先来看一下功能实现,代码如下:
from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.common.keys import Keysfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.support.wait import WebDriverWait#声明浏览器对象browser = webdriver.Chrome()try: browser.get('https:www.baidu.com') input = browser.find_element_by_id('kw') input.send_keys('Python') input.send_keys(Keys.ENTER) wait = WebDriverWait(browser,10) wait.until(EC.presence_of_element_located((By.ID,'content_left'))) print(browser.current_url) print(browser.get_cookies()) print(browser.page_source)finally: browser.close()可以看到打开了百度网站,查询了“Python”并且输出了当前的url,cookies还有网页源代码。
下面再来介绍详细功能。
1、声明浏览器对象。
browser = webdriver.Chrome()browser = webdriver.Firefox()
浏览器的对象初始化,并将其赋值给browser对象。
2.以淘宝为例,请求网页。
browser = webdriver.Chrome()browser.get('https://www.taobao.com')print(browser.page_source)browser.close()可以看到输出了淘宝的源码,随后关闭。
3.查找节点
单个节点
提取搜索框这个节点
检查搜索框如下:
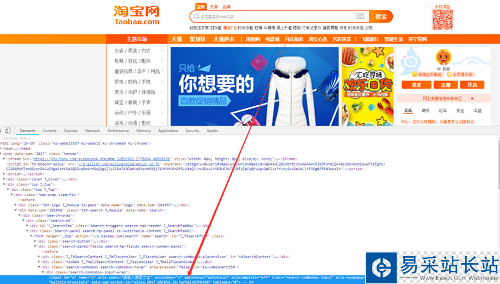
查找搜索框:
browser = webdriver.Chrome()browser.get('https://www.taobao.com')# 通过id查找input_first = browser.find_element_by_id('q')# 通过css查找input_second = browser.find_element_by_css_selector('#q')# 通过xpath查找input_third = browser.find_element_by_xpath('//*[@id="q"]')print(input_first,input_second,input_third)browser.close()# 查找单个节点的方法find_element_by_idfind_element_by_namefind_element_by_xpathfind_element_by_link_textfind_element_by_partial_link_textfind_element_by_tag_namefind_element_by_class_namefind_element_by_css_selector
通用方法查找:
browser = webdriver.Chrome()browser.get('https://www.taobao.com')input_first = browser.find_element(By.ID,'q')print(input_first)browser.close() find_element()里面需要两个参数,查找方式By和值, 例如:find_element(By.ID,'q') 通过查找ID的当时,查找id为q。多个节点:
例如左侧的导航条所有条目:
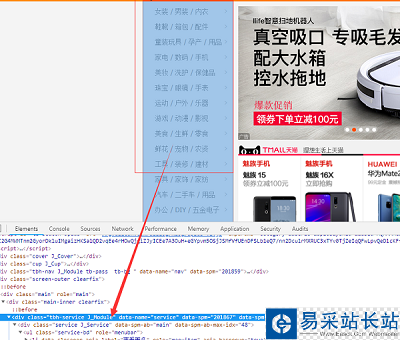
browser = webdriver.Chrome()browser.get('https://www.taobao.com')lis = browser.find_elements_by_css_selector('.service-bd li')print(lis)browser.close()获取多个节点的方法:
新闻热点






疑难解答













