正则表达式中 字符串前面加r,表示的意思是禁止字符串转义
>>>PRint"asfdas/n"asfdas>>>print"asfdas//n"asfdas/n>>>print"asfdas/n"asfdas>>>printr"asfdas/n"asfdas/nurllib 库
importurllib2 response=urllib2.urlopen("http://www.baidu.com")printresponse.read()构造request
importurllib2 request=urllib2.Request("http://www.baidu.com")response=urllib2.urlopen(request)printresponse.read()post 传数据 模拟登录
| 3456789 | importurllibimporturllib2 values={"username":"1016903103@QQ.com","passWord":"XXXX"}data=urllib.urlencode(values)url="https://passport.csdn.net/account/login?from=http://my.csdn.net/my/mycsdn"request=urllib2.Request(url,data)response=urllib2.urlopen(request)printresponse.read() |
get传数据
importurllibimporturllib2 values={}values['username']="1016903103@qq.com"values['password']="XXXX"data=urllib.urlencode(values)url="http://passport.csdn.net/account/login"geturl=url+"?"+datarequest=urllib2.Request(geturl)response=urllib2.urlopen(request)printresponse.read()设置header
importurllib importurllib2 url='http://www.server.com/login'user_agent='Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' values={'username':'cqc', 'password':'XXXX'} headers={'User-Agent':user_agent} data=urllib.urlencode(values) request=urllib2.Request(url,data,headers) response=urllib2.urlopen(request) page=response.read()另外headers的一些属性,下面的需要特别注意一下:
User-Agent : 有些服务器或 Proxy 会通过该值来判断是否是浏览器发出的请求Content-Type : 在使用 REST 接口时,服务器会检查该值,用来确定 HTTP Body 中的内容该怎样解析。application/xml : 在 XML RPC,如 RESTful/SOAP 调用时使用application/json : 在 JSON RPC 调用时使用application/x-www-form-urlencoded : 浏览器提交 Web 表单时使用在使用服务器提供的 RESTful 或 SOAP 服务时, Content-Type 设置错误会导致服务器拒绝服务
其他的有必要的可以审查浏览器的headers内容,在构建时写入同样的数据即可。
1.URLError
首先解释下URLError可能产生的原因:
网络无连接,即本机无法上网连接不到特定的服务器服务器不存在在代码中,我们需要用try-except语句来包围并捕获相应的异常。下面是一个例子,先感受下它的风骚
importurllib2 requset=urllib2.Request('http://www.xxxxx.com')try: urllib2.urlopen(requset)excepturllib2.URLError,e: printe.reason 我们利用了 urlopen方法访问了一个不存在的网址,运行结果如下:
Python
1 [Errno 11004] getaddrinfo failed 它说明了错误代号是11004,错误原因是 getaddrinfo failed
2.HTTPError
HTTPError是URLError的子类,在你利用urlopen方法发出一个请求时,服务器上都会对应一个应答对象response,其中它包含一个数字”状态码”。举个例子,假如response是一个”重定向”,需定位到别的地址获取文档,urllib2将对此进行处理。
其他不能处理的,urlopen会产生一个HTTPError,对应相应的状态吗,HTTP状态码表示HTTP协议所返回的响应的状态。下面将状态码归结如下:
100:继续 客户端应当继续发送请求。客户端应当继续发送请求的剩余部分,或者如果请求已经完成,忽略这个响应。
101: 转换协议 在发送完这个响应最后的空行后,服务器将会切换到在Upgrade 消息头中定义的那些协议。只有在切换新的协议更有好处的时候才应该采取类似措施。
102:继续处理 由WebDAV(RFC 2518)扩展的状态码,代表处理将被继续执行。
200:请求成功 处理方式:获得响应的内容,进行处理
201:请求完成,结果是创建了新资源。新创建资源的URI可在响应的实体中得到 处理方式:爬虫中不会遇到
202:请求被接受,但处理尚未完成 处理方式:阻塞等待
204:服务器端已经实现了请求,但是没有返回新的信 息。如果客户是用户代理,则无须为此更新自身的文档视图。 处理方式:丢弃
