本文介绍一个将911袭击及后续影响相关新闻文章的主题可视化的项目。我将介绍我的出发点,实现的技术细节和我对一些结果的思考。
简介
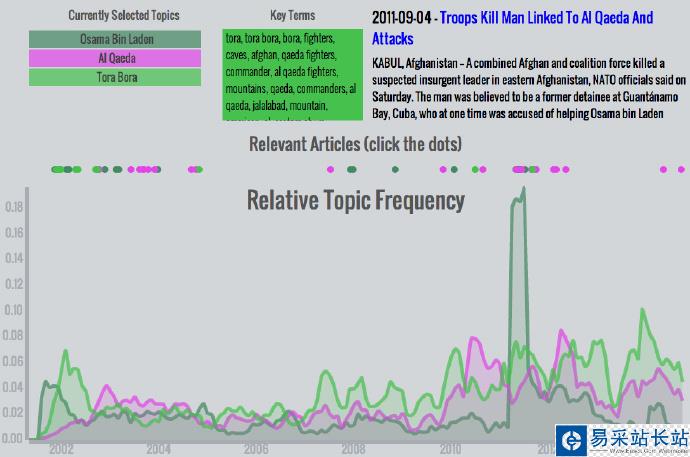
近代美国历史上再没有比911袭击影响更深远的事件了,它的影响在未来还会持续。从事件发生到现在,成千上万主题各异的文章付梓。我们怎样能利用数据科学的工具来探索这些主题,并且追踪它们随着时间的变化呢?
灵感
首先提出这个问题的是一家叫做Local Projects的公司,有人委任它们为纽约的国家911博物馆设置一个展览。他们的展览,Timescape,将事件的主题和文章可视化之后投影到博物馆的一面墙上。不幸的是,由于考虑到官僚主义的干预和现代人的三分钟热度,这个展览只能展现很多主题,快速循环播放。Timescape的设计给了我启发,但是我想试着更深入、更有交互性,让每个能接入互联网的人都能在空闲时观看。
这个问题的关键是怎么讲故事。每篇文章都有不同的讲故事角度,但是有线索通过词句将它们联系到一起。”Osama bin Laden”、 “Guantanamo Bay”、”Freedom”,还有更多词汇组成了我模型的砖瓦。
获取数据
所有来源当中,没有一个比纽约时报更适合讲述911的故事了。他们还有一个神奇的API,允许在数据库中查询关于某一主题的全部文章。我用这个API和其他一些Python网络爬虫以及NLP工具构建了我的数据集。
爬取过程是如下这样的:
调用API查询新闻的元数据,包括每篇文章的URL。 给每个URL发送GET请求,找到HTML中的正文文本,提取出来。 清理文章文本,去除停用词和标点我写了一个Python脚本自动做这些事,并能够构建一个有成千上万文章的数据集。也许这个过程中最有挑战性的部分是写一个从HTML文档里提取正文的函数。近几十年来,纽约时报不时也更改了他们HTML文档的结构,所以这个抽取函数取决于笨重的嵌套条件语句:
# s is a BeautifulSoup object containing the HTML of the pageif s.find('p', {'itemprop': 'articleBody'}) is not None: paragraphs = s.findAll('p', {'itemprop': 'articleBody'}) story = ' '.join([p.text for p in paragraphs])elif s.find('nyt_text'): story = s.find('nyt_text').textelif s.find('div', {'id': 'mod-a-body-first-para'}): story = s.find('div', {'id': 'mod-a-body-first-para'}).text story += s.find('div', {'id': 'mod-a-body-after-first-para'}).textelse: if s.find('p', {'class': 'story-body-text'}) is not None: paragraphs = s.findAll('p', {'class': 'story-body-text'}) story = ' '.join([p.text for p in paragraphs]) else: story = ''
新闻热点






疑难解答













