python解析网页,无出BeautifulSoup左右,此是序言
安装
BeautifulSoup4以后的安装需要用eazy_install,如果不需要最新的功能,安装版本3就够了,千万别以为老版本就怎么怎么不好,想当初也是千万人在用的啊。安装很简单
代码如下:
$ wget "http://www.crummy.com/software/BeautifulSoup/download/3.x/BeautifulSoup-3.2.1.tar.gz"
$ tar zxvf BeautifulSoup-3.2.1.tar.gz
然后把里面的BeautifulSoup.py这个文件放到你python安装目录下的site-packages目录下
site-packages是存放Python第三方包的地方,至于这个目录在什么地方呢,每个系统不一样,可以用下面的方式找一下,基本上都能找到
代码如下:
$ sudo find / -name "site-packages" -maxdepth 5 -type d
$ find ~ -name "site-packages" -maxdepth 5
当然如果没有root权限就查找当前用户的根目录
代码如下:
$ find ~ -name "site-packages" -maxdepth 5 -type d
如果你用的是Mac,哈哈,你有福了,我可以直接告诉你,Mac的这个目录在/Library/Python/下,这个下面可能会有多个版本的目录,没关系,放在最新的一个版本下的site-packages就行了。使用之前先import一下
代码如下:
from BeautifulSoup import BeautifulSoup
使用
在使用之前我们先来看一个实例
现在给你这样一个页面
代码如下:
http://movie.douban.com/tag/%E5%96%9C%E5%89%A7
它是豆瓣电影分类下的喜剧电影,如果让你找出里面评分最高的100部,该怎么做呢
好了,我先晒一下我做的,鉴于本人在CSS方面处于小白阶段以及天生没有美术细菌,界面做的也就将就能看下,别吐
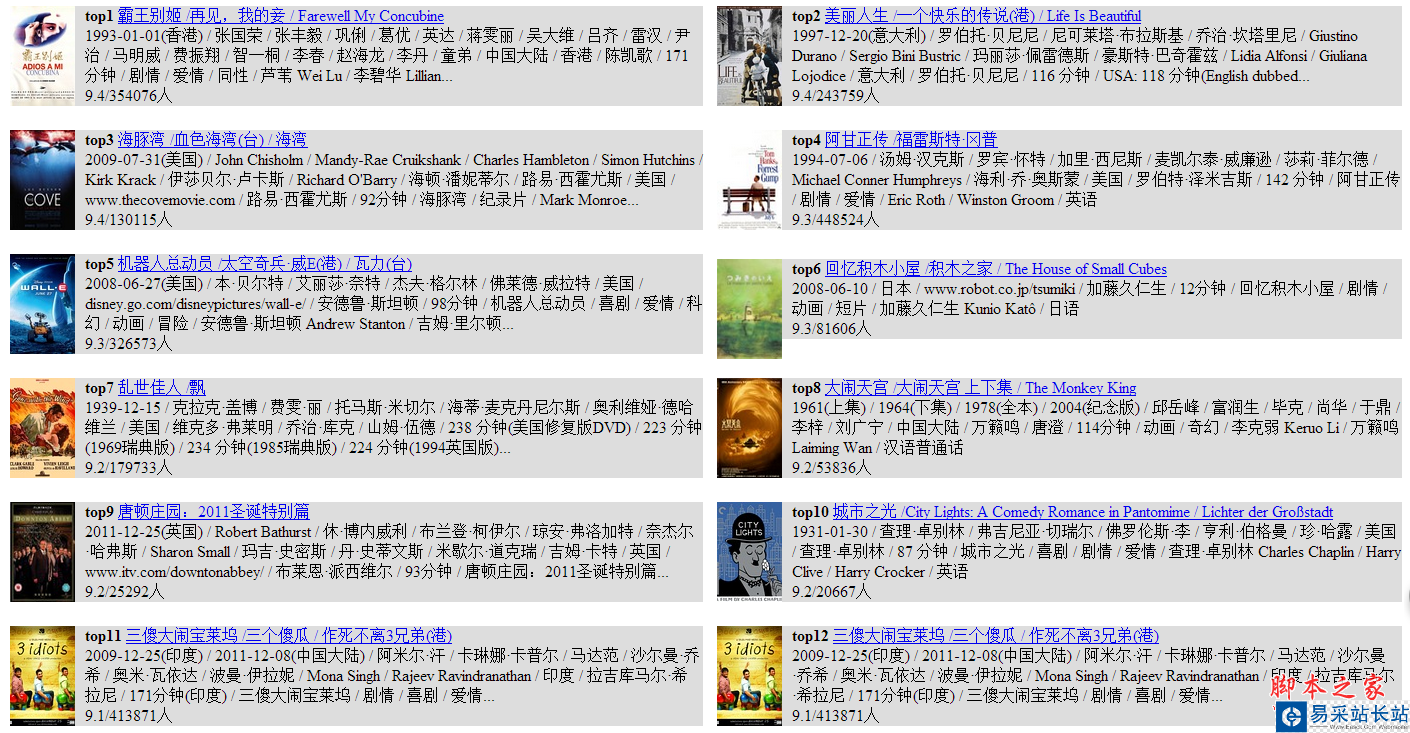
接下来我们开始学习BeautifulSoup的一些基本方法,做出上面那个页面就易如反掌了
鉴于豆瓣那个页面比较复杂,我们先以一个简单样例来举例,假设我们处理如下的网页代码
代码如下:
<html>
<head><title>Page title</title></head>
<body>
<p id="firstpara" align="center">
This is paragraph
<b>
one
</b>
.
</p>
<p id="secondpara" align="blah">
This is paragraph
<b>
two
</b>
新闻热点






疑难解答













