前段时间想更深入了解下java多线程相关的知识,对Java多线程有一个全面的认识,所以想找一本Java多线程相关的书籍来阅读,最后我选择了《Java并发编程实战》这本个人认为还算相当不错,至于为什么选择它,下面有介绍。
中文书名:《Java并发编程实战》 英文书名:《Java Concurrency in PRactice》 作者:Brian Goetz / Tim Peierls / Joshua Bloch / Joseph Bowbeer / David Holmes / Doug Lea 译者:童云兰 出版社: 机械工业出版社华章公司 购买可以在各大电商网站搜索书名购买,请支持正版 
1、亚马逊排名考前,评论多评分也不错; 2、很多java程序员必看数据整理里面的书单之一; 3、豆瓣评分9.0; 4、作者都很牛B。
《Java并发编程实战》深入浅出地介绍了Java线程和并发,是一本完美的Java并发参考手册。书中从并发性和线程安全性的基本概念出发,介绍了如何使用类库提供的基本并发构建块,用于避免并发危险、 构造线程安全的类及验证线程安全的规则,如何将小的线程安全类组合成更大的线程安全类,如何利用线程来提高并发应用程序的吞吐量,如何识别可并行执行的任务,如何提高单线程子系统的响应性,如 何确保并发程序执行预期任务,如何提高并发代码的性能和可伸缩性等内容,最后介绍了一些高级主题,如显式锁、原子变量、非阻塞算法以及如何开发自定义的同步工具类。 《Java并发编程实战》适合Java程序开发人员阅读。
本书作者都是Java Community Process JSR 166专家组(并发工具)的主要成员,并在其他很多JCP专家组里任职。Brian Goetz有20多年的软件咨询行业经验,并著有至少75篇关于Java开发的文章。 Tim Peierls是“现代多处理器”的典范,他在BoxPop.biz、唱片艺术和戏剧表演方面也颇有研究。Joseph Bowbeer是一个Java ME专家,他对并发编程的兴趣始于Apollo计算机时代。David Holmes是 《The Java Programming Language》一书的合著者,任职于Sun公司。Joshua Bloch是Google公司的首席Java架构师,《Effective Java》一书的作者,并参与著作了《Java Puzzlers》。Doug Lea 是《Concurrent Programming》一书的作者,纽约州立大学 Oswego分校的计算机科学教授。 备注:缩写的解释如下 - Java Community Process(JCP) wiki 英文介绍 wiki 中文介绍 - Java Specification Requests(JSR)
进程与线程的解释
总核数 = 物理CPU个数 X 每颗物理CPU的核数 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数 同一进程中的多条线程将共享该进程中的全部系统资源,如虚拟地址空间,文件描述符和信号处理等等。 但同一进程中的多个线程有各自的调用栈(call stack),自己的寄存器环境(register context),自己的线程本地存储(thread-local storage)。 大量用户线程复用少量的轻权进程(内核线程)进程才是程序(那些指令和数据)的真正运行实例。若干进程有可能与同一个程序相关系,且每个进程皆可以同步(循序)或异步(平行)的方式独立运行。
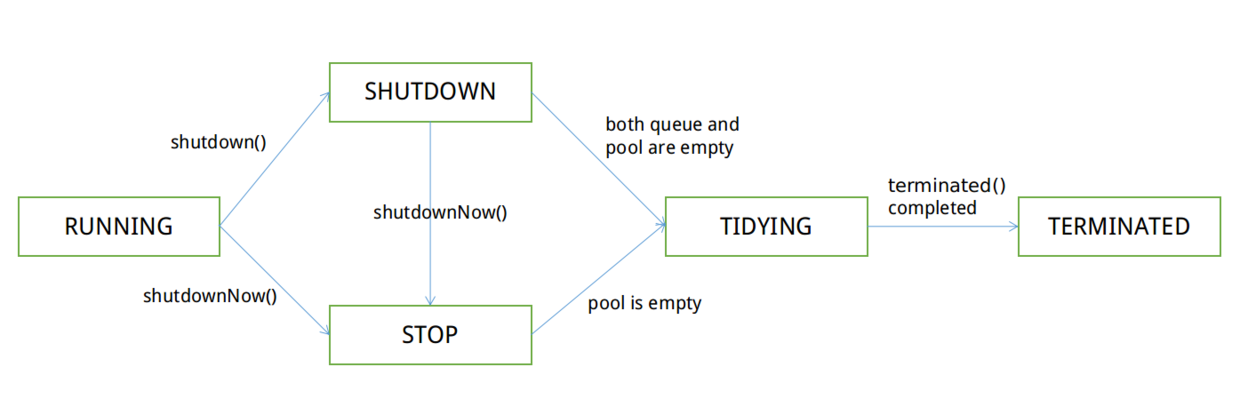
 进程状态的转换参考下面两篇博文 进程的状态转换 linux进程状态解析
进程状态的转换参考下面两篇博文 进程的状态转换 linux进程状态解析
了解操作系统的基本原理对多线程的理解也是至关重要的,下面的这篇博文对操作系统的阐述比较形象易懂。 操作系统基本原理 总结如下: - 以多进程形式,允许多个任务同时运行 - 以多线程形式,允许单个任务分成不同的部分运行 - 提供协调机制,一方面防止进程之间和线程之间产生冲突,另一方面允许进程之间和线程之间共享资源
早期的计算机中不包含操作系统,它们从头到尾执行一个程序,程序可访问计算机上面的所有资源。这样会造成极大的资源浪费。 操作系统的出现使得计算机可以每次运行多个程序,操作系统为每个进程分配资源。 之所以在计算机中加入操作系统来实现多个程序通知执行,主要基于下面三个原因。 - 资源利用率 - 公平性 - 便利性
