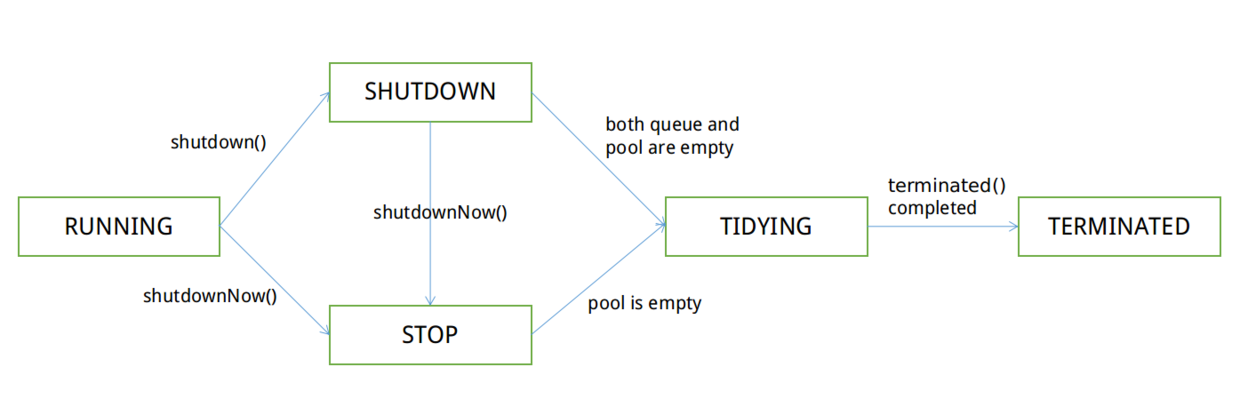
1.capacity
1.capacity这个状态变量表示缓冲区的容量大小,这个值是固定不变的,指向缓冲区底层数组的最后一个位置; 2. position在读模式下,该值表示下一个读取数据的位置,通过flip方法切换为读模式时,该值为指向缓存区第一个数据位置; 在写模式下,该值表示下一个要写入数据的位置,通过clear方法切换为写模式时,该值指向缓存区第一个数据位置;
3. limit这个状态变量表示缓存区可读/写的最大位置:在写模式下,该值等于capacity;在读模式下,该值等于切换为读模式时position的位置,表示可读数据位置;
ByteBuffer buffer = ByteBuffer.allocate(1024);allocate方法分配一个指定大小的底层数组,并包装为一个缓存缓冲区对象; 另外还可以通过一个现有的数组直接包装为缓冲区:byte array[] = new byte[1024];ByteBuffer buffer = ByteBufer.wrap(array);注意:通过这种方式创建的缓冲区,因为有底层数组的实际引用,可以通过array数组直接修改数据;缓冲区分片
缓冲区可以使用slice方法创建一个子缓冲区,即是创建一个新的缓冲区,但是共享原缓冲区的一部分数据,使用下面实例代码说明slice方法:public static void main(String[] args) { //创建一个容量为10的字节缓冲区 ByteBuffer buffer = ByteBuffer.allocate(10); //设置缓冲区中的数据 for (int i=0; i<buffer.capacity(); ++i) { buffer.put(i, (byte) i); } //手动设置状态变量,创建一个包含原缓冲区index3-6的子缓冲区(分片) buffer.position(3); buffer.limit(7); ByteBuffer slice = buffer.slice(); //对新创建的子缓冲区中每个数据乘10操作 for (int i=0; i<slice.capacity(); ++i) { byte b = slice.get(i); b*=10; slice.put(i, b); } //重设状态变量 buffer.position(0); buffer.limit(buffer.capacity()); while (buffer.hasRemaining()) { System.out.PRintln(buffer.get()); } }输出的结果为:01230405060789从实例代码可以看出,slice方法从position和limit变量间创建分片,并且分片数据和原缓冲区是共享的; 分片对于方法调用是有很大作用的,对调用的方法,如果只想方法处理其中一部分数据,可以通过slice传递一个子缓冲区作为参数;只读缓冲区
只读缓冲区只能用于读取数据,不能写入数据;通过缓冲区的asReadOnlyBuffer创建一个新的缓冲区,它与原缓冲区共享数据,但是是只读的; 只读缓冲区主要用于数据的保护,比如:调用一个方法是,可能需要保证缓冲区的数据不被修改,那就可以创建一个只读缓冲区作为参数;
新闻热点






疑难解答