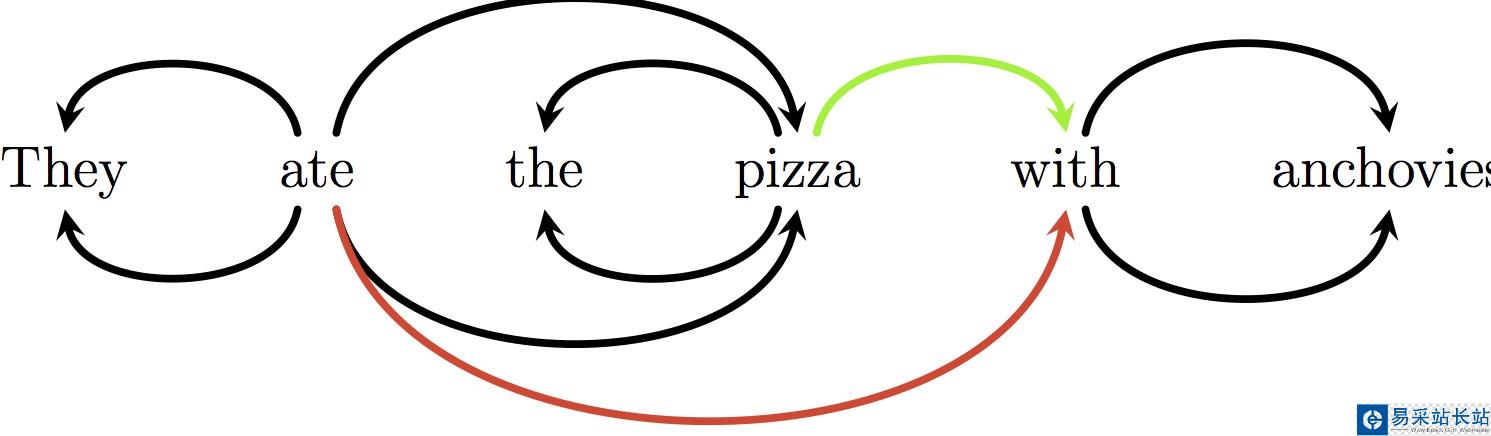
语法分析器描述了一个句子的语法结构,用来帮助其他的应用进行推理。自然语言引入了很多意外的歧义,以我们对世界的了解可以迅速地发现这些歧义。举一个我很喜欢的例子:

正确的解析是连接“with”和“pizza”,而错误的解析将“with”和“eat”联系在了一起:
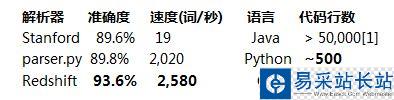
过去的一些年,自然语言处理(NLP)社区在语法分析方面取得了很大的进展。现在,小小的 Python 实现可能比广泛应用的 Stanford 解析器表现得更出色。
文章剩下的部分首先设置了问题,接着带你了解为此准备的简洁实现。parser.py 代码中的前 200 行描述了词性的标注者和学习者(这里)。除非你非常熟悉 NLP 方向的研究,否则在研究这篇文章之前至少应该略读。
Cython 系统和 Redshift 是为我目前的研究而写的。和麦考瑞大学的合同到期后,我计划六月份对它进行改进,用于一般用途。目前的版本托管在 GitHub 上。
问题描述
在你的手机中输入这样一条指令是非常友善的:
Set volume to zero when I'm in a meeting, unless John's school calls.
接着进行适当的策略配置。在 Android 系统上,你可以应用 Tasker 做这样的事情,而 NL 接口会更好一些。接收可以编辑的语义表示,你就能了解到它认为你表达的意思,并且可以修正他的想法,这样是特别友善的。
这项工作有很多问题需要解决,但一些种类的句法形态绝对是必要的。我们需要知道:
Unless John's school calls, when I'm in a meeting, set volume to zero
是解析指令的又一种方式,而
Unless John's school, call when I'm in a meeting
表达了完全不同的意思。
依赖解析器返回一个单词与单词间的关系图,使推理变得更容易。关系图是树形结构,有向边,每个节点(单词)有且仅有一个入弧(头部依赖)。
用法示例:
>>> parser = parser.Parser()>>> tokens = "Set the volume to zero when I 'm in a meeting unless John 's school calls".split()>>> tags, heads = parser.parse(tokens)>>> heads[-1, 2, 0, 0, 3, 0, 7, 5, 7, 10, 8, 0, 13, 15, 15, 11]>>> for i, h in enumerate(heads):... head = tokens[heads[h]] if h >= 1 else 'None'... print(tokens[i] + ' <-- ' + head])Set <-- Nonethe <-- volumevolume <-- Setto <-- Setzero <-- towhen <-- SetI <-- 'm'm <-- whenin <-- 'ma <-- meetingmeeting <-- inunless <-- SetJohn <-- 's's <-- callsschool <-- callscalls <-- unless
新闻热点






疑难解答













