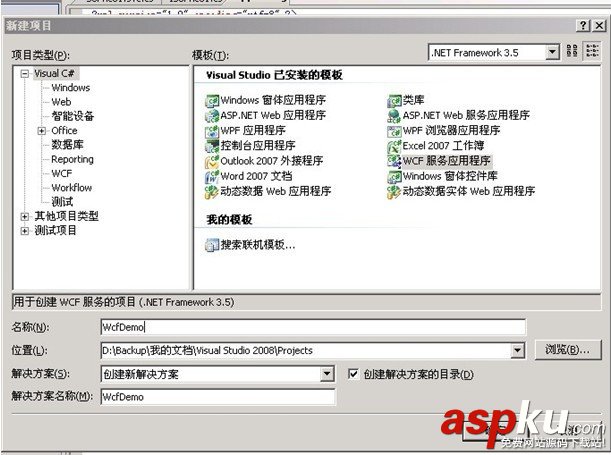
本文实例讲述了C#提取网页中超链接link和text部分的方法。分享给大家供大家参考,具体如下:
string s = "..";Regex re = new Regex(@"<a[^>]*href=(""(?<href>[^""]*)""|'(?<href>[^']*)'|(?<href>[^/s>]*))[^>]*>(?<text>.*?)</a>", RegexOptions.IgnoreCase | RegexOptions.Singleline);Match m = re.Match(s);if(m.Success){ string link = m.Groups["href"].Value; string text = Regex.Replace(m.Groups["text"].Value,"<[^>]*>",""); Console.WriteLine("link:{0}/ntext:{1}", link, text);} 希望本文所述对大家C#程序设计有所帮助。