XML文件是一种常用的文件格式,例如WinForm里面的app.config以及Web程序中的web.config文件,还有许多重要的场所都有它的身影。Xml是Internet环境中跨平台的,依赖于内容的技术,是当前处理结构化文档信息的有力工具。XML是一种简单的数据存储语言,使用一系列简单的标记描述数据,而这些标记可以用方便的方式建立,虽然XML占用的空间比二进制数据要占用更多的空间,但XML极其简单易于掌握和使用。微软也提供了一系列类库来倒帮助我们在应用程序中存储XML文件。
“在程序中访问进而操作XML文件一般有两种模型,分别是使用DOM(文档对象模型)和流模型,使用DOM的好处在于它允许编辑和更新XML文档,可以随机访问文档中的数据,可以使用XPath查询,但是,DOM的缺点在于它需要一次性的加载整个文档到内存中,对于大型的文档,这会造成资源问题。流模型很好的解决了这个问题,因为它对XML文件的访问采用的是流的概念,也就是说,任何时候在内存中只有当前节点,但它也有它的不足,它是只读的,仅向前的,不能在文档中执行向后导航操作。”
下面我将介绍三种常用的读取XML文件的方法。分别是
1: 使用 XmlDocument
2: 使用 XmlTextReader
3: 使用 Linq to Xml
这里我先创建一个XML文件,名为Book.xml下面所有的方法都是基于这个XML文件的,文件内容如下:
<?xml version="1.0" encoding="utf-8"?> <bookstore> <!--记录书本的信息--> <book Type="必修课" ISBN="7-111-19149-2"> <title>数据结构</title> <author>严蔚敏</author> <price>30.00</price> </book> <book Type="必修课" ISBN="7-111-19149-3"> <title>路由型与交换型互联网基础</title> <author>程庆梅</author> <price>27.00</price> </book> <book Type="必修课" ISBN="7-111-19149-4"> <title>计算机硬件技术基础</title> <author>李继灿</author> <price>25.00</price> </book> <book Type="必修课" ISBN="7-111-19149-5"> <title>软件质量保证与管理</title> <author>朱少民</author> <price>39.00</price> </book> <book Type="必修课" ISBN="7-111-19149-6"> <title>算法设计与分析</title> <author>王红梅</author> <price>23.00</price> </book> <book Type="选修课" ISBN="7-111-19149-1"> <title>计算机操作系统</title> <author>7-111-19149-1</author> <price>28</price> </book> </bookstore>
为了方便读取,我还定义一个书的实体类,名为BookModel,具体内容如下:
using System; using System.Collections.Generic; using System.Linq; using System.Text; namespace 使用XmlDocument { public class BookModel { public BookModel() { } /// <summary> /// 所对应的课程类型 /// </summary> private string bookType; public string BookType { get { return bookType; } set { bookType = value; } } /// <summary> /// 书所对应的ISBN号 /// </summary> private string bookISBN; public string BookISBN { get { return bookISBN; } set { bookISBN = value; } } /// <summary> /// 书名 /// </summary> private string bookName; public string BookName { get { return bookName; } set { bookName = value; } } /// <summary> /// 作者 /// </summary> private string bookAuthor; public string BookAuthor { get { return bookAuthor; } set { bookAuthor = value; } } /// <summary> /// 价格 /// </summary> private double bookPrice; public double BookPrice { get { return bookPrice; } set { bookPrice = value; } } } }1.使用XmlDocument.
使用XmlDocument是一种基于文档结构模型的方式来读取XML文件.在XML文件中,我们可以把XML看作是由文档声明(Declare),元素(Element),属性(Attribute),文本(Text)等构成的一个树.最开始的一个结点叫作根结点,每个结点都可以有自己的子结点.得到一个结点后,可以通过一系列属性或方法得到这个结点的值或其它的一些属性.例如:
xn 代表一个结点 xn.Name;//这个结点的名称 xn.Value;//这个结点的值 xn.ChildNodes;//这个结点的所有子结点 xn.ParentNode;//这个结点的父结点 .......
1.1 读取所有的数据.
使用的时候,首先声明一个XmlDocument对象,然后调用Load方法,从指定的路径加载XML文件.