那么引入多线程会有哪些优势呢? - 发挥多处理器的强大能力 - 使建模更具简单性 - 异步事件的简化处理 不同类型的任务、负责自己的工作流。log4j的日志异步输出,消息监控功能、这样的线程可以专注自己的任务。
线程也带来了一些风险 - 安全性问题 - 活跃性问题 - 性能问题
什么是线程安全性?该书给出了自己的定义:当多个线程访问某个类时,这个类始终都能表现正确的行为。
java中与对象共享相关的关键词:Volatile、ThreadLocal、Final Volatile 变量具有 synchronized 的可见性特性,但是不具备原子特性。线程为了提高效率,将某成员变量(如A)拷贝了一份(如B),线程中对A的访问其实访问的是B。只在某些动作时才进行A和B的同步。因此存在A和B不一致的情况。volatile就是用来避免这种情况的。volatile告诉jvm, 它所修饰的变量不保留拷贝,直接访问主内存中的(也就是上面说的A)
监视器是操作系统实现同步的重要基础概念,同样它也用在JAVA的线程同步中监视器可以看做是经过特殊布置的建筑,这个建筑有一个特殊的房间,该房间通常包含一些数据和代码,但是一次只能一个消费者(thread)使用此房间,当一个消费者(线程)使用了这个房间,首先他必须到一个大厅(Entry Set)等待,调度程序将基于某些标准(e.g. FIFO)将从大厅中选择一个消费者(线程),进入特殊房间,如果这个线程因为某些原因被“挂起”,它将被调度程序安排到“等待房间”,并且一段时间之后会被重新分配到特殊房间,按照上面的线路,这个建筑物包含三个房间,分别是“特殊房间”、“大厅”以及“等待房间”。 简单来说,监视器用来监视线程进入这个特别房间,他确保同一时间只能有一个线程可以访问特殊房间中的数据和代码。(synchronized) 

构建高效可用的缓存
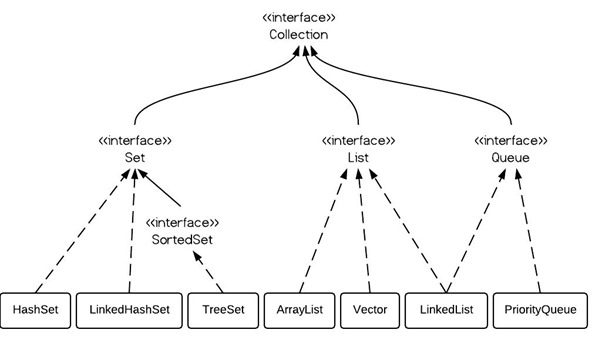
java中早期的同步容器有: Collections.synchronizedXxx (早期jdk)、Vector、Hashtable java5.0版本之后开始出现效率更高的并发容器: java.util.concurrent(Java5.0)、ConcurrentHashMap、CopyOnWriteArrayList、 BlockingQueue
 从图可以看出HashTable 和 ConcurrentHashMap两者最大的差异在锁的粒度,HashTable 的锁是对整个散列表的全局锁,而ConcurrentHashMap的锁粒度更细。 ConcurrentHashMap 锁的粒度是–Segment(桶)。 查看ConcurrentHashMap 的源码,get() 和 put()方法。
从图可以看出HashTable 和 ConcurrentHashMap两者最大的差异在锁的粒度,HashTable 的锁是对整个散列表的全局锁,而ConcurrentHashMap的锁粒度更细。 ConcurrentHashMap 锁的粒度是–Segment(桶)。 查看ConcurrentHashMap 的源码,get() 和 put()方法。
其中两个内置类需要特别注意下,这两个是构建分段加锁和性能提升的关键点。 HashEntry: 可以看到除了value不是final的,其它值都是final的,这意味着不能从hash链的中间或尾部添加或删除节点,因为这需要修改next 引用值,所有的节点的修改只能从头部开始。对于put操作,可以一律添加到Hash链的头部。但是对于remove操作,可能需要从中间删除一个节点,这就需要将要删除节点的前面所有节点整个复制一遍,最后一个节点指向要删除结点的下一个结点。这在讲解删除操作时还会详述。为了确保读操作能够看到最新的值,将value设置成volatile,这避免了加锁。 Segment Hash表的一个很重要方面就是如何解决hash冲突,ConcurrentHashMap 和HashMap使用相同的方式,都是将hash值相同的节点放在一个hash链中。与HashMap不同的是,ConcurrentHashMap使用多个子Hash表,也就是段(Segment)。
