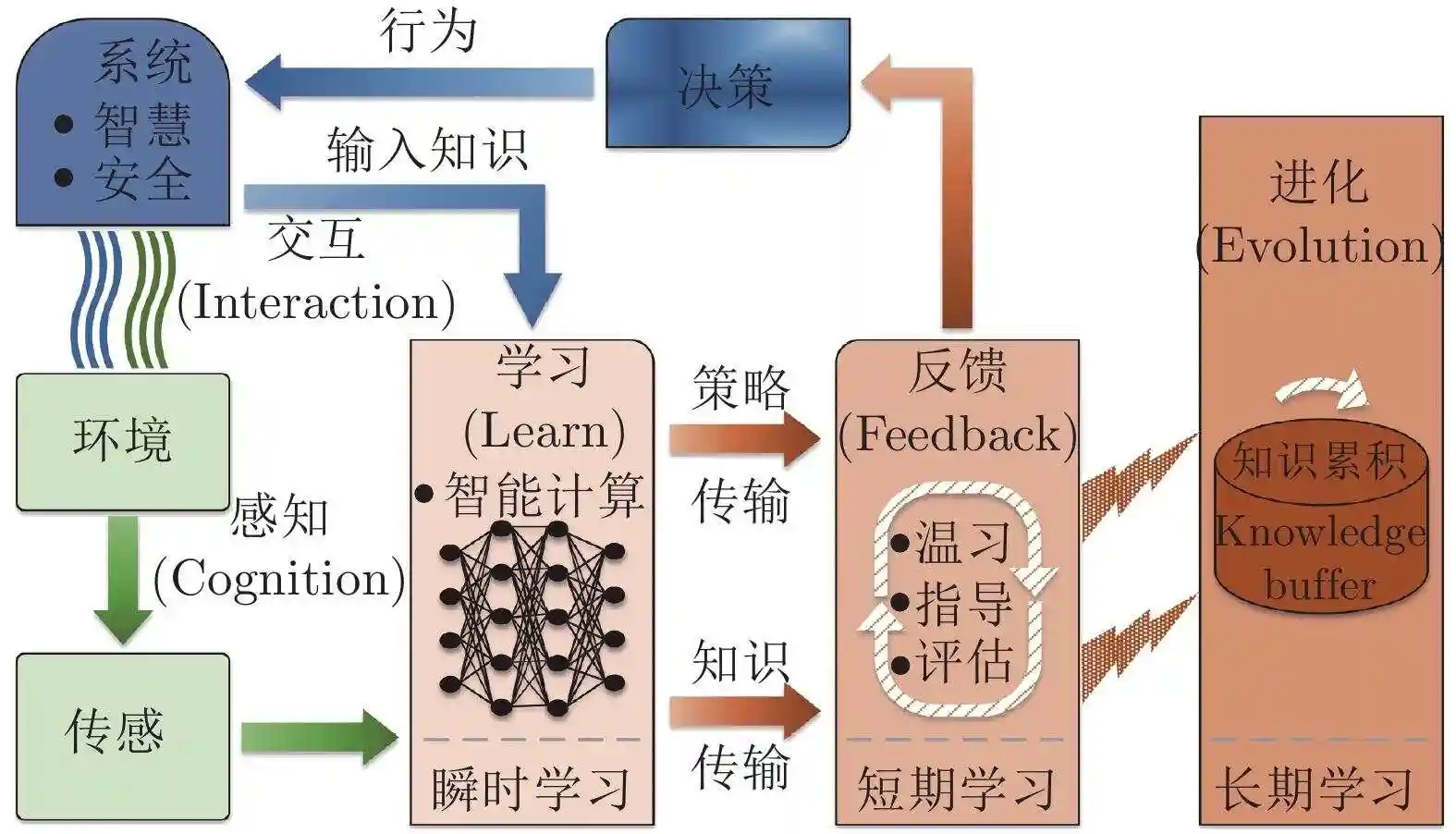
人工智能(AI)领域关注构建智能体,即能感知与行动的实际存在,而更智能的智能体现在其能选择更优的行动方案。因此,“某些行动优于其他”的概念是 AI 的核心。奖励(reward,源于心理学与神经科学的术语)表示提供给智能体与其实际行为质量相关的信号。强化学习(RL) 则是通过奖励信号学习更成功行为的过程。
“从奖励中学习”的理念由来已久,可以追溯到千年以来的动物训练,后来,图灵 1950 年的论文《计算机器与智能》(Computing Machinery and Intelligence)提出“机器能思考吗?”的问题,并提出了基于奖励和惩罚的机器学习方法。