学习Python数据分析挖掘实战一书时,在数据预处理阶段,有一节要使用拉格朗日插值法对缺失值补充,代码如下:
#-*- coding:utf-8 -*-import pandas as pdimport matplotlib.pyplot as pltfrom scipy.interpolate import lagrange#导入拉格朗日插值函数inputfile="catering_sale.xls"outputfile="H:/python/file/python_data_annalysis_mining/chapter04/sales.xls"data=pd.read_excel(inputfile,sheetname=0)statistic=data.describe()#保存基本统计量print statistictime=data[u'日期'].valuesnumber=data[u'销量'].valuesplt.scatter(time,number)plt.show()#根据散点图找过滤异常值的方法data[u'销量'][(data[u'销量']<300)|(data[u'销量']>6000)]=None#过滤异常值,设置为空#自定义列向量插值函数#s为列向量,n为插值位置,k为取前后的数据个数,默认为5,不宜太多,受到数值不稳定性影响def ployinterp_column(s,n,k=5): y=s[list(range(n-k,n))+list(range(n+1,n+1+k))] y=y[y.notnull()]#剔除异常值 return lagrange(y.index,list(y))(n)#插值并返回插值结果for i in data.columns: for j in range(len(data)): if(data[i].isnull())[j]: data[i][j]=ployinterp_column(data[i],j)data.to_excel(outputfile)
1.import xlwt 错误
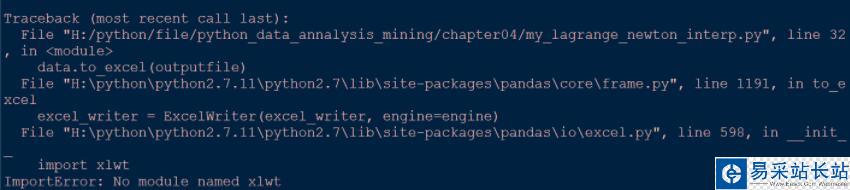
这个问题比较简单,只需要在官网上下载安装或者直接在编译器中运行如下代码即可,
pip install xlwt
2.to_excel错误
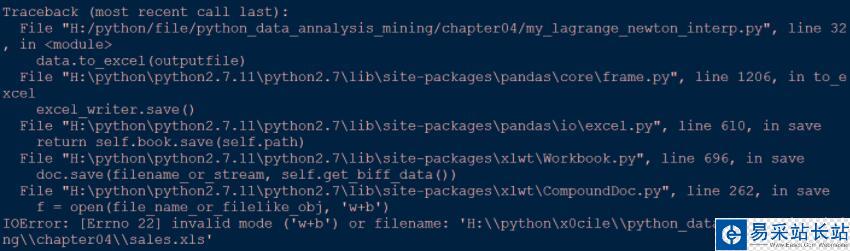
这个错误是由于下面这句代码引起的,
data.to_excel(outputfile)
错误描述:无效的模式('w+b')或者文件名,意思是,出现这个问题的原因可能有两个,outputfile这个文件不可写入(w是“写”的意思),或者打开模式不对(b是以二进制方式写);另一种错误,文件名出错,很有可能是路径有问题,经过检查,确实是路径的问题,代码如下:
outputfile="H:/python/file/python_data_annalysis_mining/chapter04/sales.xls"
改为如下代码即可:
outputfile="H://python//file//python_data_annalysis_mining//chapter04//sales.xls"
即把单斜杠改为双斜杠,,因为存在转义问题。
以上这篇解决Python pandas df 写入excel 出现的问题就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持武林站长站。
新闻热点






疑难解答