 这个图是不是很熟悉? Yield是一个静态的原生(native)方法 Yield告诉当前正在执行的线程把运行机会交给线程池中拥有相同优先级的线程。 Yield不能保证使得当前正在运行的线程迅速转换到可运行的状态 它仅能使一个线程从运行状态转到可运行状态,而不是等待或阻塞状态 join()运行着的线程将阻塞直到这个线程实例完成了执行 关键词:start、notify、yield、blocked、waiting、sleep、join
这个图是不是很熟悉? Yield是一个静态的原生(native)方法 Yield告诉当前正在执行的线程把运行机会交给线程池中拥有相同优先级的线程。 Yield不能保证使得当前正在运行的线程迅速转换到可运行的状态 它仅能使一个线程从运行状态转到可运行状态,而不是等待或阻塞状态 join()运行着的线程将阻塞直到这个线程实例完成了执行 关键词:start、notify、yield、blocked、waiting、sleep、join
闭锁的作用相当与一扇门:在闭锁到达结束状态之前,这扇门一直关闭,没有任何线程能通过,当达到状态是,这扇门会打开允许所有线程通过。 闭锁举例:TestHarness 、Preloader
public class TestHarness { public long timeTasks(int nThreads, final Runnable task) throws InterruptedException { final CountDownLatch startGate = new CountDownLatch(1); final CountDownLatch endGate = new CountDownLatch(nThreads); for (int i = 0; i < nThreads; i++) { Thread t = new Thread() { public void run() { try { startGate.await(); //等待 try { task.run(); } finally { endGate.countDown();//执行完成之后释放 } } catch (InterruptedException ignored) { } } }; t.start(); } long start = System.nanoTime(); startGate.countDown(); //释放线程 endGate.await();//等待释放 long end = System.nanoTime(); return end - start; }}栅栏和闭锁和类似,闭锁是等待事件,栅栏是等待其他线程 栅栏举例:CellularAutomata
public class CellularAutomata { private final Board mainBoard; private final CyclicBarrier barrier; private final Worker[] workers; public CellularAutomata(Board board) { this.mainBoard = board; int count = Runtime.getRuntime().availableProcessors(); this.barrier = new CyclicBarrier(count, new Runnable() { public void run() { mainBoard.commitNewValues(); }}); this.workers = new Worker[count]; for (int i = 0; i < count; i++) workers[i] = new Worker(mainBoard.getSubBoard(count, i)); } private class Worker implements Runnable { private final Board board; public Worker(Board board) { this.board = board; } public void run() { while (!board.hasConverged()) { for (int x = 0; x < board.getMaxX(); x++) for (int y = 0; y < board.getMaxY(); y++) board.setNewValue(x, y, computeValue(x, y)); try { barrier.await(); } catch (InterruptedException ex) { return; } catch (BrokenBarrierException ex) { return; } } } private int computeValue(int x, int y) { // Compute the new value that goes in (x,y) return 0; } } public void start() { for (int i = 0; i < workers.length; i++) new Thread(workers[i]).start(); mainBoard.waitForConvergence(); } interface Board { int getMaxX(); int getMaxY(); int getValue(int x, int y); int setNewValue(int x, int y, int value); void commitNewValues(); boolean hasConverged(); void waitForConvergence(); Board getSubBoard(int numPartitions, int index); }}个人觉得在项目中可以用到最多的就是FutureTask,下面举例来说明试用FutureTask的好处。下面是一个缓存类的设计。
public class Memoizer1 <A, V> implements Computable<A, V> { @GuardedBy("this") private final Map<A, V> cache = new HashMap<A, V>(); private final Computable<A, V> c; public Memoizer1(Computable<A, V> c) { this.c = c; } /** * 带来了性能问题,每次只有一个线程可以执行该方法 */ public synchronized V compute(A arg) throws InterruptedException { V result = cache.get(arg); if (result == null) { result = c.compute(arg); cache.put(arg, result); } return result; }} 上面Memoizer1的设计是非常糟糕,带来了性能问题,每次只有一个线程可以执行该方法.如上图所示,下面对这个对象进行改进。
上面Memoizer1的设计是非常糟糕,带来了性能问题,每次只有一个线程可以执行该方法.如上图所示,下面对这个对象进行改进。
 大量请求同时调用时还是会有比较严重的性能问题,c.compute(arg)的计算结果时间较长时,只要结果还未计算出来,每个请求线程都会对结果重新计算一次,如上图所示。下面引入TaskFutrue来实现。
大量请求同时调用时还是会有比较严重的性能问题,c.compute(arg)的计算结果时间较长时,只要结果还未计算出来,每个请求线程都会对结果重新计算一次,如上图所示。下面引入TaskFutrue来实现。
 该方法大大减少了并发多次计算的过程,但是还是会有可以重复计算,在获取Future f = cache.get(arg)之后判断if (f == null) 与put(arg, ft) 并不是原子性的操作,在这期间可能会计算多次,如上图所示。 最终的解决方案引入了
该方法大大减少了并发多次计算的过程,但是还是会有可以重复计算,在获取Future f = cache.get(arg)之后判断if (f == null) 与put(arg, ft) 并不是原子性的操作,在这期间可能会计算多次,如上图所示。 最终的解决方案引入了 ConcurrentMap.putIfAbsent(arg, ft)方法,只在不存在的时候才写放入Future去计算。 最终的优化解决方案如下:
个人觉得第一部分是非常重要的,看书的时候结合代码和示例,去翻阅与之相关的知识融会贯通,举一反三。通过这部分我们可以对java的多线程概念和相关的工具包有比较全面的了解,后面结合实际项目灵活运用好,遵循部分原则避免出现常见的异常和问题。
新闻热点






疑难解答