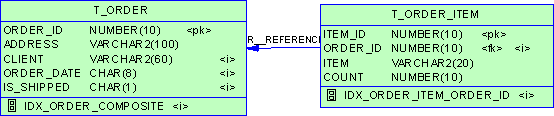
(1).SQL>select * from cz group by c1,c10,c20 having count(*) >1;C1 C10 C20---------- ---------- ---1 2 dsf2 3 che3 4 dff(2).SQL>select distinct * from cz;C1 C10 C20---------- ---------- ---1 2 dsf2 3 che3 4 dff(3).SQL>select * from cz a where rowid=(select max(rowid) from cz where c1=a.c1 and c10=a.c10 and c20=a.c20);C1 C10 C20---------- ---------- ---1 2 dsf2 3 che3 4 dff
SQL>delete cz where (c1,c10,c20) in (select c1,c10,c20 from cz group by c1,c10,c20 having count(*)>1) and rowid not in(select min(rowid) from cz group by c1,c10,c20 having count(*)>1);SQL>delete cz where rowid not in(select min(rowid) from cz group by c1,c10,c20);
(2).适用于有少量重复记录的情况(注重,对于有大量重复记录的情况,用以下语句效率会很低):
SQL>delete from cz a where a.rowid!=(select max(rowid) from cz b where a.c1=b.c1 and a.c10=b.c10 and a.c20=b.c20);SQL>delete from cz a where a.rowid<(select max(rowid) from cz b where a.c1=b.c1 and a.c10=b.c10 and a.c20=b.c20);SQL>delete from cz a where rowid <(select max(rowid) from cz where c1=a.c1 and c10=a.c10 and c20=a.c20);
(3).适用于有少量重复记录的情况(临时表法):
SQL>create table test as select distinct * from cz; (建一个临时表test用来存放重复的记录)SQL>truncate table cz; (清空cz表的数据,但保留cz表的结构)SQL>insert into cz select * from test; (再将临时表test里的内容反插回来)
(4).适用于有大量重复记录的情况(Exception into 子句法): 采用alter table 命令中的 Exception into 子句也可以确定出库表中重复的记录。这种方法稍微麻烦一些,为了使用“excepeion into ”子句,必须首先创建 EXCEPTIONS 表。创建该表的 SQL 脚本文件为 utlexcpt.sql 。对于win2000系统和 UNIX 系统, Oracle 存放该文件的位置稍有不同,在win2000系统下,该脚本文件存放在$ORACLE_HOMEOra90rdbmsadmin 目录下;而对于 UNIX 系统,该脚本文件存放在$ORACLE_HOME/rdbms/admin 目录下。 具体步骤如下:
SQL>@?/rdbms/admin/utlexcpt.sqlTable created.SQL>desc exceptionsName Null? Type----------------------------------------- ROW_ID ROWIDOWNER VARCHAR2(30)TABLE_NAME VARCHAR2(30)CONSTRAINT VARCHAR2(30)SQL>alter table cz add constraint cz_unique unique(c1,c10,c20) exceptions into exceptions; *ERROR at line 1:ORA-02299: cannot validate (TEST.CZ_UNIQUE) - duplicate keys foundSQL>create table dups as select * from cz where rowid in (select row_id from exceptions); Table created.SQL>select * from dups; C1 C10 C20---------- ---------- ---1 2 dsf1 2 dsf1 2 dsf1 2 dsf2 3 che1 2 dsf1 2 dsf1 2 dsf1 2 dsf2 3 che2 3 che2 3 che2 3 che3 4 dff3 4 dff3 4 dff16 rows selected.SQL>select row_id from exceptions;ROW_ID------------------AAAHD/AAIAAAADSAAAAAAHD/AAIAAAADSAABAAAHD/AAIAAAADSAACAAAHD/AAIAAAADSAAFAAAHD/AAIAAAADSAAHAAAHD/AAIAAAADSAAIAAAHD/AAIAAAADSAAGAAAHD/AAIAAAADSAADAAAHD/AAIAAAADSAAEAAAHD/AAIAAAADSAAJAAAHD/AAIAAAADSAAKAAAHD/AAIAAAADSAALAAAHD/AAIAAAADSAAMAAAHD/AAIAAAADSAANAAAHD/AAIAAAADSAAOAAAHD/AAIAAAADSAAP16 rows selected.SQL>delete from cz where rowid in ( select row_id from exceptions);16 rows deleted.SQL>insert into cz select distinct * from dups;3 rows created.SQL>select *from cz;C1 C10 C20---------- ---------- ---1 2 dsf2 3 che3 4 dff4 5 err5 3 dar6 1 wee7 2 zxc7 rows selected.