300:该状态码不被HTTP/1.0的应用程序直接使用, 只是作为3XX类型回应的默认解释。存在多个可用的被请求资源。 处理方式:若程序中能够处理,则进行进一步处理,如果程序中不能处理,则丢弃301:请求到的资源都会分配一个永久的URL,这样就可以在将来通过该URL来访问此资源 处理方式:重定向到分配的URL
302:请求到的资源在一个不同的URL处临时保存 处理方式:重定向到临时的URL
304:请求的资源未更新 处理方式:丢弃
400:非法请求 处理方式:丢弃
401:未授权 处理方式:丢弃
403:禁止 处理方式:丢弃
404:没有找到 处理方式:丢弃
500:服务器内部错误 服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。一般来说,这个问题都会在服务器端的源代码出现错误时出现。
501:服务器无法识别 服务器不支持当前请求所需要的某个功能。当服务器无法识别请求的方法,并且无法支持其对任何资源的请求。
502:错误网关 作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应。
503:服务出错 由于临时的服务器维护或者过载,服务器当前无法处理请求。这个状况是临时的,并且将在一段时间以后恢复。
HTTPError实例产生后会有一个code属性,这就是是服务器发送的相关错误号。因为urllib2可以为你处理重定向,也就是3开头的代号可以被处理,并且100-299范围的号码指示成功,所以你只能看到400-599的错误号码。
下面我们写一个例子来感受一下,捕获的异常是HTTPError,它会带有一个code属性,就是错误代号,另外我们又打印了reason属性,这是它的父类URLError的属性。
Python
12345678 importurllib2 req=urllib2.Request('http://blog.csdn.net/cqcre')try: urllib2.urlopen(req)excepturllib2.HTTPError,e: printe.code printe.reason 运行结果如下
Python
12 403Forbidden 错误代号是403,错误原因是Forbidden,说明服务器禁止访问。
我们知道,HTTPError的父类是URLError,根据编程经验,父类的异常应当写到子类异常的后面,如果子类捕获不到,那么可以捕获父类的异常,所以上述的代码可以这么改写
Python
1234567891011 importurllib2 req=urllib2.Request('http://blog.csdn.net/cqcre')try: urllib2.urlopen(req)excepturllib2.HTTPError,e: printe.codeexcepturllib2.URLError,e: printe.reasonelse: print"OK" 如果捕获到了HTTPError,则输出code,不会再处理URLError异常。如果发生的不是HTTPError,则会去捕获URLError异常,输出错误原因。
另外还可以加入 hasattr属性提前对属性进行判断,代码改写如下
Python
123456789101112 import urllib2 req = urllib2.Request('http://blog.csdn.net/cqcre')try: urllib2.urlopen(req)except urllib2.URLError, e: if hasattr(e,"code"): print e.code if hasattr(e,"reason"): print e.reasonelse: print "OK" 首先对异常的属性进行判断,以免出现属性输出报错的现象。
为什么要使用Cookie呢?
Cookie,指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)
比如说有些网站需要登录后才能访问某个页面,在登录之前,你想抓取某个页面内容是不允许的。那么我们可以利用Urllib2库保存我们登录的Cookie,然后再抓取其他页面就达到目的了。
1.Opener
当你获取一个URL你使用一个opener(一个urllib2.OpenerDirector的实例)。在前面,我们都是使用的默认的opener,也就是urlopen。它是一个特殊的opener,可以理解成opener的一个特殊实例,传入的参数仅仅是url,data,timeout。
如果我们需要用到Cookie,只用这个opener是不能达到目的的,所以我们需要创建更一般的opener来实现对Cookie的设置。
2.Cookielib
cookielib模块的主要作用是提供可存储cookie的对象,以便于与urllib2模块配合使用来访问Internet资源。 Cookielib模块非常强大,我们可以利用本模块的CookieJar类的对象来捕获cookie并在后续连接请求时重新发送,比如可以实现模拟登录 功能。该模块主要的对象有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
它们的关系:CookieJar —-派生—->FileCookieJar —-派生—–>MozillaCookieJar和LWPCookieJar
1)获取Cookie保存到变量
首先,我们先利用CookieJar对象实现获取cookie的功能,存储到变量中,先来感受一下
Python
