点击率预估模型
0.前言
本篇是一个基础机器学习入门篇文章,帮助我们熟悉机器学习中的神经网络结构与使用。
日常中习惯于使用Python各种成熟的机器学习工具包,例如sklearn、TensorFlow等等,来快速搭建各种各样的机器学习模型来解决各种业务问题。
本文将从零开始,仅仅利用基础的numpy库,使用Python实现一个最简单的神经网络(或者说是简易的LR,因为LR就是一个单层的神经网络),解决一个点击率预估的问题。
1.假设一个业务场景
声明:为了简单起见,下面的一切设定从简….
定义需要解决的问题:
老板:小李,这台机器上有一批微博的点击日志数据,你拿去分析一下,然后搞点击率预测啥的…
是的,就是预测一篇微博是否会被用户点击(被点击的概率)…..预测未来,貌似很神奇的样子!
热门微博
简单的介绍一下加深的业务数据
每一条微博数据有由三部分构成: {微博id, 微博特征X, 微博点击标志Y}
微博特征X有三个维度:
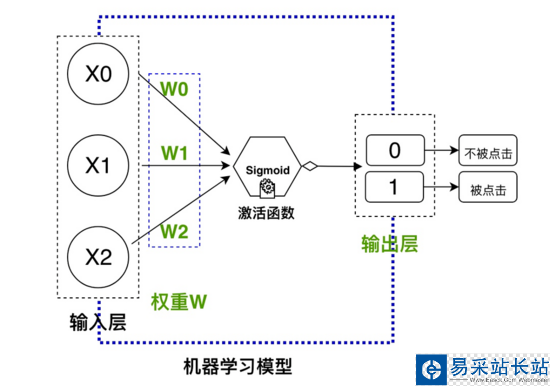
X={x0="该微博有娱乐明星”,x1="该微博有图”,x2="该微博有表情”}
微博是否被点击过的标志Y:
Y={y0=“点击”, y1=“未点击”}
数据有了,接下来需要设计一个模型,把数据输入进去进行训练之后,在预测阶段,只需要输入{微博id,微博特征X},模型就会输出每一个微博id会被点击的概率。
2.任务分析:
这是一个有监督的机器学习任务
对于有监督的机器学习任务,可以简单的分为分类与回归问题,这里我们简单的想实现预测一条微博是否会被用户点击,预测目标是一个二值类别:点击,或者不点击,显然可以当做一个分类问题。
所以,我们需要搭建一个分类模型(点击率预测模型),这也就决定我们需要构建一个有监督学习的训练数据集。
模型的选择
选择最简单神经网络模型,人工神经网络有几种不同类型的神经网络,比如前馈神经网络、卷积神经网络及递归神经网络等。本文将以简单的前馈或感知神经网络为例,这种类型的人工神经网络是直接从前到后传递数据的,简称前向传播过程。
3.数据准备:
整体的流程:
数据预处理(数值化编码)——>特征筛选——>选择模型(前馈神经网络)——>训练模型——>模型预测
新闻热点






疑难解答