XmlDocument doc = new XmlDocument();doc.Load(@"../../Book.xml");
然后可以通过调用SelectSingleNode得到指定的结点,通过GetAttribute得到具体的属性值.参看下面的代码
// 得到根节点bookstore XmlNode xn = xmlDoc.SelectSingleNode("bookstore"); // 得到根节点的所有子节点 XmlNodeList xnl = xn.ChildNodes; foreach (XmlNode xn1 in xnl) { BookModel bookModel = new BookModel(); // 将节点转换为元素,便于得到节点的属性值 XmlElement xe = (XmlElement)xn1; // 得到Type和ISBN两个属性的属性值 bookModel.BookISBN = xe.GetAttribute("ISBN").ToString(); bookModel.BookType = xe.GetAttribute("Type").ToString(); // 得到Book节点的所有子节点 XmlNodeList xnl0 = xe.ChildNodes; bookModel.BookName=xnl0.Item(0).InnerText; bookModel.BookAuthor=xnl0.Item(1).InnerText; bookModel.BookPrice=Convert.ToDouble(xnl0.Item(2).InnerText); bookModeList.Add(bookModel); } dgvBookInfo.DataSource = bookModeList;在正常情况下,上面的代码好像没有什么问题,但是对于读取上面的XML文件,则会出错,原因就是因为我上面的XML文件里面有注释,大家可以参看Book.xml文件中的第三行,我随便加的一句注释.注释也是一种结点类型,在没有特别说明的情况下,会默认它也是一个结点(Node).所以在把结点转换成元素的时候就会报错."无法将类型为“System.Xml.XmlComment”的对象强制转换为类型“System.Xml.XmlElement”。"
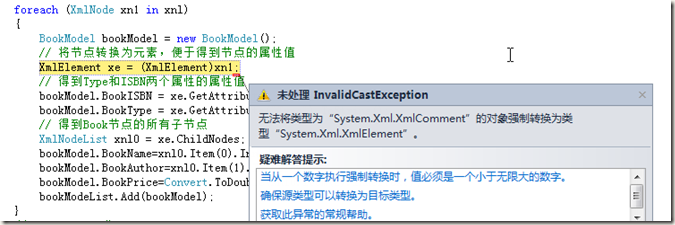
幸亏它里面自带了解决办法,那就是在读取的时候,告诉编译器让它忽略掉里面的注释信息.修改如下:
XmlDocument xmlDoc = new XmlDocument();XmlReaderSettings settings = new XmlReaderSettings();settings.IgnoreComments = true;//忽略文档里面的注释XmlReader reader = XmlReader.Create(@"../../Book.xml", settings);xmlDoc.Load(reader);
最后读取完毕后,记得要关掉reader.
reader.Close();
这样它就不会出现错误.
最后运行结果如下:

1.2 增加一本书的信息.
向文件中添加新的数据的时候,首先也是通过XmlDocument加载整个文档,然后通过调用SelectSingleNode方法获得根结点,通过CreateElement方法创建元素,用CreateAttribute创建属性,用AppendChild把当前结点挂接在其它结点上,用SetAttributeNode设置结点的属性.具体代码如下:
加载文件并选出要结点:
XmlDocument doc = new XmlDocument();doc.Load(@"../../Book.xml");XmlNode root = doc.SelectSingleNode("bookstore");创建一个结点,并设置结点的属性:
XmlElement xelKey = doc.CreateElement("book"); XmlAttribute xelType = doc.CreateAttribute("Type"); xelType.InnerText = "adfdsf"; xelKey.SetAttributeNode(xelType);创建子结点:
XmlElement xelAuthor = doc.CreateElement("author"); xelAuthor.InnerText = "dfdsa"; xelKey.AppendChild(xelAuthor);最后把book结点挂接在要结点上,并保存整个文件:
root.AppendChild(xelKey);doc.Save(@"../../Book.xml");
用上面的方法,是向已有的文件上追加数据,如果想覆盖原有的所有数据,可以更改一下,使用LoadXml方法:
XmlDocument doc = new XmlDocument(); doc.LoadXml("<bookstore></bookstore>");//用这句话,会把以前的数据全部覆盖掉,只有你增加的数据直接把根结点选择出来了,后面不用SelectSingleNode方法选择根结点,直接创建结点即可,代码同上.
