在计算机并发领域编程中总是会与锁打交道,锁又有很多种,互斥锁、自旋锁等等。
锁总是伴随着线程、进程这样的词汇出现,阮一峰有 一篇文章 对这些名词进行了简单易懂的解释。
我的理解是,使用线程、进程是为了实现并发从而获得性能的提升(利用多核CPU,多台服务器),但这种并发由于调度的不确定性,很容易出乱子,为了(在一些共享资源、关键节点上)不出乱子,又需要对资源加锁,在操作这个资源时控制这种并发,将乱子消灭。
很多语言都提供了一些线程级别的锁实现以及一些相应的工具,但在进程方面就无能为力了。而一个服务部署到生产环境,往往会部署多个实例,这种情况下,就经常会用到给不同进程用的锁,分布式锁便是在分布式系统中对某共享资源进行加锁的构件。
现在来试着展示一下在Python项目中如何使用简单的分布式互斥锁。
不使用分布式锁会怎样
先用一个简单的实例来演示一下,不使用分布式锁会出怎样的乱子。
假设商城系统要做秒杀活动,在redis中记录着 count:1 的信息,到秒杀时间点的时候,会收到许多的请求,这时各应用程序去查redis中count的值,若count还大于0,则将count-1,这样其他请求就不再能秒杀到了。
# -*- coding: utf-8 -*-import osimport arrowimport redisfrom multiprocessing import PoolHOT_KEY = 'count'r = redis.Redis(host='localhost', port=6379)def seckilling(): name = os.getpid() v = r.get(HOT_KEY) if int(v) > 0: print name, ' decr redis.' r.decr(HOT_KEY) else: print name, ' can not set redis.', vdef run_without_lock(name): while True: if arrow.now().second % 5 == 0: seckilling() returnif __name__ == '__main__': p = Pool(16) r.set(HOT_KEY, 1) for i in range(16): p.apply_async(run_without_lock, args=(i, )) print 'now 16 processes are going to get lock!' p.close() p.join() print('All subprocesses done.')以上代码使用多进程来模仿这种并发请求场景,程序开始的时候将count设为1,之后各进程开始进入等待,当秒数为5的时候,所有进程同时去访问秒杀函数,来看一下效果:
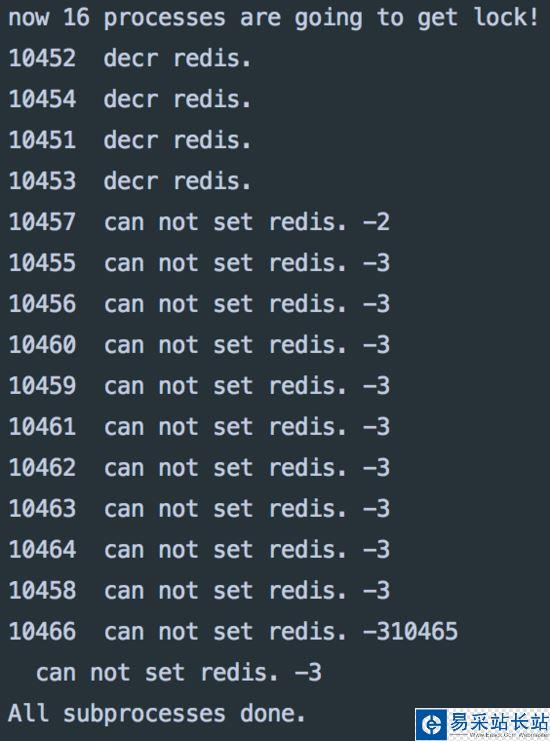
运行结果

新闻热点






疑难解答













