public int hashCode() {
int h = hash;
if (h == 0) {
int off = offset;
char val[] = value;
int len = count;
for (int i = 0; i < len; i++) {
h = 31*h + val[off++];
}
hash = h;
}
return h;
}
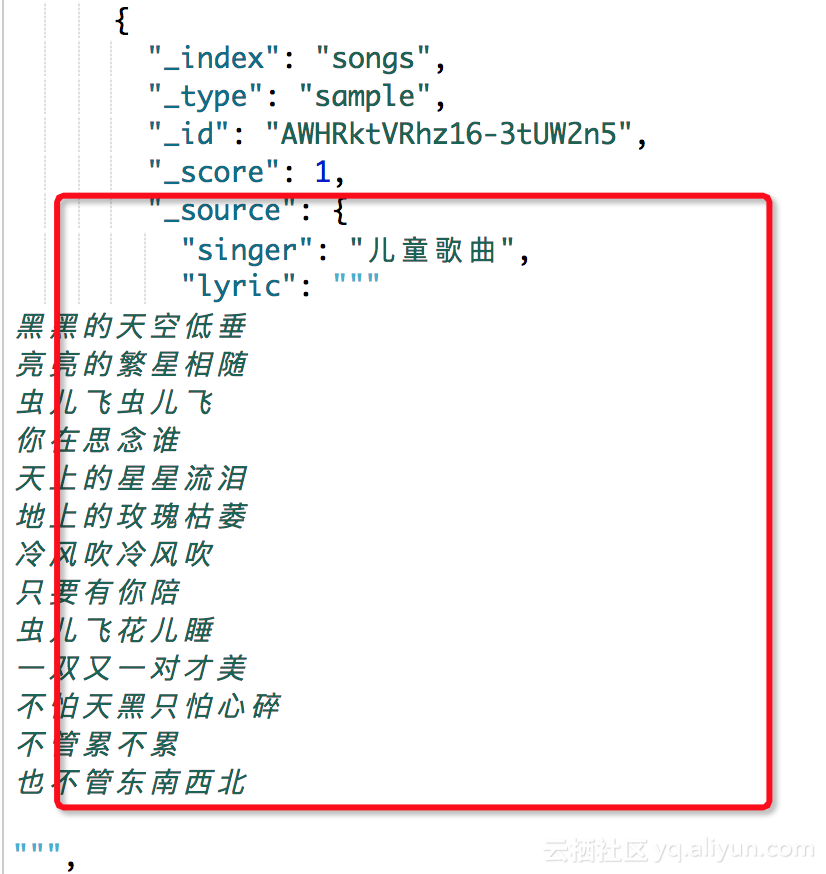
那为什么在重写equals方法时都要重写equals方法呢:
首先equals与hashcode间的关系是这样的:
1、如果两个对象相同(即用equals比较返回true),那么它们的hashCode值一定要相同;
2、如果两个对象的hashCode相同,它们并不一定相同(即用equals比较返回false)
自我的理解:由于为了提高程序的效率才实现了hashcode方法,先进行hashcode的比较,如果不同,那没就不必在进行equals的比较了,这样就大大减少了equals比较的
次数,这对比需要比较的数量很大的效率提高是很明显的,一个很好的例子就是在集合中的使用;
我们都知道java中的List集合是有序的,因此是可以重复的,而set集合是无序的,因此是不能重复的,那么怎么能保证不能被放入重复的元素呢,但靠equals方法一样比较的
话,如果原来集合中以后又10000个元素了,那么放入10001个元素,难道要将前面的所有元素都进行比较,看看是否有重复,欧码噶的,这个效率可想而知,因此hashcode
就应遇而生了,java就采用了hash表,利用哈希算法(也叫散列算法),就是将对象数据根据该对象的特征使用特定的算法将其定义到一个地址上,那么在后面定义进来的数据
只要看对应的hashcode地址上是否有值,那么就用equals比较,如果没有则直接插入,只要就大大减少了equals的使用次数,执行效率就大大提高了。
继续上面的话题,为什么必须要重写hashcode方法,其实简单的说就是为了保证同一个对象,保证在equals相同的情况下hashcode值必定相同,如果重写了equals而未重写
hashcode方法,可能就会出现两个没有关系的对象equals相同的(因为equal都是根据对象的特征进行重写的),但hashcode确实不相同的
新闻热点






疑难解答