字符“/”是转义符,用于转换一些特殊字符的含义。这些特殊字符有:
字符“ " ”用于标识字符串的开始和结尾。要使该字符在一个字符串中作为普通字符出现,则需要在它前面加一个字符“ / ”。例如要在一个字符串中包含以下内容:
"tom"是一个男孩的名字
则必须将该字符串描述为:
string:= "/"tom/"是一个男孩的名字"
如图3-33所示。
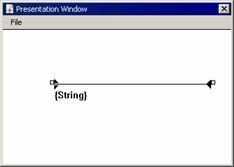
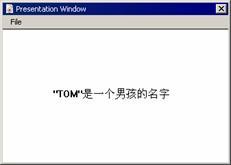
图3-33 显示双引号
如果需要【演示】窗口中显示出字符“ / ”,也必须使用转义符,例如要在字符串中包括一个合法的路径:
c:/program files/macromedia/authorware 7
则必须将路径字符串描述为:
"c://program files//macromedia//authorware 7"。
如果需要在字符串中包含回车符,可以向字符串中插入“/r”或系统变量return(两者作用相同)。例如字符串变量
string:= "authorware 7"^return^"is"^"/r"^"coming"
嵌入文本对象之后的显示结果如图3-34所示。
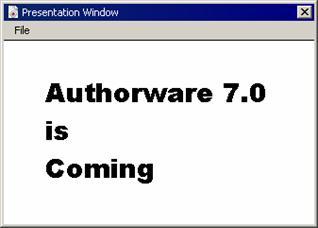
图3-34 在字符串中插入回车符
如果需要在字符串中包含制表符,可以向字符串中插入“/t”或系统变量tab。
字符“{}”可以在字符串中直接使用。但如果需要在文本对象输入并显示该字符,必须以“/{”方式输入,否则authorware会认为包含在花括号之中的内容是一个表达式并对其进行计算。
通过使用行分隔符“/r”,在一个字符串变量中可以包含多行字符。但是在字符串变量作为文本对象显示在【演示】窗口中时,情况会产生一些微妙的变化。
在文本对象中,由"/r"分隔的内容称为段落(paragraph)。如果文本对象的宽度不足以将段落内容显示在同一行(line)上,段落被自动分别多行显示,此时字符串变量中的行与文本对象中的行就失去了对应关系。
例如在变量string中含有以下内容:
"authorware is the leading visual authoring tool for creating rich-media e-learning applications for delivery on corporate networks, cd/dvd, and the web./rdevelop accessible applications that comply with learning management system (lms) standards. "
将string嵌入到文本对象中之后,其显示结果如图3-35所示。原先仅仅2行的内容在文本对象中被划分为2段共6行。单击“web”这一单词,然后在【变量】面板窗口中观察系统变量lineclicked和paragraphclicked的值,可以发现authorware认为当前被单击的行是第4行,被单击的段落是第1段。但是无法通过函数getline(string, 4)得到任何内容,因为authorware认为变量string中仅仅包含2行内容。
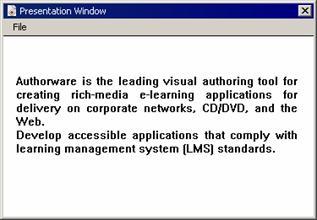
图3-35 【演示】窗口中的文本对象
理解这一点对于利用文本对象开展与用户之间的交互过程是至关重要的。
在aws中,对行的处理方式非常灵活。通过定义新的行分隔符,可以将同一行中的字符划分为逻辑上不同的行。例如变量string中包含了位于同一行中的两句问候语:
"what's your name ? how old are you ?"