12345678910111213 importurllib2importcookielib#声明一个CookieJar对象实例来保存cookiecookie=cookielib.CookieJar()#利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器handler=urllib2.HTTPCookieProcessor(cookie)#通过handler来构建openeropener=urllib2.build_opener(handler)#此处的open方法同urllib2的urlopen方法,也可以传入requestresponse=opener.open('http://www.baidu.com')foritemincookie: print'Name = '+item.name print'Value = '+item.value 我们使用以上方法将cookie保存到变量中,然后打印出了cookie中的值,运行结果如下
Python
12345678910 Name = BAIDUIDValue = B07B663B645729F11F659C02AAE65B4C:FG=1Name = BAIDUPSIDValue = B07B663B645729F11F659C02AAE65B4CName = H_PS_PSSIDValue = 12527_11076_1438_10633Name = BDSVRTMValue = 0Name = BD_HOMEValue = 0 2)保存Cookie到文件
在上面的方法中,我们将cookie保存到了cookie这个变量中,如果我们想将cookie保存到文件中该怎么做呢?这时,我们就要用到
FileCookieJar这个对象了,在这里我们使用它的子类MozillaCookieJar来实现Cookie的保存
Python
123456789101112131415 importcookielibimporturllib2 #设置保存cookie的文件,同级目录下的cookie.txtfilename='cookie.txt'#声明一个MozillaCookieJar对象实例来保存cookie,之后写入文件cookie=cookielib.MozillaCookieJar(filename)#利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器handler=urllib2.HTTPCookieProcessor(cookie)#通过handler来构建openeropener=urllib2.build_opener(handler)#创建一个请求,原理同urllib2的urlopenresponse=opener.open("http://www.baidu.com")#保存cookie到文件cookie.save(ignore_discard=True,ignore_expires=True) 3)从文件中获取Cookie并访问
那么我们已经做到把Cookie保存到文件中了,如果以后想使用,可以利用下面的方法来读取cookie并访问网站,感受一下
Python
12345678910111213 import cookielibimport urllib2 #创建MozillaCookieJar实例对象cookie = cookielib.MozillaCookieJar()#从文件中读取cookie内容到变量cookie.load('cookie.txt', ignore_discard=True, ignore_expires=True)#创建请求的requestreq = urllib2.Request("http://www.baidu.com")#利用urllib2的build_opener方法创建一个openeropener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))response = opener.open(req)print response.read() 设想,如果我们的 cookie.txt 文件中保存的是某个人登录百度的cookie,那么我们提取出这个cookie文件内容,就可以用以上方法模拟这个人的账号登录百度。
4)利用cookie模拟网站登录
下面我们以我们学校的教育系统为例,利用cookie实现模拟登录,并将cookie信息保存到文本文件中,来感受一下cookie大法吧!
注意:密码我改了啊,别偷偷登录本宫的选课系统 o(╯□╰)o
Python
1234567891011121314151617181920212223 importurllibimporturllib2importcookielib filename='cookie.txt'#声明一个MozillaCookieJar对象实例来保存cookie,之后写入文件cookie=cookielib.MozillaCookieJar(filename)opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))postdata=urllib.urlencode({'stuid':'201200131012','pwd':'23342321'})#登录教务系统的URLloginUrl='http://jwxt.sdu.edu.cn:7890/pls/wwwbks/bks_login2.login'#模拟登录,并把cookie保存到变量result=opener.open(loginUrl,postdata)#保存cookie到cookie.txt中cookie.save(ignore_discard=True,ignore_expires=True)#利用cookie请求访问另一个网址,此网址是成绩查询网址gradeUrl='http://jwxt.sdu.edu.cn:7890/pls/wwwbks/bkscjcx.curscopre'#请求访问成绩查询网址result=opener.open(gradeUrl)printresult.read() 以上程序的原理如下
创建一个带有cookie的opener,在访问登录的URL时,将登录后的cookie保存下来,然后利用这个cookie来访问其他网址。
如登录之后才能查看的成绩查询呀,本学期课表呀等等网址,模拟登录就这么实现啦,是不是很酷炫?
