前言
Splash是一个javascript渲染服务。它是一个带有HTTP API的轻量级Web浏览器,使用Twisted和QT5在Python 3中实现。QT反应器用于使服务完全异步,允许通过QT主循环利用webkit并发。
一些Splash功能:
并行处理多个网页 获取HTML源代码或截取屏幕截图 关闭图像或使用Adblock Plus规则使渲染更快 在页面上下文中执行自定义JavaScript 可通过Lua脚本来控制页面的渲染过程 在Splash-Jupyter 笔记本中开发Splash Lua脚本。 以HAR格式获取详细的渲染信息Scrapy-Splash的安装分为两部分,一个是Splash服务的安装,具体通过Docker来安装服务,运行服务会启动一个Splash服务,通过它的接口来实现JavaScript页面的加载;另外一个是Scrapy-Splash的Python库的安装,安装后就可在Scrapy中使用Splash服务了,下面我们分三部份来安装:
(1)安装Docker
#安装所需要的包:yum install -y yum-utils device-mapper-persistent-data lvm2#设置稳定存储库:yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo#开始安装DOCKER CE:yum install docker-ce#启动dockers:systemctl start docker#测试安装是否正确:docker run hello-world
(2)安装splash服务
通过Docker安装Scrapinghub/splash镜像,然后启动容器,创建splash服务
docker pull scrapinghub/splashdocker run -d -p 8050:8050 scrapinghub/splash#通过浏览器访问8050端口验证安装是否成功
(3)Python包Scrapy-Splash安装
pip3 install scrapy-splash
运行splash服务后,通过web页面访问服务的8050端口如:http://localhost:8050即可看到其web页面,如下图:
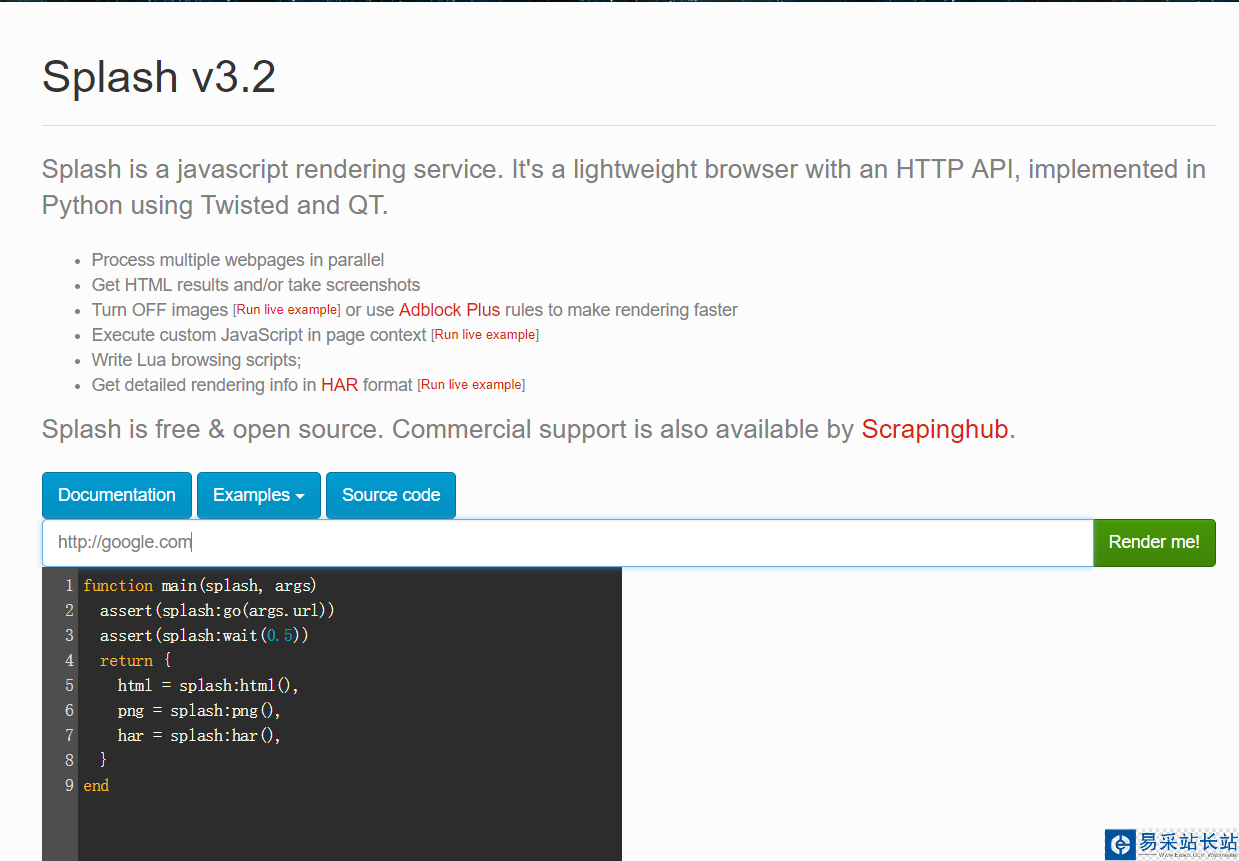
