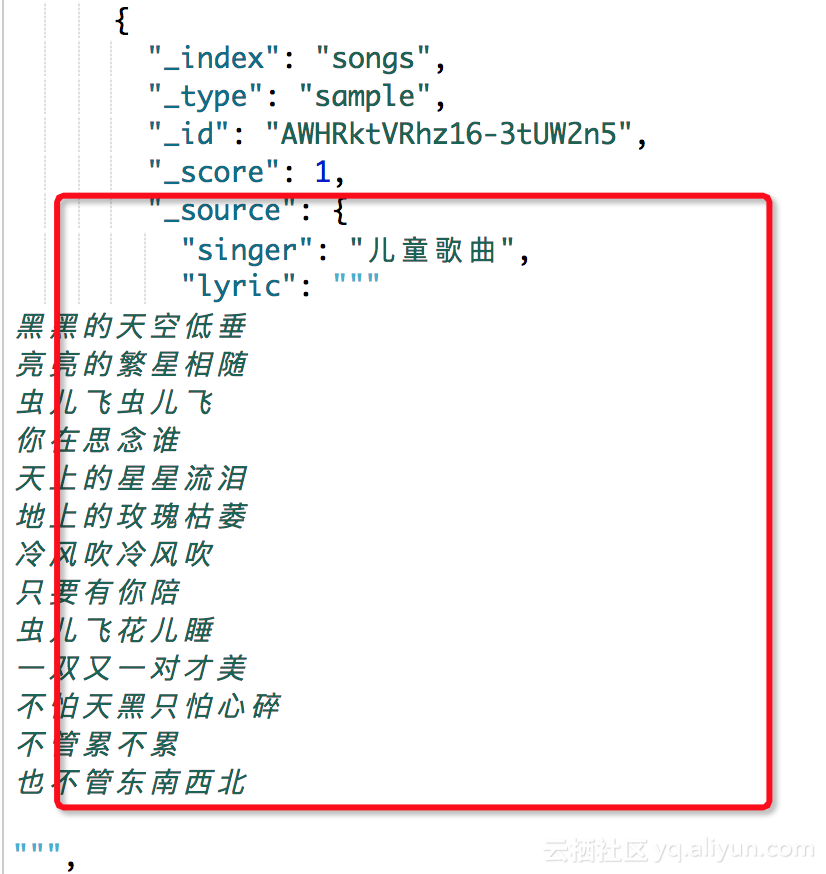
下面展示一篇我自己写的一个XML读取测试
public class XmlRead {
static StringBuilder sBuilder = new StringBuilder();
public static void main(String[] args) throws IOException {
BufferedReader bReader = new BufferedReader(new InputStreamReader(
System.in));
String path = null;
System.out.println("请输入XML文件的绝对路径以及文件名:/n");
path = bReader.readLine();
sBuilder.append("开始输出XML文件内容/n");
Document document = null;
try {
document = read(path);
sBuilder.append(path + "/n");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (DocumentException e) {
e.printStackTrace();
}
Element root = getRootElement(document);
if (root == null) {
System.out.print("没有获取到root节点");
return;
}
// 获取XML文档的编码格式
String encString = document.getXMLEncoding();
sBuilder.append("<?xml version=/"1.0/" encoding=/"" + encString
+ "/">/n");
sBuilder.append(elementText(root, attText(root), 0));
System.out.println(getIterator(root, 0) + "</" + root.getName() + ">");
}
/**
* 递归节点
*
* @description
* @param element
* @param lvl
* 层级
* @return
*/
private static String getIterator(Element element, int lvl) {
lvl += 1;
for (Iterator i = element.elementIterator(); i.hasNext();) {
Element e = (Element) i.next();
sBuilder.append(elementText(e, attText(e), lvl));
getIterator(e, lvl);
int count = e.nodeCount();
if (count > 0) {
for (int j = 0; j < lvl; j++) {
sBuilder.append(" ");
}
}
sBuilder.append("</" + e.getName() + ">/n");
}
return sBuilder.toString();
}
/**
* 获取当前节点的属性的值的字符串
*
* @description
* @param element
* 当前节点
* @return
*/
private static String attText(Element element) {
String str = " ";
for (int i = 0; i < element.attributeCount(); i++) {
Attribute attribute = element.attribute(i);
str += attribute.getName() + "=/"" + attribute.getValue() + "/" ";
}
return str;
}
/**
* 获取当前Element的文本值
*
* @description
* @param element
* 当前Element节点
* @param text
* 属性值
* @param lvl
* 层级
* @return
*/
private static String elementText(Element element, String text, int lvl) {
String str = "";
for (int i = 0; i < lvl; i++) {
str += " ";
}
str += "<" + element.getName();
if (text != null && text != "") {
str += text;
}
//由于dom4j里面没有 hasChild这个属性或者方法,所以要用nodeCount()这个方法来判断时候还有子节点
int count = element.nodeCount();
if (count == 0) {
return str += ">";
}
return str += ">/n";
}
/**
*
* @description 读取XML文件
* @param file
* XML文件路径,包含文件名
* @return Document 文档
* @throws MalformedURLException
* @throws DocumentException
*/
public static Document read(String file) throws MalformedURLException,
DocumentException {
SAXReader reader = new SAXReader();
Document document = reader.read(new File(file));
return document;
}
/**
* 获取Document文档的root节点
*
* @param document
* @return
*/
public static Element getRootElement(Document document) {
return document.getRootElement();
}
}
新闻热点






疑难解答