本文实例讲述了Python使用py2neo操作图数据库neo4j的方法。分享给大家供大家参考,具体如下:
图:数据结构中的图由节点和其之间的边组成。节点表示一个实体,边表示实体之间的联系。
图数据库:以图的结构存储管理数据的数据库。其中一些数据库将原生的图结构经过优化后直接存储,即原生图存储。还有一些图数据库将图数据序列化后保存到关系型或其他数据库中。
之所以使用图数据库存储数据是因为它在处理实体之间存在复杂关系的数据具有很大的优势。使用传统的关系型数据库在处理数据之间的关系时其实很不方便。例如查询选修一个课程的同学时需要join两个表,查询选修某个课程的同学还选修什么课程,这就需要两次join操作,当涉及到十分复杂的关系以及庞大的数据量时,关系型数据库效率十分低下。而通过图存储,可以通过节点之间的边十分便捷地查询到结果。
图模型:
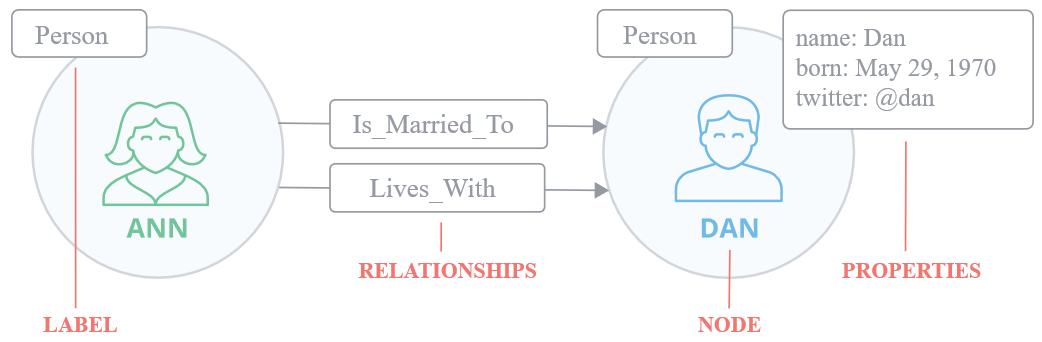
节点(Node)是主要的数据元素,表示一个实体。
属性(Properties)用于描述实体的特征,以键值对的方式表示,其中键是字符串,可以对属性创建索引和约束。
关系(Relationships)表示实体之间的联系,关系具有方向,实体之间可以有多个关系,关系也可以具有属性
标签(Label)用于将实体分类,一个实体可以具有多个标签,对标签进行索引可以加速查找
Neo4j是目前最流行的图数据库,它采用原生图存储,在windows中下载安装访问如下地址https://neo4j.com/download/community-edition/。在Linux下通过如下命令下载解压
curl -O http://dist.neo4j.org/neo4j-community-3.4.5-unix.tar.gztar -axvf neo4j-community-3.4.5-unix.tar.gz
修改配置文件conf/neo4j.conf
# 修改第22行load csv时l路径,在前面加个#,可从任意路径读取文件#dbms.directories.import=import# 修改35行和36行,设置JVM初始堆内存和JVM最大堆内存# 生产环境给的JVM最大堆内存越大越好,但是要小于机器的物理内存dbms.memory.heap.initial_size=5gdbms.memory.heap.max_size=10g# 修改46行,可以认为这个是缓存,如果机器配置高,这个越大越好dbms.memory.pagecache.size=10g# 修改54行,去掉改行的#,可以远程通过ip访问neo4j数据库dbms.connectors.default_listen_address=0.0.0.0# 默认 bolt端口是7687,http端口是7474,https关口是7473,不修改下面3项也可以# 修改71行,去掉#,设置http端口为7687,端口可以自定义,只要不和其他端口冲突就行#dbms.connector.bolt.listen_address=:7687# 修改75行,去掉#,设置http端口为7474,端口可以自定义,只要不和其他端口冲突就行dbms.connector.http.listen_address=:7474# 修改79行,去掉#,设置http端口为7473,端口可以自定义,只要不和其他端口冲突就行dbms.connector.https.listen_address=:7473# 去掉#,允许从远程url来load csvdbms.security.allow_csv_import_from_file_urls=true# 修改250行,去掉#,设置neo4j-shell端口,端口可以自定义,只要不和其他端口冲突就行dbms.shell.port=1337# 修改254行,设置neo4j可读可写dbms.read_only=false
在bin目录下执行 ./neo4j start,启动服务,在浏览器http://服务器ip地址:7474/browser/可以看到neo4j的可视化界面
py2neo是一个社区第三方库,通过它可以更为便捷地使用python来操作neo4j
安装py2neo:pip install py2neo,我安装的版本是4.3.0
创建节点和它们之间的关系,注意在使用下面的py2neo相关类之前首先需要import导入:
新闻热点






疑难解答