1.3 删除某一个数据
想要删除某一个结点,直接找到其父结点,然后调用RemoveChild方法即可,现在关键的问题是如何找到这个结点,上面的SelectSingleNode可以传入一个Xpath表,我们通过书的ISBN号来找到这本书所在的结点.如下:
XmlElement xe = xmlDoc.DocumentElement; // DocumentElement 获取xml文档对象的根XmlElement. string strPath = string.Format("/bookstore/book[@ISBN=/"{0}/"]", dgvBookInfo.CurrentRow.Cells[1].Value.ToString()); XmlElement selectXe = (XmlElement)xe.SelectSingleNode(strPath); //selectSingleNode 根据XPath表达式,获得符合条件的第一个节点. selectXe.ParentNode.RemoveChild(selectXe);"/bookstore/book[@ISBN=/"{0}/"]"是一个Xpath表达式,找到ISBN号为所选那一行ISBN号的那本书,有关Xpath的知识请参考:XPath 语法
1.4 修改某要条数据
修改某 条数据的话,首先也是用Xpath表达式找到所需要修改的那一个结点,然后如果是元素的话,就直接对这个元素赋值,如果是属性的话,就用SetAttribute方法设置即可.如下:
XmlElement xe = xmlDoc.DocumentElement; // DocumentElement 获取xml文档对象的根XmlElement. string strPath = string.Format("/bookstore/book[@ISBN=/"{0}/"]", dgvBookInfo.CurrentRow.Cells[1].Value.ToString()); XmlElement selectXe = (XmlElement)xe.SelectSingleNode(strPath); //selectSingleNode 根据XPath表达式,获得符合条件的第一个节点. selectXe.SetAttribute("Type", dgvBookInfo.CurrentRow.Cells[0].Value.ToString());//也可以通过SetAttribute来增加一个属性 selectXe.GetElementsByTagName("title").Item(0).InnerText = dgvBookInfo.CurrentRow.Cells[2].Value.ToString(); selectXe.GetElementsByTagName("author").Item(0).InnerText = dgvBookInfo.CurrentRow.Cells[3].Value.ToString(); selectXe.GetElementsByTagName("price").Item(0).InnerText = dgvBookInfo.CurrentRow.Cells[4].Value.ToString(); xmlDoc.Save(@"../../Book.xml");2.使用XmlTextReader和XmlTextWriter
XmlTextReader和XmlTextWriter是以流的形式来读写XML文件.
2.1XmlTextReader
使用XmlTextReader读取数据的时候,首先创建一个流,然后用read()方法来不断的向下读,根据读取的结点的类型来进行相应的操作.如下:
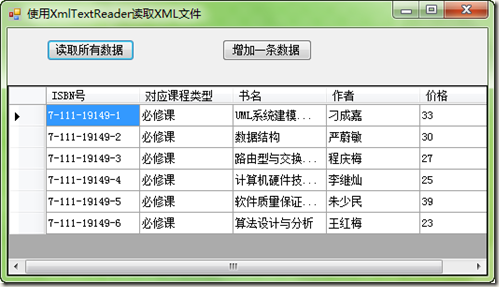
XmlTextReader reader = new XmlTextReader(@"../../Book.xml"); List<BookModel> modelList = new List<BookModel>(); BookModel model = new BookModel(); while (reader.Read()) { if (reader.NodeType == XmlNodeType.Element) { if (reader.Name == "book") { model.BookType = reader.GetAttribute(0); model.BookISBN = reader.GetAttribute(1); } if (reader.Name == "title") { model.BookName=reader.ReadElementString().Trim(); } if (reader.Name == "author") { model.BookAuthor = reader.ReadElementString().Trim(); } if (reader.Name == "price") { model.BookPrice = Convert.ToDouble(reader.ReadElementString().Trim()); } } if (reader.NodeType == XmlNodeType.EndElement) { modelList.Add(model); model = new BookModel(); } } modelList.RemoveAt(modelList.Count-1); this.dgvBookInfo.DataSource = modelList;关键是读取属性的时候,你要先知道哪一个结点具有几个属性,然后通过GetAttribute方法来读取.读取属性还可以用另外一种方法,就是用MoveToAttribute方法.可参见下面的代码:
if (reader.Name == "book") { for (int i = 0; i < reader.AttributeCount; i++) { reader.MoveToAttribute(i); string str = "属性:" + reader.Name + "=" + reader.Value; } model.BookType = reader.GetAttribute(0); model.BookISBN = reader.GetAttribute(1); }效果如下:
2.2XmlTextWriter
XmlTextWriter写文件的时候,默认是覆盖以前的文件,如果此文件名不存在,它将创建此文件.首先设置一下,你要创建的XML文件格式,
XmlTextWriter myXmlTextWriter = new XmlTextWriter(@"../../Book1.xml", null); //使用 Formatting 属性指定希望将 XML 设定为何种格式。 这样,子元素就可以通过使用 Indentation 和 IndentChar 属性来缩进。 myXmlTextWriter.Formatting = Formatting.Indented;
然后可以通过WriteStartElement和WriteElementString方法来创建元素,这两者的区别就是如果有子结点的元素,那么创建的时候就用WriteStartElement,然后去创建子元素,创建完毕后,要调用相应的WriteEndElement来告诉编译器,创建完毕,用WriteElementString来创建单个的元素,用WriteAttributeString来创建属性.如下:
XmlTextWriter myXmlTextWriter = new XmlTextWriter(@"../../Book1.xml", null); //使用 Formatting 属性指定希望将 XML 设定为何种格式。 这样,子元素就可以通过使用 Indentation 和 IndentChar 属性来缩进。 myXmlTextWriter.Formatting = Formatting.Indented; myXmlTextWriter.WriteStartDocument(false); myXmlTextWriter.WriteStartElement("bookstore"); myXmlTextWriter.WriteComment("记录书本的信息"); myXmlTextWriter.WriteStartElement("book"); myXmlTextWriter.WriteAttributeString("Type", "选修课"); myXmlTextWriter.WriteAttributeString("ISBN", "111111111"); myXmlTextWriter.WriteElementString("author","张三"); myXmlTextWriter.WriteElementString("title", "职业生涯规划"); myXmlTextWriter.WriteElementString("price", "16.00"); myXmlTextWriter.WriteEndElement(); myXmlTextWriter.WriteEndElement(); myXmlTextWriter.Flush(); myXmlTextWriter.Close();3.使用Linq to XML.
