1. 基本介绍
tensorflow设备内存管理模块实现了一个best-fit with coalescing算法(后文简称bfc算法)。
bfc算法是Doung Lea's malloc(dlmalloc)的一个非常简单的版本。
它具有内存分配、释放、碎片管理等基本功能。
2. bfc基本算法思想
1. 数据结构
整个内存空间由一个按基址升序排列的Chunk双向链表来表示,它们的直接前趋和后继必须在地址连续的内存空间。Chunk结构体里含有实际大小、请求大小、是否被占用、基址、直接前趋、直接后继、Bin索引等信息。
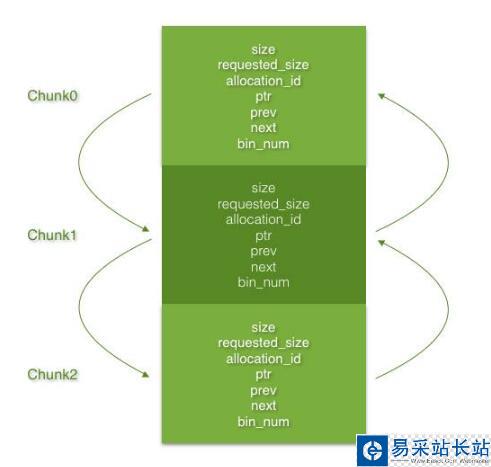
2. 申请
用户申请一个内存块(malloc)。根据chunk双链表找到一个合适的内存块,如果该内存块的大小是用户申请的大小的二倍以上,那么就将该内存块切分成两块,这就是split操作。
返回其中一块给用户,并将该内存块标识为占用
Spilt操作会新增一个chunk,所以需要修改chunk双链表以维持前驱和后继关系
如果用户申请512的空间,正好有一块1024的chunk2是空闲的,由于1024/512 =2,所以chunk2 被split为2块:chunk2_1和chunk2_2。返回chunk2_1给用户并将其标志位占用状态。
3. 释放
用户释放一个内存块(free)。先将该块标记为空闲。然后根据chunk数据结构中的信息找到其前驱和后继内存块。如果前驱和后继块中有空闲的块,那么将刚释放的块和空闲的块合并成一个更大的chunk(这就是merge操作,合并当前块和其前后的空闲块)。再修改双链表结构以维持前驱后继关系。这就做到了内存碎片的回收。
如果用户要free chunk3,由于chunk3的前驱chunk2也是空闲的,所以将chunk2和chunk3合并得到一个新的chunk2',大小为chunk2和chunk3之和。
3. bins
1. bins数据结构
bfc算法采取的是被动分块的策略。最开始整个内存是一个chunk,随着用户申请空间的次数增加,最开始的大chunk会被不断的split开来,从而产生越来越多的小chunk。当chunk数量很大时,为了寻找一个合适的内存块而遍历双链表无疑是一笔巨大的开销。为了实现对空闲块的高效管理,bfc算法设计了bin这个抽象数据结构。
每个bin都有一个size属性,一个bin是一个拥有chunk size >= binsize的空闲chunk的集合。集合中的chunk按照chunk size的升序组织成单链表。bfc算法维护了一个bin的集合:bins。它由多个bin以及从属于每个bin的chunks组成。内存中所有的空闲chunk都由bins管理。
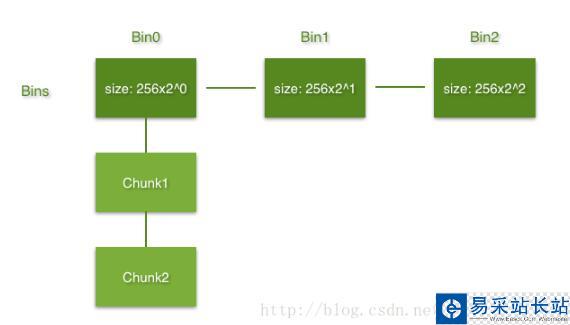
图中每一列表示一个bin,列首方格中的数字表示bin的size。bin size的大小都是256的2^n的倍。每个bin下面挂载了一系列的空闲chunk,每个chunk的chunk size都大于等于所属的bin的bin size,按照chunk size的升序挂载成单链表。
新闻热点






疑难解答













