一.前言
最近刚好在练手一个数据挖掘的项目,众所周知,数据挖掘中比较重要的一步为数据清洗,而对重复数据的处理也是数据清洗中经常碰到的一项。本文将仅介绍如何利用Pandas来清除重复数据(主要指重复行),话不多说请看下文。
二.具体介绍
2.1. 导入Pandas库
pandas是python的核心数据分析库,你可以把它理解为python版的excel,倘若你还没有安装相应的库,请查询相关教程进行安装,导入pandas的代码为:
import pandas as pd
2.2. DataFrame.duplicated和DataFrame.drop_duplicates
2.2.1. duplicated函数
duplicated函数的功能为:Return boolean Series denoting duplicate rows,即返回一个标识重复行的布尔类型的数组(Series),其中重复行将标识为true,而非重复行将标识为false。
要介绍该函数的功能,首先我随意创建一个DataFrame对象,该对象的数据如下:
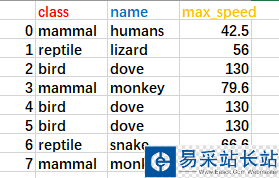
对应的创建代码为
import pandas as pd#利用字典创建DataFrame对象animal={'class':['mammal','reptile','bird','mammal','bird','bird','reptile','mammal'], 'name':['humans','lizard','dove','monkey','dove','dove','snake','monkey'], 'max_speed':[42.5,56,130,79.6,130,130,66.6,79.6]}df = pd.DataFrame(animal)应用duplicated函数便可以得到对应的bool数组,对应的代码行为
print(df.duplicated())'''对应的运行结果为 0 False 1 False 2 False 3 False 4 True 5 True 6 False 7 True dtype: bool'''
当然,在应用该函数时,我们可以为其指定参数,其原型为DataFrame.duplicated(self,subset,keep),其中:
subset参数用来指定用来识别重复的列标签/列标签序列,当未指定时默认比较整行的所有列来判别是否重复;
keep参数用来指定如何标记重复行,它的值有三个:first,last,False。当选择first时,重复行中除了第一次出现的全部标记为True;当选择last时,重复行中除最后一次出现的全部标记为True;当选择False时,所有重复行都将标记为True。
上述参数的代码示例为
#指定subset为classprint(df.duplicated('class'))'''对应的运行结果 0 False 1 False 2 False 3 True 4 True 5 True 6 True 7 True dtype: bool'''#指定subset为class,nameprint(df.duplicated(['class','name']))'''对应的运行结果 0 False 1 False 2 False 3 False 4 True 5 True 6 False 7 True dtype: bool'''#指定keep为lastprint(df.duplicated(subset=['class','name'],keep='last'))'''对应的运行结果 0 False 1 False 2 True 3 True 4 True 5 False 6 False 7 False dtype: bool'''
新闻热点






疑难解答