Linq是C#3.0中出现的一个新特性,使用它可以方便的操作许多数据源,也包括XML文件.使用Linq操作XML文件非常的方便,而且也比较简单.下面直接看代码,
先定义 一个方法显示查询出来的数据
private void showInfoByElements(IEnumerable<XElement> elements) { List<BookModel> modelList = new List<BookModel>(); foreach (var ele in elements) { BookModel model = new BookModel(); model.BookAuthor = ele.Element("author").Value; model.BookName = ele.Element("title").Value; model.BookPrice = Convert.ToDouble(ele.Element("price").Value); model.BookISBN=ele.Attribute("ISBN").Value; model.BookType=ele.Attribute("Type").Value; modelList.Add(model); } dgvBookInfo.DataSource = modelList; }3.1读取所有的数据
直接找到元素为book的这个结点,然后遍历读取所有的结果.
private void btnReadAll_Click(object sender, EventArgs e) { XElement xe = XElement.Load(@"../../Book.xml"); IEnumerable<XElement> elements = from ele in xe.Elements("book") select ele; showInfoByElements(elements); }3.2插入一条数据
插入结点和属性都采用new的方法,如下:
private void btnInsert_Click(object sender, EventArgs e) { XElement xe = XElement.Load(@"../../Book.xml"); XElement record = new XElement( new XElement("book", new XAttribute("Type", "选修课"), new XAttribute("ISBN","7-111-19149-1"), new XElement("title", "计算机操作系统"), new XElement("author", "7-111-19149-1"), new XElement("price", 28.00))); xe.Add(record); xe.Save(@"../../Book.xml"); MessageBox.Show("插入成功!"); btnReadAll_Click(sender, e); }3.3 删除选中的数据
首先得到选中的那一行,通过ISBN号来找到这个元素,然后用Remove方法直接删除,如下:
private void btnDelete_Click(object sender, EventArgs e) { if (dgvBookInfo.CurrentRow != null) { //dgvBookInfo.CurrentRow.Cells[1]对应着ISBN号 string id = dgvBookInfo.CurrentRow.Cells[1].Value.ToString(); XElement xe = XElement.Load(@"../../Book.xml"); IEnumerable<XElement> elements = from ele in xe.Elements("book") where (string)ele.Attribute("ISBN") == id select ele; { if (elements.Count() > 0) elements.First().Remove(); } xe.Save(@"../../Book.xml"); MessageBox.Show("删除成功!"); btnReadAll_Click(sender, e); } }3.4 删除所有的数据
与上面的类似,选出所有的数据,然后用Remove方法,如下:
private void btnDeleteAll_Click(object sender, EventArgs e) { XElement xe = XElement.Load(@"../../Book.xml"); IEnumerable<XElement> elements = from ele in xe.Elements("book") select ele; if (elements.Count() > 0) { elements.Remove(); } xe.Save(@"../../Book.xml"); MessageBox.Show("删除成功!"); btnReadAll_Click(sender, e); }3.5 修改某一记录
首先得到所要修改的某一个结点,然后用SetAttributeValue来修改属性,用ReplaceNodes来修改结点元素。如下:
private void btnSave_Click(object sender, EventArgs e) { XElement xe = XElement.Load(@"../../Book.xml"); if (dgvBookInfo.CurrentRow != null) { //dgvBookInfo.CurrentRow.Cells[1]对应着ISBN号 string id = dgvBookInfo.CurrentRow.Cells[1].Value.ToString(); IEnumerable<XElement> element = from ele in xe.Elements("book") where ele.Attribute("ISBN").Value == id select ele; if (element.Count() > 0) { XElement first = element.First(); ///设置新的属性 first.SetAttributeValue("Type", dgvBookInfo.CurrentRow.Cells[0].Value.ToString()); ///替换新的节点 first.ReplaceNodes( new XElement("title", dgvBookInfo.CurrentRow.Cells[2].Value.ToString()), new XElement("author", dgvBookInfo.CurrentRow.Cells[3].Value.ToString()), new XElement("price", (double)dgvBookInfo.CurrentRow.Cells[4].Value) ); } xe.Save(@"../../Book.xml"); MessageBox.Show("修改成功!"); btnReadAll_Click(sender, e); } }最终效果如下:

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持武林网。
新闻热点






疑难解答













