正则简单介绍下,如果不是很特殊基本都覆盖使用。
1.正则的简单介绍
首先你得导入正则方法 import re正则表达式是用于处理字符串的强大工具,拥有自己独立的处理机制,效率上可能不如str自带的方法,但功能十分灵活给力。它的运行过程是先定一个匹配规则("你想要的内容+正则语法规则"),放入要匹配的字符串,通过正则内部的机制就能检索你想要的信息。
2.findall的常用几种姿势
基本结构大致: nojoke = re.findall(r'匹配的规则','要检索的愿字符串') nojoke就是我们最后通过正则返回的结果,re正则findall查找全部r标识代表后面是正则的语句(这样在代码多的时候好查阅),下面我们看看几个例子好深入了解

这段代码是找出检索字符串中所有的bi并以列表的形式返回,这个会经常用到计算统一字符出现的次数。继续看下一个
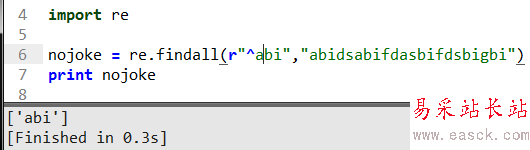
这里加了个符号^表示匹配以abi开头的的字符串返回,也可以判断字符串是否以abi开始的。
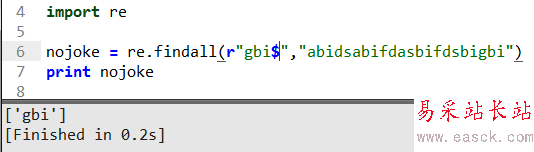
这里在的用$符号表示以gbi结尾的字符串返回,判断是否字符串结束的字符串。
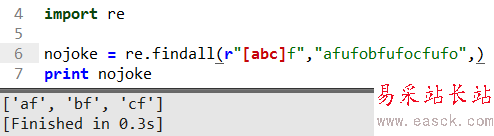
这里[...]的意思匹配括号内a和f,或者b和f,或者c和f的值返回列表。
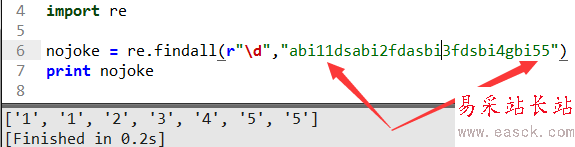
“/d”是正则语法规则用来匹配0到9之间的数返回列表,需要注意的是11会当成字符串'1'和'1'返回而不是返回'11'这个字符串,切记用不好这里是大坑。
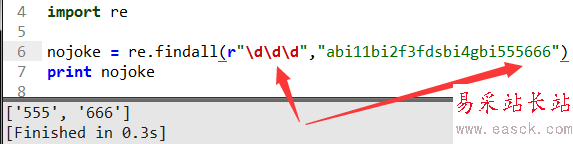
当然解决的办法就你要取几位数就写几个/d,上面这里演示取字符串中3位数字,这里展现了正则灵活一方面。
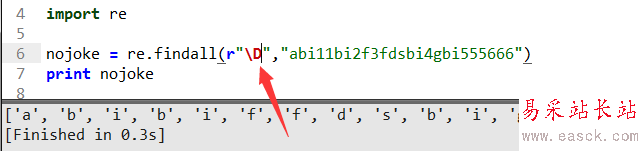
这里小d表示取数字0-9,大D表示不要数字,也就是出了数字以外的内容返回。
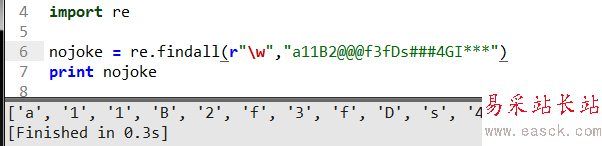
“/w”在正则里面代表匹配从小写a到z,大写A到Z,数字0到9包含前面这三种的如上面打印的一样.

"/W"在正则里面代表匹配除了字母与数字以外的特殊符号,但这里/斜杠的用法要注意在字符串/是转义符号具体百度去学。
新闻热点






疑难解答













