中文分词(Chinese Word Segmentation),将中文语句切割成单独的词组。英文使用空格来分开每个单词的,而中文单独一个汉字跟词有时候完全不是同个含义,因此,中文分词相比英文分词难度高很多。
分词主要用于NLP 自然语言处理(Natural Language Processing),使用场景有:
搜索优化,关键词提取(百度指数) 语义分析,智能问答系统(客服系统) 非结构化文本媒体内容,如社交信息(微博热榜) 文本聚类,根据内容生成分类(行业分类)Python的中文分词库有很多,常见的有:
jieba(结巴分词) THULAC(清华大学自然语言处理与社会人文计算实验室) pkuseg(北京大学语言计算与机器学习研究组) SnowNLP pynlpir CoreNLP pyltp通常前三个是比较经常见到的,主要在易用性/准确率/性能都还不错。我个人常用的一直都是结巴分词(比较早接触),最近使用pkuseg,两者的使用后面详细讲。
“结巴”中文分词:做最好的 Python 中文分词组件
支持三种分词模式: 精确模式,试图将句子最精确地切开,适合文本分析; 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义; 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。 支持繁体分词 支持自定义词典jieba分词实例
我们使用京东商场的美的电器评论来看看结巴分词的效果。如果你没有安装结巴分词库则需要在命令行下输入pip install jieba,安装完之后即可开始分词之旅。
评论数据整理在文件meidi_jd.csv文件中,读取数据前先导入相关库。因为中文的文本或文件的编码方式不同编码选择gb18030,有时候是utf-8、gb2312、gbk自行测试。
# 导入相关库import pandas as pdimport jieba# 读取数据data = pd.read_csv('meidi_jd.csv', encoding='gb18030')# 查看数据data.head()
# 生成分词data['cut'] = data['comment'].apply(lambda x : list(jieba.cut(x)))data.head()
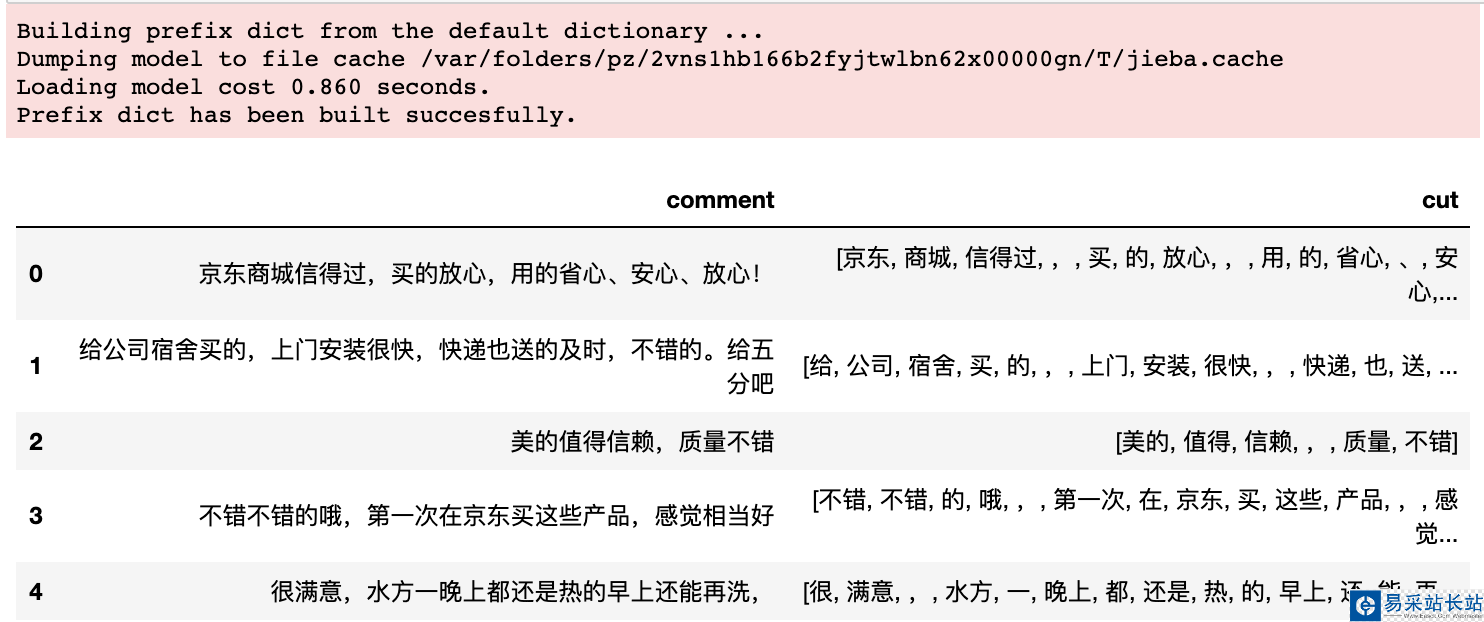
到这里我们仅仅通过一行代码即可生成中文的分词列表,如果你想要生成分词后去重可以改成这样。
data['cut'] = data['comment'].apply(lambda x : list(set(jieba.cut(x))))
经过前面的分词后,我们可以通过查看分词是否准确,会发现实际上有些词被分隔成单独的汉字,例如:
新闻热点






疑难解答













