
集智导读:
本文会为大家展示机器学习专家 Mike Shi 如何用 50 行 Python 代码创建一个 AI,使用增强学习技术,玩耍一个保持杆子平衡的小游戏。所用环境为标准的 OpenAI Gym,只使用 Numpy 来创建 agent。
各位看官好,我(作者 Mike Shi——译者注)将在本文教大家如何用 50 行 Python 代码,教会 AI 玩一个简单的平衡游戏。我们会用到标准的 OpenAI Gym 作为测试环境,仅用 Numpy 创建我们的 AI,别的不用。
这个小游戏就是经典的 Cart Pole 任务,它是 OpenAI Gym 中一个经典的传统增强学习任务。游戏玩法如下方动图所示,就是尽力保持这根杆子始终竖直向上。杆子由于重力原因,会出现倾斜,到了一定程度就会倒下,AI 的任务就是在此时向左或向右移动杆子,不让它倒下。这就跟我们在手指尖上树立一支铅笔玩“金鸡独立”一样,只不过我们这里是个一维的简单游戏(但是还是很有挑战性的)。
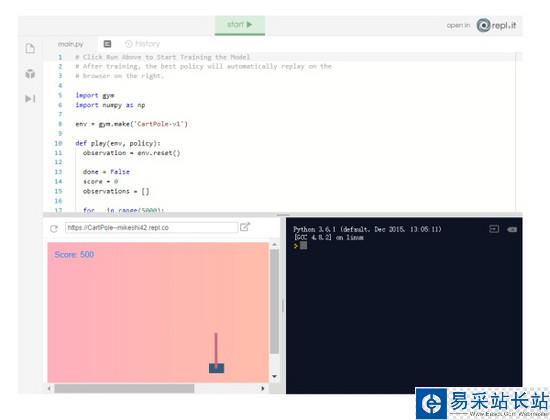
你可能好奇最终实现怎样的结果,可以在repl.it 上查看 demo:
https:// repl.it/@MikeShi42/Cart Pole
增强学习速览
如果这是你第一次接触机器学习或增强学习,别担心,我下面介绍一些基础知识,这样你就可以了解本文使用的术语了:)。如果已经熟悉了,大可跳过这部分,直接看看编写 AI 的部分。
增强学习(RL)是一个研究领域:教 agent(我们的算法/机器)执行某些任务/动作,但明确告诉它该怎样做。把它想象成一个婴儿,以随机的方式伸腿,如果宝宝偶然间走运站立起来,我们会给它一个糖果作为奖励。同样,Agent 的目标就是在其生命周期内得到最多的奖励,而且我们会根据是否和要完成的任务相符来决定奖励的类型。对于婴儿站立的例子,站立时奖励 1,否则为0。
增强学习 agent 的一个著名例子是 AlphaGo,其中的 agent 已经学会了如何玩围棋以最大化其奖励(赢得游戏)。在本教程中,我们将创建一个 agent,或者说 AI,可以向左或向右移动小车,让杆子保持平衡。
状态
状态是目前游戏的样子。我们通常处理游戏的多种数字表示。在乒乓球比赛中,它可能是每个球拍的垂直位置和 x,y 坐标和球的速度。在我们这个游戏中,我们的状态由 4 个数字组成:底部小车的位置,小车的速度,杆的位置(以角度表示)和杆的角速度。这 4 个数字都是给定的数组(或向量)。这个很重要,理解状态是一个数字数组意味着我们可以对它进行一些数学运算来决定我们根据状态采取什么行动。
新闻热点






疑难解答













