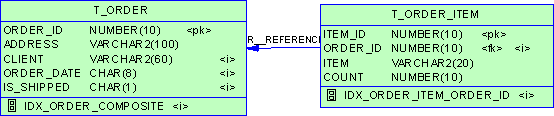
rudolf@TEST902>create index t_category_pname_ind on t (category,product_name) 2 nologging 3 tablespace indx 4 / Index created. rudolf@TEST902>analyze table t compute statistics 2 for table 3 for all indexes 4 for all indexed columns 5 / Table analyzed. rudolf@TEST902>select table_name,blocks, empty_blocks from user_tables where table_name = 'T'; TABLE_NAME BLOCKS EMPTY_BLOCKS ------------------------------ ---------- ------------ T 1039 113
为了便于讨论,我们先来看一下传统的做法:
rudolf@TEST902>select * from 2 ( select rownum rnm, a.* from 3 ( select * from t where category = &category_id 4 order by product_name 5 ) a 6 ) where rnm between &minrnm and &maxrnm 7
rudolf@TEST902>select * from 2 ( select rownum rnm, a.* from 3 ( select * from t where category = &category_id 4 order by category,product_name 5 ) a where rownum <= &maxrnm 6 ) where rnm >= &minrnm 7