采集是很多用户感觉头疼的事情,实际上也不是那么难的,现在我举例给大家具体说明一下吧,可能不如录像那么直观,我尽量说明白一点。
要采集,则必须满足服务器支持组件:Microsoft.XMLHTTP
点击菜单栏的“常规治理”,选择辅助工具里面的新闻采集。首先设置站点,根据采集对象页面设置过滤条件,设置好之后进行采集,然后审核数据,将数据进行入库,入库之后的数据可以在历史数据里面看到,历史数据不删除,则在采集的时候采集过的文章不会再次采集。假如删掉了历史数据则采集的时候不能过滤采集过的文章的。
下面以中华新闻网的娱乐新闻为例具体说明一下采集的设置,其地址是:
http://www.chinanews.com.cn/entertainment.shtml
一. 站点设置:
1. 建立站点:
 选择站点设置,进入采集站点的设置。
选择站点设置,进入采集站点的设置。
首先选择“新建站点”:
 我们把站点名称取名为“娱乐新闻”,入库目标栏目可以根据需要选择,我设置为Test_1,采集对象页面地址就填写采集站点的地址:http://www.chinanews.com.cn/entertainment.shtml,模板当然是自己选择了,这里因为采集的对象页面可能有图,我设置了保存远程图片,假如不需要采集对象页面的图片也可以不选择。然后保存,则在后台的站点设置里面可以看到我们刚刚建立的站点了。
我们把站点名称取名为“娱乐新闻”,入库目标栏目可以根据需要选择,我设置为Test_1,采集对象页面地址就填写采集站点的地址:http://www.chinanews.com.cn/entertainment.shtml,模板当然是自己选择了,这里因为采集的对象页面可能有图,我设置了保存远程图片,假如不需要采集对象页面的图片也可以不选择。然后保存,则在后台的站点设置里面可以看到我们刚刚建立的站点了。
接下来我们需要修改向导了。
2. 修改向导:
点击修改向导之后出现下面的界面:
 这里就是我们刚刚建立站点设置的参数,直接点击“下一步”,进入设置获取新闻列表的条件:
这里就是我们刚刚建立站点设置的参数,直接点击“下一步”,进入设置获取新闻列表的条件:
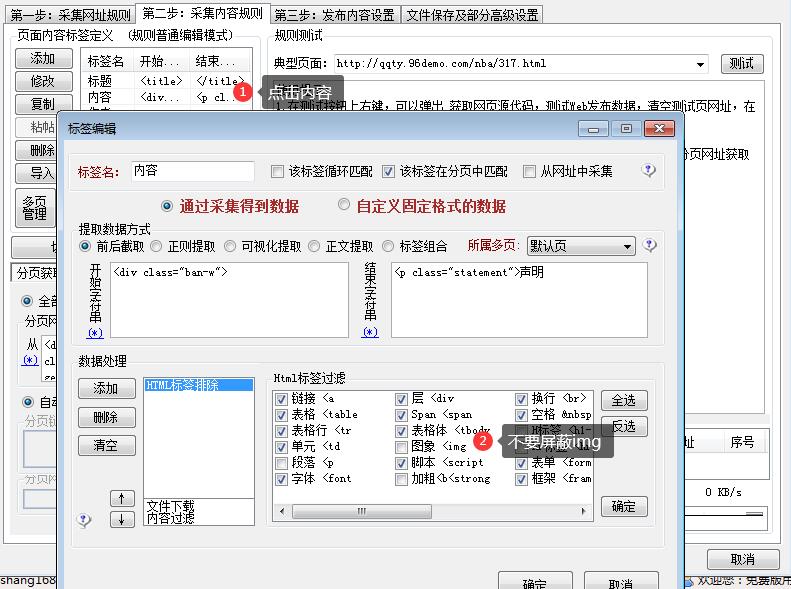
这时我们打开站点,查看采集对象页面的源文件,最好是把源文件拷贝到DW(Dreamweaver)里面,这样比较好找到适合的条件。
在DW里面查看新闻列表的源码:

下图阴影部分则为列表代码:

从图中我们可以看到列表开始的代码是:<table width="100%" border="0" cellpadding="7">,最好是在源文件里面查一下是否这句代码是否是唯一的。假如是唯一的,则可以在设置条件的框里面填上。假如不是唯一的,则可以扩大代码的范围,一定要保证代码的唯一性。
然后我们看一下列表代码结束的地方
 该页面的列表代码结束则是:</table>
该页面的列表代码结束则是:</table>
这样我们找到了列表的开始代码和结束代码,在这两句代码直接则是我们需要获取的新闻列表了,所以我们设置的条件则是如下:

这里不设置分页,所以直接点击下一步进入新闻链接的条件设置:
这个时候你可以看到页面分为了三部分:列表URL条件设置部分,代码部分,结果部分,假如上一步设置正确,则这里的代码部分和结果部分就会显示获取到的新闻列表的代码和新闻列表了。
这里我们开始设置获取链接的代码:
 阴影部分是一条新闻的代码,则我们可以看到,新闻的链接路径代码是:
阴影部分是一条新闻的代码,则我们可以看到,新闻的链接路径代码是:
新闻热点






疑难解答