Python2的字符串有两种:str和Unicode,Python3的字符串也有两种:str和Bytes。Python2的str相当于Python3的Bytes,而Unicode相当于Python3的Bytes。
Python2里面的str和Unicode是可以混用的,在都是英文字母的时候str和unicode没有区别。
而Python3严格区分文本(str)和二进制数据(Bytes),文本总是Unicode,用str类型,二进制数据则用Bytes类型表示,这样严格的限制也让我们对如何使用它们有了清晰的认识,这是很棒的。
Python2 和 Python3 的区别
通过以下代码我们认识以下Python2和Python3的字符串混用情况:
# Python2中:In [1]: 'a' == u'a'Out[1]: TrueIn [2]: 'a' in u'a'Out[2]: TrueIn [3]: '编程' == u'编程'/usr/local/bin/ipython:1: UnicodeWarning: Unicode equal comparison failed to convert both arguments to Unicode - interpreting them as being unequal#!/usr/bin/pythonOut[3]: FalseIn [4]: '编程' in u'编程'---------------------------------------------------------------------------UnicodeDecodeError Traceback (most recent call last)<ipython-input-4-7b677a923254> in <module>()----> 1 '编程' in u'编程'UnicodeDecodeError: 'ascii' codec can't decode byte 0xe7 in position 0: ordinal not in range(128)# Python3中:In [1]: 'a' == b'a'Out[1]: FalseIn [2]: 'a' in b'a'---------------------------------------------------------------------------TypeError Traceback (most recent call last)<ipython-input-10-ca907fd8856f> in <module>()----> 1 'a' in b'a'TypeError: a bytes-like object is required, not 'str'
以上代码可以看到,Python2中str和Unicode在都是ASCII码时混用没区别,因为Unicode的ASCII区域的值跟str的ASCII是一样的;而对应非ASCII区域(比如中文),二者又不一样了。
可以看到Python2抛出了Unicode Decode Error的异常,相信这也是很多人处理文本时遇到过的错误;‘编程'在str类型时长度是6,而在Unicode时是2。不同字符的不同表现,让Python2的str和Unicode显得扑朔迷离。
在Python3中,严格区分了str和Bytes,不同类型之间操作就会抛出Type Error的异常。
上面用示例阐述了Python2和Python3中字符串的不同,下面主要讲Python3中的字符串。
str和bytes之间的转换
一图胜千言:
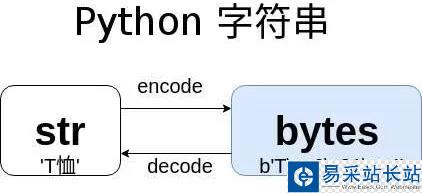
str和bytes的相互转换
str.encode(‘encoding') -> bytesbytes.decode(‘encoding') -> str
Encoding指的是具体的编码规则的名称,对于中文来说,它可以是这些值: ‘utf-8', ‘gb2312', ‘gbk', ‘big5' 等等。
不知道你有没有注意到上图中str矩形要比Bytes矩形短,表示同样的内容,str的长度要小于或等于Bytes的长度,你可以考虑一下原因(参考Unicode、UTF-8的编码规则)。
新闻热点






疑难解答













