接下来准备用糗百做一个爬虫的小例子。
但是在这之前,先详细的整理一下Python中的正则表达式的相关内容。
正则表达式在Python爬虫中的作用就像是老师点名时用的花名册一样,是必不可少的神兵利器。
一、 正则表达式基础
1.1.概念介绍
正则表达式是用于处理字符串的强大工具,它并不是Python的一部分。
其他编程语言中也有正则表达式的概念,区别只在于不同的编程语言实现支持的语法数量不同。
它拥有自己独特的语法以及一个独立的处理引擎,在提供了正则表达式的语言里,正则表达式的语法都是一样的。
下图展示了使用正则表达式进行匹配的流程:
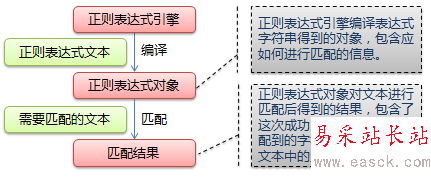
正则表达式的大致匹配过程是:
1.依次拿出表达式和文本中的字符比较,
2.如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。
3.如果表达式中有量词或边界,这个过程会稍微有一些不同。
下图列出了Python支持的正则表达式元字符和语法:

1.2. 数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。
贪婪模式,总是尝试匹配尽可能多的字符;
非贪婪模式则相反,总是尝试匹配尽可能少的字符。
Python里数量词默认是贪婪的。
例如:正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。
而如果使用非贪婪的数量词"ab*?",将找到"a"。
1.3. 反斜杠的问题
与大多数编程语言相同,正则表达式里使用"/"作为转义字符,这就可能造成反斜杠困扰。
假如你需要匹配文本中的字符"/",那么使用编程语言表示的正则表达式里将需要4个反斜杠"////":
第一个和第三个用于在编程语言里将第二个和第四个转义成反斜杠,
转换成两个反斜杠//后再在正则表达式里转义成一个反斜杠用来匹配反斜杠/。
这样显然是非常麻烦的。
Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"//"表示。
同样,匹配一个数字的"//d"可以写成r"/d"。
有了原生字符串,妈妈再也不用担心我的反斜杠问题~
二、 介绍re模块
2.1. Compile
Python通过re模块提供对正则表达式的支持。
使用re的一般步骤是:
Step1:先将正则表达式的字符串形式编译为Pattern实例。
Step2:然后使用Pattern实例处理文本并获得匹配结果(一个Match实例)。
Step3:最后使用Match实例获得信息,进行其他的操作。
我们新建一个re01.py来试验一下re的应用:
新闻热点






疑难解答













