首页| 新闻| 娱乐| 游戏| 科普| 文学| 编程| 系统| 数据库| 建站| 学院| 产品| 网管| 维修| 办公| 热点
显卡坏了会出现什么情况
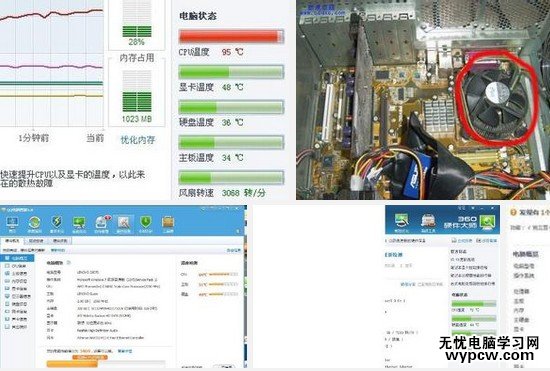
散热问题引发的CPU高占用率问
内存条松动导致的故障现象及解决办法
校园甜美的背影,洋溢着青春烂漫的回忆
芭蕾舞蹈表演,真实美到极致
游览三河古镇景点:望月阁、古民居、一人巷
大蜀山森林公园美景
肉食主义者的最爱美食烤肉图片
夏日甜心草莓美食图片
人逢知己千杯少,喝酒搞笑图集
搞笑试卷,学生恶搞答题
新闻热点
疑难解答
图片精选
linux系统安装出错提示this kernel
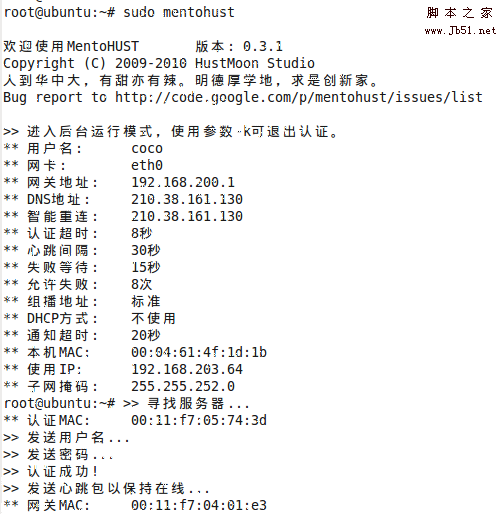
Linux下Dr.com(802.1x)拨号上网完
Linux中 如何查看Ubuntu内存信息?
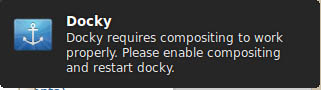
Linux下如何修复Lubuntu中的Docky
网友关注