1.了解正则表达式
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
正则表达式是用来匹配字符串非常强大的工具,在其他编程语言中同样有正则表达式的概念,Python同样不例外,利用了正则表达式,我们想要从返回的页面内容提取出我们想要的内容就易如反掌了。
正则表达式的大致匹配过程是:1.依次拿出表达式和文本中的字符比较,2.如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。3.如果表达式中有量词或边界,这个过程会稍微有一些不同。
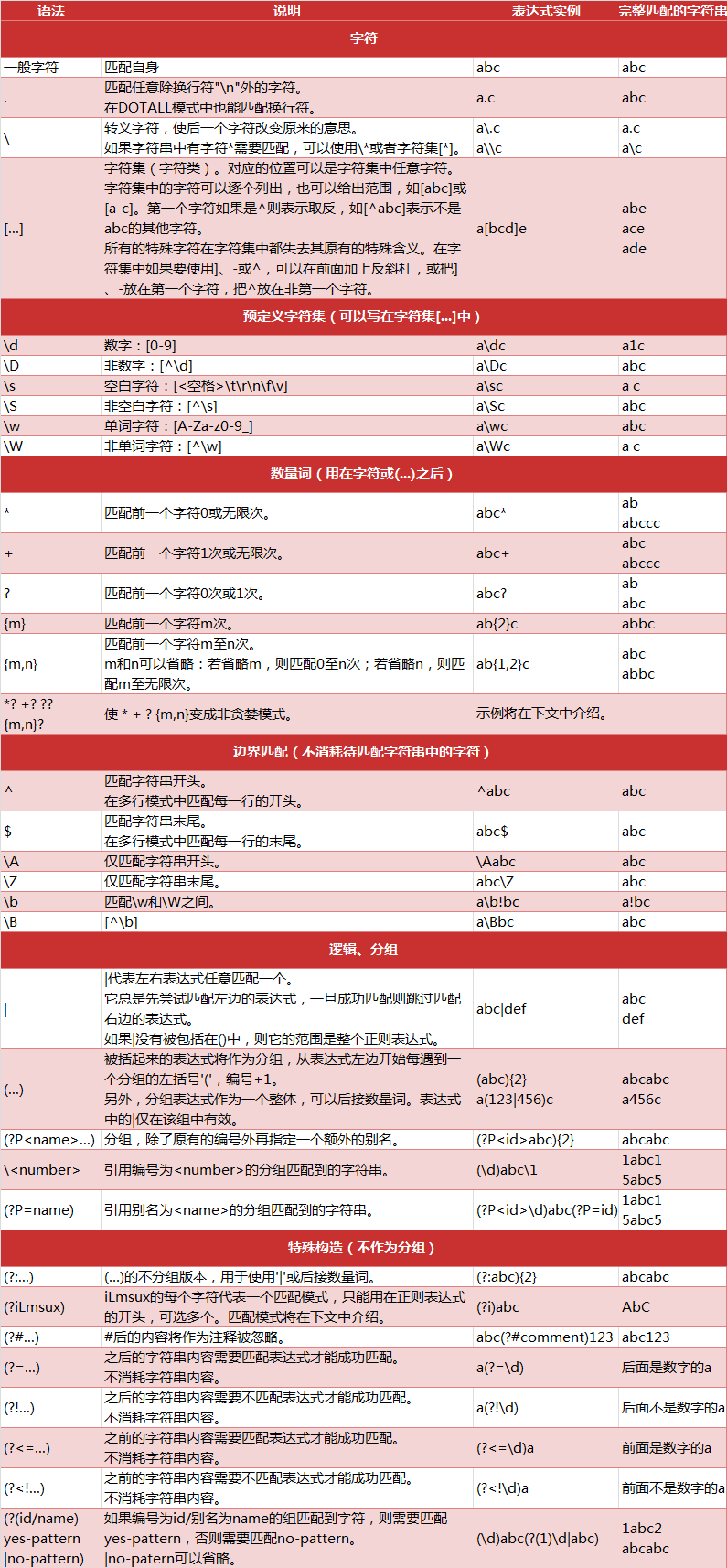
2.正则表达式的语法规则
下面是Python中正则表达式的一些匹配规则,图片资料来自CSDN
3.正则表达式相关注解
(1)数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字 符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式”ab*”如果用于查找”abbbc”,将找到”abbb”。而如果使用非贪婪的数量 词”ab*?”,将找到”a”。
注:我们一般使用非贪婪模式来提取。
(2)反斜杠问题
与大多数编程语言相 同,正则表达式里使用”/”作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符”/”,那么使用编程语言表示的正则表达式里将需要4个反 斜杠”////”:前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r”//”表示。同样,匹配一个数字的”//d”可以写成r”/d”。有了原生字符串,妈妈也不用担心是不是漏写了反斜杠,写出来的表达式也更直观勒。
4.Python Re模块
Python 自带了re模块,它提供了对正则表达式的支持。主要用到的方法列举如下
Python
12345678910 #返回pattern对象re.compile(string[,flag]) #以下为匹配所用函数re.match(pattern, string[, flags])re.search(pattern, string[, flags])re.split(pattern, string[, maxsplit])re.findall(pattern, string[, flags])re.finditer(pattern, string[, flags])re.sub(pattern, repl, string[, count])re.subn(pattern, repl, string[, count]) 在介绍这几个方法之前,我们先来介绍一下pattern的概念,pattern可以理解为一个匹配模式,那么我们怎么获得这个匹配模式呢?很简单,我们需要利用re.compile方法就可以。例如
Python
1 pattern=re.compile(r'hello') 在参数中我们传入了原生字符串对象,通过compile方法编译生成一个pattern对象,然后我们利用这个对象来进行进一步的匹配。
另外大家可能注意到了另一个参数 flags,在这里解释一下这个参数的含义:
参数flag是匹配模式,取值可以使用按位或运算符’|’表示同时生效,比如re.I | re.M。
可选值有:
Python
123456 • re.I(全拼:IGNORECASE): 忽略大小写(括号内是完整写法,下同) • re.M(全拼:MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图) • re.S(全拼:DOTALL): 点任意匹配模式,改变'.'的行为 • re.L(全拼:LOCALE): 使预定字符类 /w /W /b /B /s /S 取决于当前区域设定 • re.U(全拼:UNICODE): 使预定字符类 /w /W /b /B /s /S /d /D 取决于unicode定义的字符属性 • re.X(全拼:VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。 在刚才所说的另外几个方法例如 re.match 里我们就需要用到这个pattern了,下面我们一一介绍。
注:以下七个方法中的flags同样是代表匹配模式的意思,如果在pattern生成时已经指明了flags,那么在下面的方法中就不需要传入这个参数了。
(1)re.match(pattern, string[, flags])
这个方法将会从string(我们要匹配的字符串)的开头开始,尝试匹配pattern,一直向后匹配,如果遇到无法匹配的字符,立即返回 None,如果匹配未结束已经到达string的末尾,也会返回None。两个结果均表示匹配失败,否则匹配pattern成功,同时匹配终止,不再对 string向后匹配。下面我们通过一个例子理解一下
Python
123456789101112131415161718192021222324252627282930313233343536373839404142 __author__='CQC'# -*- coding: utf-8 -*- #导入re模块importre # 将正则表达式编译成Pattern对象,注意hello前面的r的意思是“原生字符串”pattern=re.compile(r'hello') # 使用re.match匹配文本,获得匹配结果,无法匹配时将返回Noneresult1=re.match(pattern,'hello')result2=re.match(pattern,'helloo CQC!')result3=re.match(pattern,'helo CQC!')result4=re.match(pattern,'hello CQC!') #如果1匹配成功ifresult1: # 使用Match获得分组信息 printresult1.group()else: print'1匹配失败!' #如果2匹配成功ifresult2: # 使用Match获得分组信息 printresult2.group()else: print'2匹配失败!' #如果3匹配成功ifresult3: # 使用Match获得分组信息 printresult3.group()else: print'3匹配失败!' #如果4匹配成功ifresult4: # 使用Match获得分组信息 printresult4.group()else: print'4匹配失败!' 运行结果
