这是一款提取网站数据的开源工具。Scrapy框架用Python开发而成,它使抓取工作又快又简单,且可扩展。我们已经在virtual box中创建一台虚拟机(VM)并且在上面安装了Ubuntu 14.04 LTS。
安装 Scrapy
Scrapy依赖于Python、开发库和pip。Python最新的版本已经在Ubuntu上预装了。因此我们在安装Scrapy之前只需安装pip和python开发库就可以了。
pip是作为python包索引器easy_install的替代品,用于安装和管理Python包。pip包的安装可见图 1。
sudo apt-get install python-pip
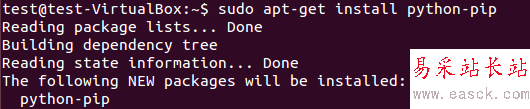
图:1 pip安装
我们必须要用下面的命令安装python开发库。如果包没有安装那么就会在安装scrapy框架的时候报关于python.h头文件的错误。
sudo apt-get install python-dev

图:2 Python 开发库
scrapy框架既可从deb包安装也可以从源码安装。在图3中我们用pip(Python 包管理器)安装了deb包了。
sudo pip install scrapy
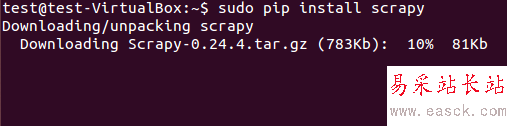
图:3 Scrapy 安装
图4中scrapy的成功安装需要一些时间。

图:4 成功安装Scrapy框架
使用scrapy框架提取数据
基础教程
我们将用scrapy从fatwallet.com上提取商店名称(卖卡的店)。首先,我们使用下面的命令新建一个scrapy项目“store name”, 见图5。
$sudo scrapy startproject store_name
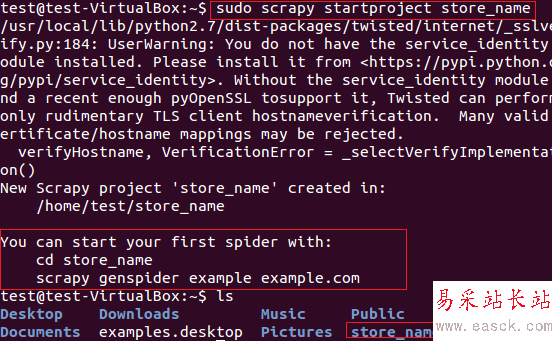
图:5 Scrapy框架新建项目
上面的命令在当前路径创建了一个“store_name”的目录。项目主目录下包含的文件/文件夹见图6。
$sudo ls –lR store_name
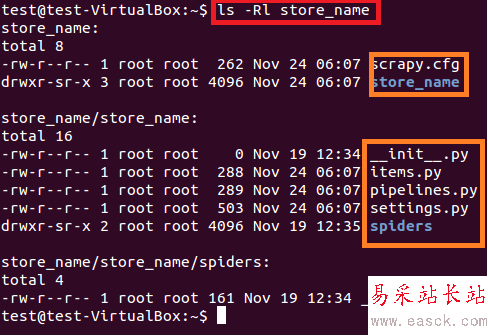
图:6 store_name项目的内容
每个文件/文件夹的概要如下:
scrapy.cfg 是项目配置文件 store_name/ 主目录下的另一个文件夹。 这个目录包含了项目的python代码 store_name/items.py 包含了将由蜘蛛爬取的项目 store_name/pipelines.py 是管道文件 store_name/settings.py 是项目的配置文件 store_name/spiders/, 包含了用于爬取的蜘蛛新闻热点






疑难解答