上面有个输入框,默认是http://google.com,我们可以换成想要渲染的网页如:https://www.baidu.com然后点击Render me按钮开始渲染,页面返回结果包括渲染截图、HAR加载统计数据、网页源代码:
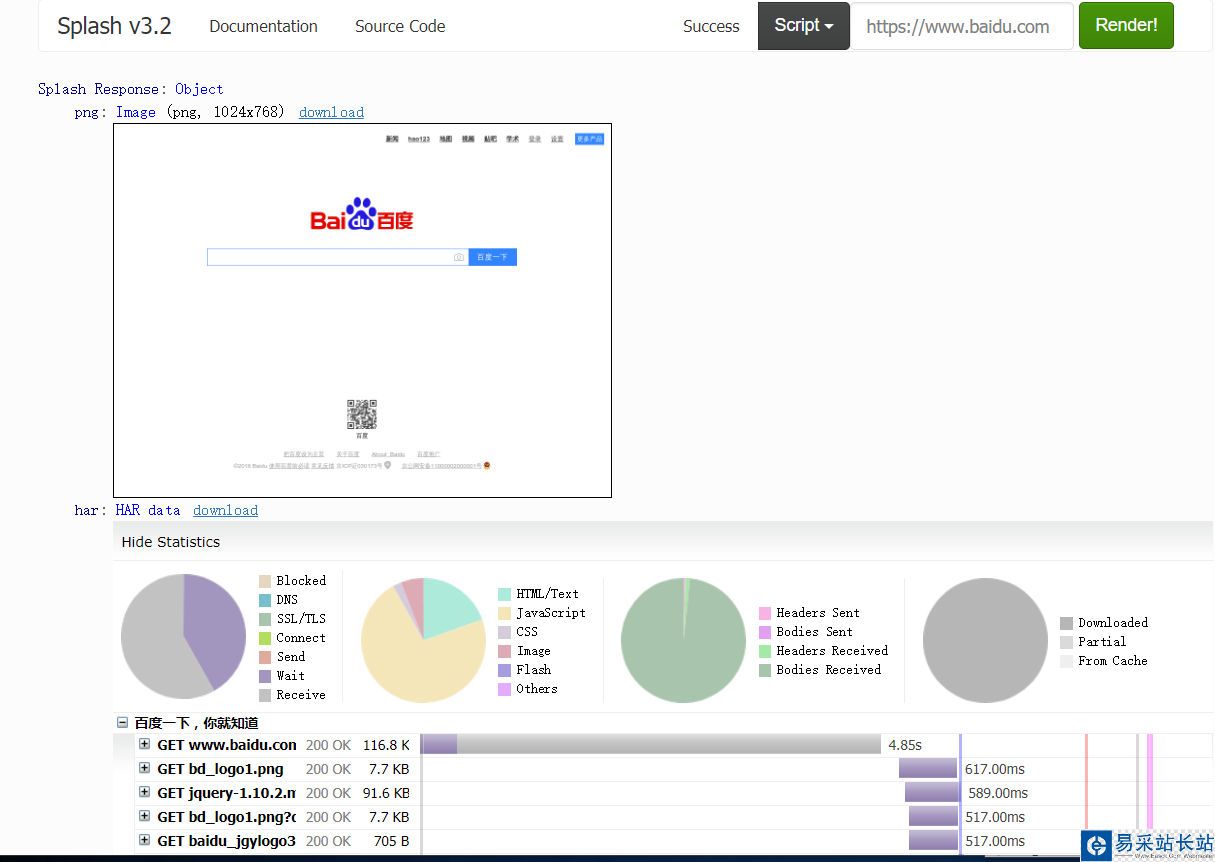
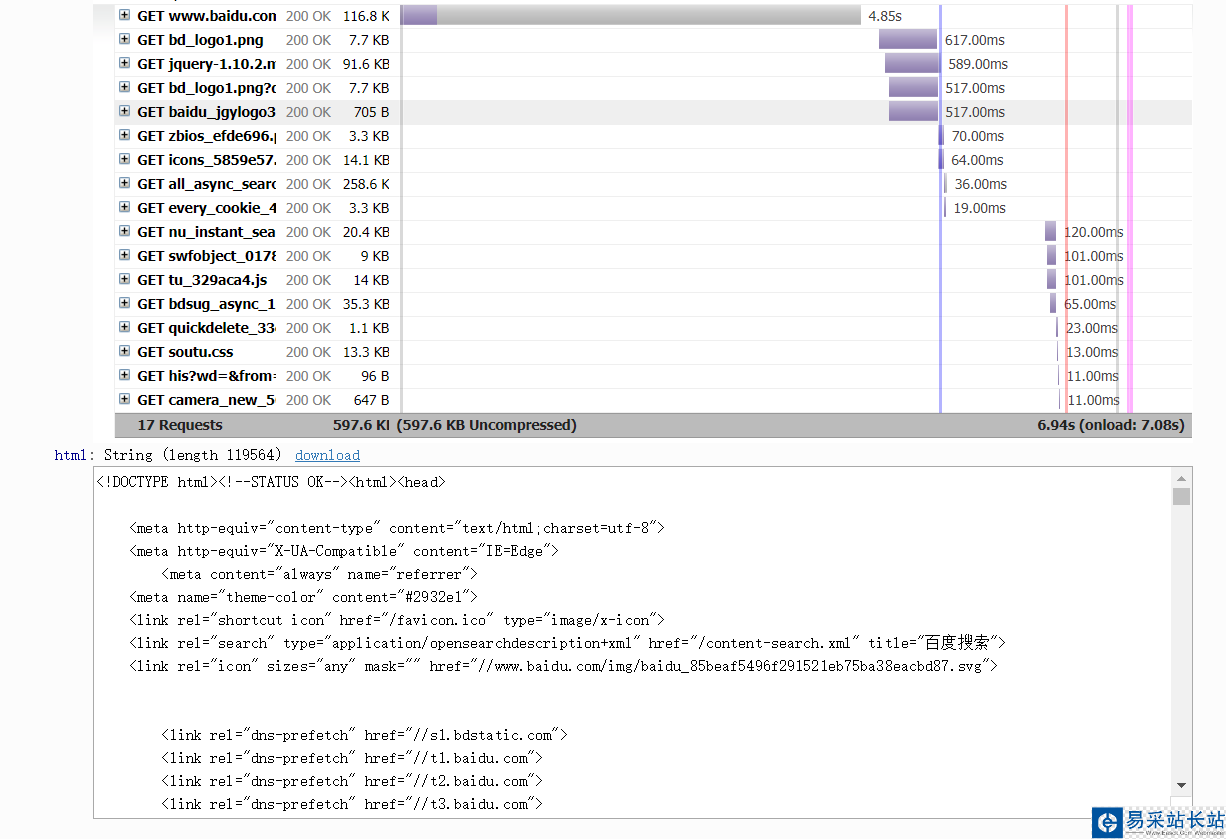
从HAR中可以看到,Splash执行了整个页面的渲染过程,包括CSS、JavaScript的加载等,通过返回结果可以看到它分别对应搜索框下面的脚本文件中return部分的三个返回值,html、png、har:
function main(splash, args) assert(splash:go(args.url)) assert(splash:wait(0.5)) return { html = splash:html(), png = splash:png(), har = splash:har(), }end这个脚本是使用Lua语言写的,它首先使用go()方法加载页面,wait()方法等待加载时间,然后返回源码、截图和HAR信息。
新闻热点






疑难解答