Python
1234 hellohello3匹配失败!hello 匹配分析
1.第一个匹配,pattern正则表达式为’hello’,我们匹配的目标字符串string也为hello,从头至尾完全匹配,匹配成功。
2.第二个匹配,string为helloo CQC,从string头开始匹配pattern完全可以匹配,pattern匹配结束,同时匹配终止,后面的o CQC不再匹配,返回匹配成功的信息。
3.第三个匹配,string为helo CQC,从string头开始匹配pattern,发现到 ‘o’ 时无法完成匹配,匹配终止,返回None
4.第四个匹配,同第二个匹配原理,即使遇到了空格符也不会受影响。
我们还看到最后打印出了result.group(),这个是什么意思呢?下面我们说一下关于match对象的的属性和方法Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
属性:1.string: 匹配时使用的文本。2.re: 匹配时使用的Pattern对象。3.pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。4.endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。5.lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。6.lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:1.group([group1, …]):获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。2.groups([default]):以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。3.groupdict([default]):返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。4.start([group]):返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。5.end([group]):返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。6.span([group]):返回(start(group), end(group))。7.expand(template):将匹配到的分组代入template中然后返回。template中可以使用/id或/g、/g引用分组,但不能使用编号0。/id与/g是等价的;但/10将被认为是第10个分组,如果你想表达/1之后是字符’0’,只能使用/g0。
下面我们用一个例子来体会一下
Python
123456789101112131415161718192021222324252627282930313233343536 # -*- coding: utf-8 -*-#一个简单的match实例 importre# 匹配如下内容:单词+空格+单词+任意字符m=re.match(r'(/w+) (/w+)(?P.*)','hello world!') print"m.string:",m.stringprint"m.re:",m.reprint"m.pos:",m.posprint"m.endpos:",m.endposprint"m.lastindex:",m.lastindexprint"m.lastgroup:",m.lastgroupprint"m.group():",m.group()print"m.group(1,2):",m.group(1,2)print"m.groups():",m.groups()print"m.groupdict():",m.groupdict()print"m.start(2):",m.start(2)print"m.end(2):",m.end(2)print"m.span(2):",m.span(2)printr"m.expand(r'/g /g/g'):",m.expand(r'/2 /1/3') ### output #### m.string: hello world!# m.re: # m.pos: 0# m.endpos: 12# m.lastindex: 3# m.lastgroup: sign# m.group(1,2): ('hello', 'world')# m.groups(): ('hello', 'world', '!')# m.groupdict(): {'sign': '!'}# m.start(2): 6# m.end(2): 11# m.span(2): (6, 11)# m.expand(r'/2 /1/3'): world hello! (2)re.search(pattern, string[, flags])
search方法与match方法极其类似,区别在于match()函数只检测re是不是在string的开始位置匹配,search()会扫描整个string查找匹配,match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回None。同样,search方法的返回对象同样match()返回对象的方法和属性。我们用一个例子感受一下
