网站不再单单迎合人类读者。许多站点现在支持一些 API,这些 API 使计算机程序能够获取信息。屏幕抓取 —— 将 HTML 页面解析为更容易理解的表单的省时技术 — 仍然很方便。但使用 API 简化 Web 数据提取的机会在快速增多。根据 ProgrammableWeb 的信息,在本文发表时,已存在 10,000 多个网站 API — 在过去的 15 个月中增加了 3,000 个。(ProgrammableWeb 本身提供了一个 API,可从其目录中搜索和检索 API、mashup、成员概要文件和其他数据。)
本文首先介绍现代的 Web 抓取并将它与 API 方法进行比较。然后通过 Ruby 示例,展示如何使用 API 从一些流行的 Web 属性中提取结构化信息。您需要基本理解 Ruby 语言、具象状态传输 (REST),以及 JavaScript 对象表示法 (JSON) 和 XML 概念。
抓取与 API
现在已有多种抓取解决方案。其中一些将 HTML 转换为其他格式,比如 JSON,这样提取想要的内容会更加简单。其他解决方案读取 HTML,您可将内容定义为 HTML 分层结构的一个函数,其中的数据已加了标记。一种此类解决方案是 Nokogiri,它支持使用 Ruby 语言解析 HTML 和 XML 文档。其他开源抓取工具包括用于 JavaScript 的 pjscrape 和用于 Python 的 Beautiful Soup。pjscrape 实现一个命令行工具来抓取完全呈现的页面,包括 JavaScript 内容。Beautiful Soup 完全集成到 Python 2 和 3 环境中。
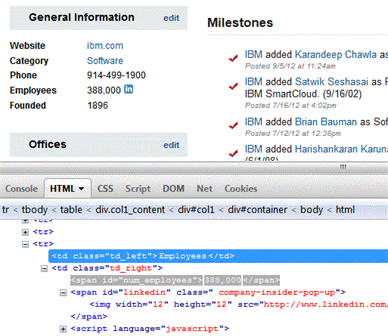
假设您希望使用抓取功能和 Nokogiri 来识别 CrunchBase 所报告的 IBM 员工数量。第一步是理解 CrunchBase 上列出了 IBM 员工数量的特定 HTML 页面的标记。图 1 显示了在 Mozilla Firefox 中的 Firebug 工具中打开的此页面。该图的上半部分显示了所呈现的 HTML,下半部分显示了感兴趣部分的 HTML 源代码。
清单 1 中的 Ruby 脚本使用 Nokogiri 从图 1 中的网页抓取员工数量。
清单 1. 使用 Nokogiri 解析 HTML (parse.rb)
#!/usr/bin/env rubyrequire 'rubygems'require 'nokogiri'require 'open-uri'# Define the URL with the argument passed by the useruri = "http://www.crunchbase.com/company/#{ARGV[0]}"# Use Nokogiri to get the documentdoc = Nokogiri::HTML(open(uri))# Find the link of interestlink = doc.search('tr span[1]')# Emit the content associated with that linkputs link[0].content在 Firebug 显示的 HTML 源代码中(如 图 1 所示),您可看到感兴趣的数据(员工数量)嵌入在一个 HTML 唯一 ID <span> 标记内。还可看到 <span id="num_employees"> 标记是两个 <span> ID 标记中的第一个。所以,清单 1 中的最后两个指令是,使用 link = doc.search('tr span[1]') 请求第一个 <span> 标记,然后使用 puts link[0].content 发出这个已解析链接的内容。
CrunchBase 还公开了一个 REST API,它能够访问的数据比通过抓取功能访问的数据要多得多。清单 2 显示了如何使用该 API 从 CrunchBase 站点提取公司的员工数。
新闻热点






疑难解答