在开始后面的内容之前,先来解释一下urllib2中的两个个方法:info / geturl
urlopen返回的应答对象response(或者HTTPError实例)有两个很有用的方法info()和geturl()
1.geturl():
这个返回获取的真实的URL,这个很有用,因为urlopen(或者opener对象使用的)或许会有重定向。获取的URL或许跟请求URL不同。
以人人中的一个超级链接为例,
我们建一个urllib2_test10.py来比较一下原始URL和重定向的链接:
代码如下:
from urllib2 import Request, urlopen, URLError, HTTPError
old_url = 'http://rrurl.cn/b1UZuP'
req = Request(old_url)
response = urlopen(req)
print 'Old url :' + old_url
print 'Real url :' + response.geturl()
运行之后可以看到真正的链接指向的网址:

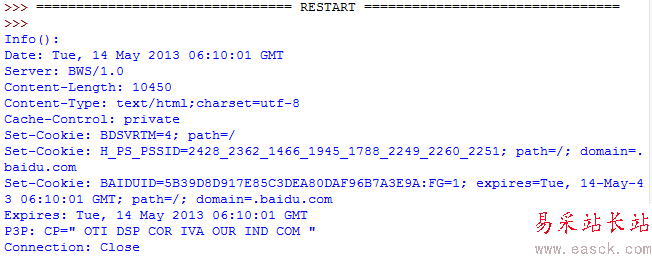
2.info():
这个返回对象的字典对象,该字典描述了获取的页面情况。通常是服务器发送的特定头headers。目前是httplib.HTTPMessage 实例。
经典的headers包含"Content-length","Content-type",和其他内容。
我们建一个urllib2_test11.py来测试一下info的应用:
代码如下:
from urllib2 import Request, urlopen, URLError, HTTPError
old_url = 'http://www.baidu.com'
req = Request(old_url)
response = urlopen(req)
print 'Info():'
print response.info()
运行的结果如下,可以看到页面的相关信息:
下面来说一说urllib2中的两个重要概念:Openers和Handlers。
1.Openers:
当你获取一个URL你使用一个opener(一个urllib2.OpenerDirector的实例)。
正常情况下,我们使用默认opener:通过urlopen。
但你能够创建个性的openers。
2.Handles:
Openers使用处理器handlers,所有的“繁重”工作由handlers处理。
每个handlers知道如何通过特定协议打开URLs,或者如何处理URL打开时的各个方面。
例如HTTP重定向或者HTTP cookies。
如果你希望用特定处理器获取URLs你会想创建一个openers,例如获取一个能处理cookie的opener,或者获取一个不重定向的opener。
要创建一个 opener,可以实例化一个OpenerDirector,
然后调用.add_handler(some_handler_instance)。
同样,可以使用build_opener,这是一个更加方便的函数,用来创建opener对象,他只需要一次函数调用。
build_opener默认添加几个处理器,但提供快捷的方法来添加或更新默认处理器。
其他的处理器handlers你或许会希望处理代理,验证,和其他常用但有点特殊的情况。
install_opener 用来创建(全局)默认opener。这个表示调用urlopen将使用你安装的opener。
新闻热点






疑难解答













