






| 函数名 | 返回值 |
| mysql_ f e t c h _ r o w ( ) | 一个数组,由数字索引访问其元素 |
| mysql_ f e t c h _ a r r a y ( ) | 一个数组,由数字索引或相关索引访问其元素 |
| mysql_ f e t c h _ o b j e c t ( ) | 一个对象,作为属性访问其元素 |
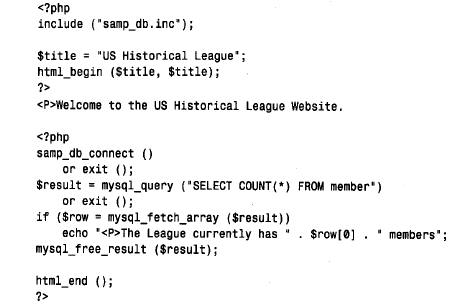
最基本的调用是mysql_ f e t c h _ r o w ( ),它返回结果集的下一行作为一个数组。数组的元素通过从0 到mysql_ n um _ f i e l d s ( )-1范围内的数字索引访问。下面的实例说明了如何在每一行都提取和打印值的简单循环中使用mysql_ f e t c h _ r o w ( ):
变量$row 是一个数组。可用$row[$i] 访问它, $ i在这里是数字列索引。如果熟悉php count() 函数,可以试着用它而不要用mysql_num_fields() 来确定每一行的列数。count() 只计算这个数组中已设置值的元素的数量, php 不是与null 列值相对应的元素设置值。count ( ) 对返回列数的度量是不可靠的,因为那不是它想要的。它还用于另外两种提取行的函数。
第二个提取行的函数mysql_fetch_array() 在表8 - 1中列出,它与mysql_fetch_row() 相类似,但是由数字索引和相关索引返回的数组元素都是可靠的。换句话说,可以通过数字或名称访问元素: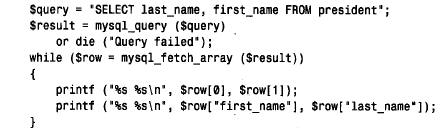
由mysql_fetch_array() 返回的信息是mysql_fetch_row() 返回的信息的扩展集。除此之外,两个函数之间的不同性能是可以忽略不记的,调用mysql_ f e t c h _ a r r a y ( )可以无特殊性能损耗。
第三个提取行的函数mysql_ f e t c h _ o b j e c t ( ),返回结果集的下一行作为对象,这意味着用$row->col_name 语法访问行的元素。例如,如果从president 表中检索last_name 和first_name 值,可以用$row->last_name 和$row->first_name 访问那些列:
在查询结果中测试null 值
可以使用isset() 函数测试select 查询返回的列值是否为null。例如,如果行包含在$row 数组中,那么如果$row[$i] 对应于null 值,则isset($row[$i]) 就为fa l s e,如果$row[$i] 为非null 值,则isset($row[$i]) 就为t r u e。相关的函数是e m p t y ( ),但是对于null 和空字符串,empty() 返回的结果都是一样的,因此作为null 值测试而言,这个函数是无用的。
如果查询包括计算的列怎么办?例如,发布一个作为表达式结果计算的返回值的查询:
select concat(first_name," ",lsat_last_name)from president
这样编写的查询不适于使用mysql_ f e t c h _ o b j e c t ( )。选择的列名本身就是表达式,它不是合法的属性名。然而,可以通过给列赋予一个别名来提供合法的名称。下面的查询将列的别名命名为f ul l _ name,如果用mysql_fetch_object() 提取结果,就允许它以$row->full_name 形式来访问:
select concat(first_name," ",lsat_last_name) as full_name from president
处理错误
php提供了三种处理错误的方法:
■ 用‘@’取消错误消息。可以对一些显示消息的函数使用‘ @’。当我们调用mysql_pconnect() 阻止来自于函数的错误消息不在发送到客户机的页面上出现时,就已经在做这一点了。
使用error_reporting() 函数。这个函数按下列级别将错误报告打开或者关闭:
| 错误级别 | 错误报告类型 |
| 1 | 正常函数错误 |
| 2 | 正常警告 |
| 4 | 分析程序错误 |
| 8 | 请注意 |
为了控制错误报告,可调用error_reporting() 函数,且参数为想要激活的级别的总和。关闭级别1和级别2警告应该完全能够取消来源于mysql的消息:
error_reporting(4+8);
你可能不想关闭有关分析错误的级别4警告,如果关掉了,可能要有一段艰难的时间用来调试它对脚本造成的改动!级别8警告常常被忽略,但有时它指出脚本中应该注意的问题,因此您可能也想把它激活。还有16和3 2错误级别,它们都来自于php 核心发动机,而非函数,因此通常情况下不必考虑它们。
使用mysql_error() 和mysql_er r n o ( )。这些函数报告了mysql服务器返回的错误信息。它们与相应的c api 调用相类似。mysql_error() 以字符串形式返回错误信息(如果不发生错误就返回空字符串)。mysql_errno() 返回一个错误数字(如果不发生错误就返回0)。两个函数都有指定与mysql服务器连接的连接标识符参数,在返回状态的连接上都返回最近调用的mysql函数的错误信息。连接标识符是可选的,如果缺失,就使用最近打开的连接。例如,可以这样报告mysql_query() 的错误:
mysql_error() 和mysql_errno() 的php 版本在一个重要方面与c api 中对应的部分不同。在c 中,即使试图连接服务器失败,也会得到错误信息。相反, php 调用直到连接建立成功,才返回有用的连接信息。换句话说,如果连接失败,就不能用mysql_error() 和mysql_er r n o ( ) 报告失败原因。如果要报告连接失败的特殊原因而不是普通原因,则必须做特殊的考虑。请参阅附录h“php api 参考”,其中详细介绍了如何去做。
当检测到错误时,本章的脚本打印了相当普通的错误信息,如“查询失败”。然而在开发脚本时,您会发现:加入一个mysql_error() 调用对帮您发现错误的特殊原因是很有用的。
引用问题
在php 中构造查询字符串时,知道引用问题是必要的,就像在c 和perl 中一样。虽然函数名在各种语言中是不同的,但处理引用问题的方法却是类似的。假设正在构造一个,将新的记录插入到表中的查询,可以在值的前后加上引号插入到字符串列中:
这里的问题是引用值的本身还包含着引号(“o’m a l l e y”),如果将查询发送到mysql服务器会导致语法错误。在c 中我们调用mysql_escape_string() 解决这个问题。在perl dbi脚本中则使用quote( ) 。php 有一个addslashes( ) 函数可以完成同样的事情。例如,调用a d d s l a s h e s(“o’ malley”)返回“o’ malley” 值。将前面的实例做如下编写来解决引用问题: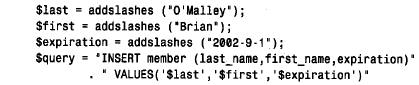
dbi quote( ) 方法是把前后的引号加到字符串中。addslashes( ) 则不是,因此我们仍需在查询字符串中要插入值的周围将那些引号显式地指定出来。
当编写信息出现在web 页面上时也将发生引用问题。如果正在编写一个将作为html 或u r l的部分出现的字符串,而且这个字符串包含html 或url 内部的特殊字符,最好将它编码。php 函数htmlspecialchars( ) 和urlencode( ) 可以做到这点,它们与c g i . p m
escapehtml( ) 和escape( ) 方法相类似。
新闻热点






疑难解答