Scrapy
Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取。但是当我们要爬取的页面非常多的时候,单个主机的处理能力就不能满足我们的需求了(无论是处理速度还是网络请求的并发数),这时候分布式爬虫的优势就显现出来。
而Scrapy-Redis则是一个基于Redis的Scrapy分布式组件。它利用Redis对用于爬取的请求(Requests)进行存储和调度(Schedule),并对爬取产生的项目(items)存储以供后续处理使用。scrapy-redi重写了scrapy一些比较关键的代码,将scrapy变成一个可以在多个主机上同时运行的分布式爬虫。
原生的Scrapy的架构是这样子的:
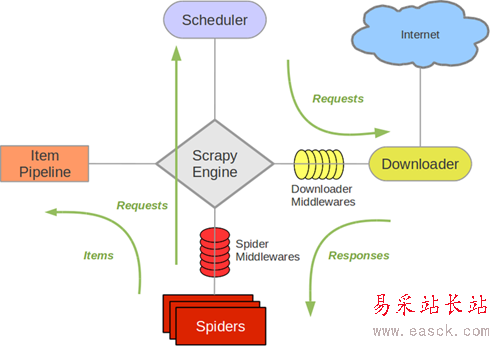
加上了Scrapy-Redis之后的架构变成了:
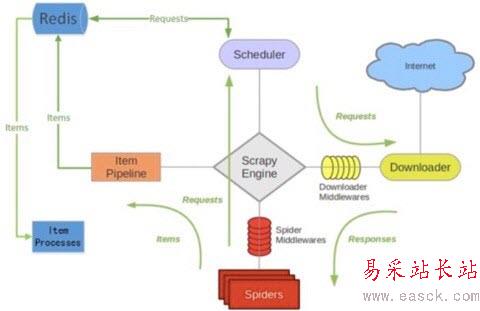
scrapy-redis的官方文档写的比较简洁,没有提及其运行原理,所以如果想全面的理解分布式爬虫的运行原理,还是得看scrapy-redis的源代码才行,不过scrapy-redis的源代码很少,也比较好懂,很快就能看完。
scrapy-redis工程的主体还是是redis和scrapy两个库,工程本身实现的东西不是很多,这个工程就像胶水一样,把这两个插件粘结了起来。
scrapy-redis提供了哪些组件?
scrapy-redis所实现的两种分布式:爬虫分布式以及item处理分布式。分别是由模块scheduler和模块pipelines实现。
connection.py
负责根据setting中配置实例化redis连接。被dupefilter和scheduler调用,总之涉及到redis存取的都要使用到这个模块。
import redisimport sixfrom scrapy.utils.misc import load_objectDEFAULT_REDIS_CLS = redis.StrictRedis# Sane connection defaults.DEFAULT_PARAMS = { 'socket_timeout': 30, 'socket_connect_timeout': 30, 'retry_on_timeout': True,}# Shortcut maps 'setting name' -> 'parmater name'.SETTINGS_PARAMS_MAP = { 'REDIS_URL': 'url', 'REDIS_HOST': 'host', 'REDIS_PORT': 'port',}def get_redis_from_settings(settings): """Returns a redis client instance from given Scrapy settings object. This function uses ``get_client`` to instantiate the client and uses ``DEFAULT_PARAMS`` global as defaults values for the parameters. You can override them using the ``REDIS_PARAMS`` setting. Parameters ---------- settings : Settings A scrapy settings object. See the supported settings below. Returns ------- server Redis client instance. Other Parameters ---------------- REDIS_URL : str, optional Server connection URL. REDIS_HOST : str, optional Server host. REDIS_PORT : str, optional Server port. REDIS_PARAMS : dict, optional Additional client parameters. """ params = DEFAULT_PARAMS.copy() params.update(settings.getdict('REDIS_PARAMS')) # XXX: Deprecate REDIS_* settings. for source, dest in SETTINGS_PARAMS_MAP.items(): val = settings.get(source) if val: params[dest] = val # Allow ``redis_cls`` to be a path to a class. if isinstance(params.get('redis_cls'), six.string_types): params['redis_cls'] = load_object(params['redis_cls']) return get_redis(**params)# Backwards compatible alias.from_settings = get_redis_from_settingsdef get_redis(**kwargs): """Returns a redis client instance. Parameters ---------- redis_cls : class, optional Defaults to ``redis.StrictRedis``. url : str, optional If given, ``redis_cls.from_url`` is used to instantiate the class. **kwargs Extra parameters to be passed to the ``redis_cls`` class. Returns ------- server Redis client instance. """ redis_cls = kwargs.pop('redis_cls', DEFAULT_REDIS_CLS) url = kwargs.pop('url', None) if url: return redis_cls.from_url(url, **kwargs) else: return redis_cls(**kwargs)
新闻热点






疑难解答













