在学习redis过程中提到一个缓存击穿的问题, 书中参考的解决方案之一是使用布隆过滤器, 那么就有必要来了解一下什么是布隆过滤器。在参考了许多博客之后, 写个总结记录一下。
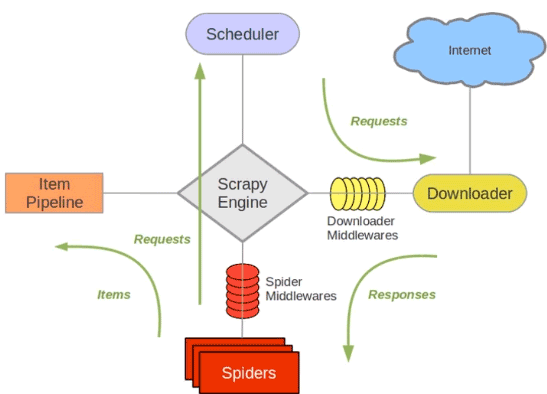
一、布隆过滤器简介
什么是布隆过滤器?
本质上布隆过滤器( BloomFilter )是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
布隆过滤器原理
布隆过滤器内部维护一个bitArray(位数组), 开始所有数据全部置 0 。当一个元素过来时,能过多个哈希函数(hash1,hash2,hash3....)计算不同的在哈希值,并通过哈希值找到对应的bitArray下标处,将里面的值 0 置为 1 。 需要说明的是,布隆过滤器有一个误判率的概念,误判率越低,则数组越长,所占空间越大。误判率越高则数组越小,所占的空间越小。
下面以网址为例来进行说明, 例如布隆过滤器的初始情况如下图所示:
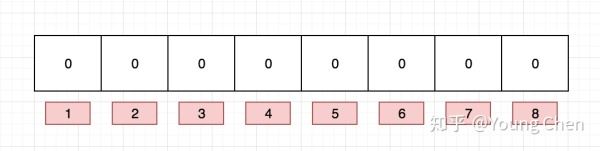
现在我们需要往布隆过滤里中插入baidu这个url,经过3个哈希函数的计算,hash值分别为1,4,7,那么我们就需要对布隆过滤器的对应的bit位置1, 就如图下所示:
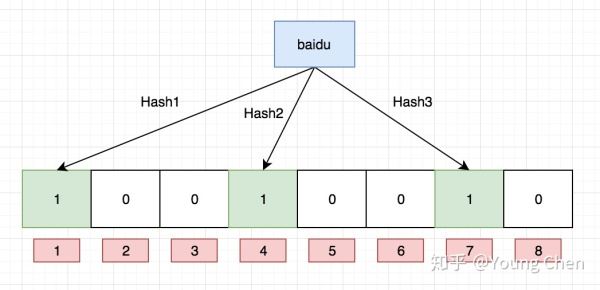
接下来,需要继续往布隆过滤器中添加tencent这个url,然后它计算出来的hash值分别3,4,8,继续往对应的bit位置1。这里就需要注意一个点, 上面两个url最后计算出来的hash值都有4,这个现象也是布隆不能确认某个元素一定存在的原因,最后如下图所示:
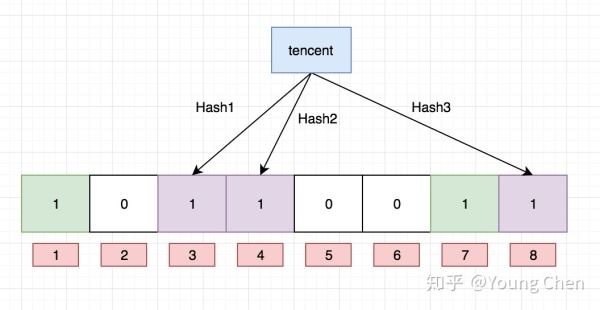
布隆过滤器的查询也很简单,例如我们需要查找python,只需要计算出它的hash值, 如果该值为2,4,7,那么因为对应bit位上的数据有一个不为1, 那么一定可以断言python不存在,但是如果它计算的hash值是1,3,7,那么就只能判断出python可能存在,这个例子就可以看出来, 我们没有存入python,但是由于其他key存储的时候返回的hash值正好将python计算出来的hash值对应的bit位占用了,这样就不能准确地判断出python是否存在。
因此, 随着添加的值越来越多, 被占的bit位越来越多, 这时候误判的可能性就开始变高,如果布隆过滤器所有bit位都被置为1的话,那么所有key都有可能存在, 这时候布隆过滤器也就失去了过滤的功能。至此,选择一个合适的过滤器长度就显得非常重要。
从上面布隆过滤器的实现原理可以看出,它不支持删除, 一旦将某个key对应的bit位置0,可能会导致同样bit位的其他key的存在性判断错误。
布隆过滤器的准确性
布隆过滤器的核心思想有两点:
多个hash,增大随机性,减少hash碰撞的概率扩大数组范围,使hash值均匀分布,进一步减少hash碰撞的概率。
虽然布隆过滤器已经尽可能的减小hash碰撞的概率了,但是,并不能彻底消除,因此正如上面的小例子所举的小例子的结果来看, 布隆过滤器只能告诉我们某样东西一定不存在以及它可能存在。
关于布隆过滤器的数组大小以及相应的hash函数个数的选择, 可以参考网上的其他博客或者是这个维基百科上对应词条上的结果: Probability of false positives .

新闻热点






疑难解答