Python
12345678910111213 #导入re模块import re # 将正则表达式编译成Pattern对象pattern = re.compile(r'world')# 使用search()查找匹配的子串,不存在能匹配的子串时将返回None# 这个例子中使用match()无法成功匹配match = re.search(pattern,'hello world!')if match: # 使用Match获得分组信息 print match.group()### 输出 #### world (3)re.split(pattern, string[, maxsplit])
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。我们通过下面的例子感受一下。
Python
1234567 importre pattern=re.compile(r'/d+')printre.split(pattern,'one1two2three3four4') ### 输出 #### ['one', 'two', 'three', 'four', ''] (4)re.findall(pattern, string[, flags])
搜索string,以列表形式返回全部能匹配的子串。我们通过这个例子来感受一下
Python
1234567 import re pattern = re.compile(r'/d+')print re.findall(pattern,'one1two2three3four4') ### 输出 #### ['1', '2', '3', '4'] (5)re.finditer(pattern, string[, flags])
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。我们通过下面的例子来感受一下
Python
12345678 importre pattern=re.compile(r'/d+')forminre.finditer(pattern,'one1two2three3four4'): printm.group(), ### 输出 #### 1 2 3 4 (6)re.sub(pattern, repl, string[, count])
使用repl替换string中每一个匹配的子串后返回替换后的字符串。当repl是一个字符串时,可以使用/id或/g、/g引用分组,但不能使用编号0。当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。count用于指定最多替换次数,不指定时全部替换。
Python
123456789101112131415 import re pattern = re.compile(r'(/w+) (/w+)')s = 'i say, hello world!' print re.sub(pattern,r'/2 /1', s) def func(m): return m.group(1).title() + ' ' + m.group(2).title() print re.sub(pattern,func, s) ### output #### say i, world hello!# I Say, Hello World! (7)re.subn(pattern, repl, string[, count])
返回 (sub(repl, string[, count]), 替换次数)。
Python
123456789101112131415 importre pattern=re.compile(r'(/w+) (/w+)')s='i say, hello world!' printre.subn(pattern,r'/2 /1',s) deffunc(m): returnm.group(1).title()+' '+m.group(2).title() printre.subn(pattern,func,s) ### output #### ('say i, world hello!', 2)# ('I Say, Hello World!', 2) 5.Python Re模块的另一种使用方式
在上面我们介绍了7个工具方法,例如match,search等等,不过调用方式都是 re.match,re.search的方式,其实还有另外一种调用方式,可以通过pattern.match,pattern.search调用,这样 调用便不用将pattern作为第一个参数传入了,大家想怎样调用皆可。
函数API列表
Python
1234567 match(string[,pos[,endpos]])|re.match(pattern,string[,flags])search(string[,pos[,endpos]])|re.search(pattern,string[,flags])split(string[,maxsplit])|re.split(pattern,string[,maxsplit])findall(string[,pos[,endpos]])|re.findall(pattern,string[,flags])finditer(string[,pos[,endpos]])|re.finditer(pattern,string[,flags])sub(repl,string[,count])|re.sub(pattern,repl,string[,count])subn(repl,string[,count])|re.sub(pattern,repl,string[,count])
新闻热点






疑难解答