本文实例讲述了Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能。分享给大家供大家参考,具体如下:
一、背景:
小编在爬虫的时候肯定会遇到被封杀的情况,昨天爬了一个网站,刚开始是可以了,在settings的设置DEFAULT_REQUEST_HEADERS伪装自己是chrome浏览器,刚开始是可以的,紧接着就被对方服务器封杀了。
代理:
代理,代理,一直觉得爬去网页把爬去速度放慢一点就能基本避免被封杀,虽然可以使用selenium,但是这个坎必须要过,scrapy的代理其实设置起来很简单。
注意,request.meta['proxy']=代理ip的API
middlewares.py
class HttpbinProxyMiddleware(object): def process_request(self, request, spider): pro_addr = requests.get('http://127.0.0.1:5000/get').text request.meta['proxy'] = 'http://' + pro_addr #request.meta['proxy'] = 'http://' + proxy_ip设置启动上面我们写的这个代理
settings.py
DOWNLOADER_MIDDLEWARES = { 'httpbin.middlewares.HttpbinProxyMiddleware': 543,}spiders
httpbin_test.py
import scrapyclass HttpbinTestSpider(scrapy.Spider): name = "httpbin_test" allowed_domains = ["httpbin.ort/get"] start_urls = ['http://httpbin.org/get'] def parse(self, response): print(response.text)
origin的值其实就是本地的公网地址,但是因为我们用了代理,这里的ip是美国的一个ip
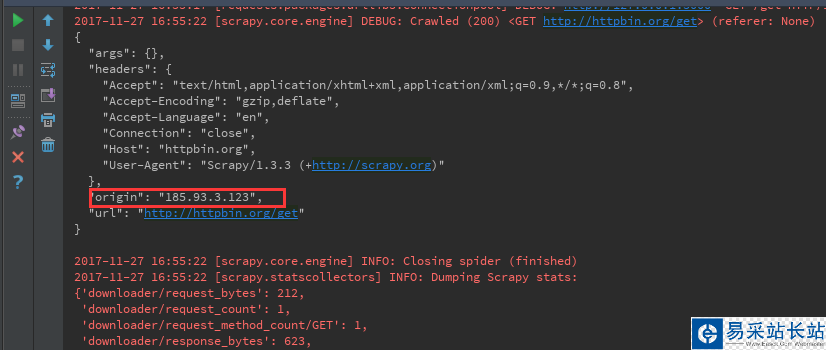
二、那么问题来了,现在有这么一个场景,如上所述的话,我每个请求都会使用代理池里面的代理IP地址,但是有些操作是不需要代理IP地址的,那么怎么才能让它请求超时的时候,再使用代理池的IP地址进行重新请求呢?
spider:
1、我们都知道scrapy的基本请求步骤是,首先执行父类里面(scrapy.Spider)里面的start_requests方法,
2、然后start_requests方法也是取拿我们设置的start_urls变量里面的url地址
3、最后才执行make_requests_from_url方法,并只传入一个url变量
那么,我们就可以重写make_requests_from_url方法,从而直接调用scrapy.Request()方法,我们简单的了解一下里面的几个参数:
1、url=url,其实就是最后start_requests()方法里面拿到的url地址
2、meta这里我们只设置了一个参数,download_timeout:10,作用就是当第一次发起请求的时候,等待10秒钟,如果没有请求成功的话,就会直接执行download_middleware里面的方法,我们下面介绍。
3、callback回调函数,其实就是本次的本次所有操作完成后执行的操作,注意,这里可不是说执行完上面所有操作后,再执行这个操作,比如说请求了一个url,并且成功了,下面就会执行这个方法。
新闻热点






疑难解答