将字符"?"定义为新的行分隔符,就可以从逻辑上将该字符串划分为2行,通过函数getline(string,2,2,"?")可以获取第2句问候语的内容"how old are you"。
aws提供的character类系统函数主要用于对字符串进行处理,以下对其中一些常用函数进行简要介绍。
返回ascⅱ码(数值key)对应的字符。例如char(65)返回"a",char(97)返回"a"。大写英文字母的ascⅱ码范围是65至90,小写英文字母的ascⅱ码范围是97至122。
返回字符串string包含的字符个数。
返回与指定字符对应的ascⅱ码,例如code(" ")返回空格的ascⅱ码32。参数character可以是字符,也可以是键名。如果是键名,例如tab或enter,则不使用双引号。
在字符串string中查找pattern指定的字符串,并返回第一个被匹配字符串的首字符在string中的位置。如果pattern指定的字符串未被找到,该函数返回0。例如查找路径字符串中的字符“/”,可以使用:
result:= find("////", "c://windows//system32") --变量result的值为3
该函数严格区分大小写,并且支持使用通配符:"*"代表0个或多个字符,"?"代表单个字符,"/"代表转义符。如果需要针对通配字符进行查找,必须使用转义符,例如:
result:= find("/?", "what's your name ? how old are you ?") --变量result的值为18
与函数find功能相似,但是查找方向是从右向左。例如
result:= find("////", "c://windows//system32") --变量result的值为11
result:= find("/?", "what's your name ? how old are you ?") --变量result的值为36
返回字符串string中的第n行(或第n行到m行)的内容。return(回车)是默认的行分隔符,但可以通过参数delim重新指定行分隔符。
返回字符串string中第n个单词。由空格、回车、tab分隔的字符串被authorware认为是单词。例如
result:= getword(2, "what's your name ? ") --变量result的值为"your"
返回字符串string中的总行数,其中不包含字符串尾部的空行。return(回车)是默认的行分隔符,但可以通过参数delim重新指定行分隔符。
返回与string对应的字符串,其中所有字母全部转换为小写字母。例如
result:= lowercase ("what's your name ?") --变量result的值为"what's your name ?"
将value从当前数据类型转换为字符串类型。例如
result:= string(65) --变量result的值为"65"
返回字符串string的部分内容,起始位置和结束位置由参数first和last指定。例如
result:= substr ("what's your name ?", 8, 11) --变量result的值为"your"
返回与string对应的字符串,其中所有字母全部转换为大写字母。例如
result:= uppercase ("what's your name ?") --变量result的值为"what's your name ?"
返回字符串string中包含的单词总数。例如
result:= wordcount("what's your name ?") --变量result的值为4
以下介绍由这些字符串处理函数构造的常用字符串处理过程,代码的注释部分解释了相应程序语句的作用。
以下过程将变量string中的字符顺序进行反转。
string:="authorware 7 is coming"
reverse:="" --用于存放反转后的字符串
repeat with i:=1 to charcount(string) --根据字符串中的字符数量开展循环
--从源字符串左侧开始处理字符,最左侧的字符放在目标字符串的最右侧
reverse:=substr(string, i, i)^reverse
end repeat
上述语句执行之后,变量reverse的值为:"gnimoc si 0.7 erawrohtua"。本过程同样适用于中文字符串。
以下过程将变量string中的单词顺序进行反转。
wordreverse:="" --用于存放反转后的字符串
repeat with i:=1 to wordcount(string) --根据字符串中的单词数量开展循环
--从源字符串左侧开始处理单词,最左侧的单词放在目标字符串的最右侧
wordreverse:=getword(i, string)^" "^wordreverse
end repeat
--去除字符串末尾多余的空格
wordreverse:=substr(wordreverse, 1, charcount(wordreverse)-1)
上述语句执行之后,变量wordreverse的值为:"coming is 7.0 authorware"。
以下过程将变量string中的字符以升序进行排序。
string:="authorware 7 is coming"
charlist:=[] --用于存放单独的字符,便于利用sortbyvalue()函数进行排序
sorted:="" --用于存放排序后的字符串
ascending:=true --用于决定采用升序或降序排序
repeat with i:=1 to charcount(string)
--将字符串中的每个字符分别存放在不同的列表元素中
addlinear(charlist, substr(string, i, i))
end repeat
sortbyvalue(charlist ,ascending) --对列表元素进行排序
repeat with i:=1 to charcount(string)
sorted:=sorted^charlist[i] --将排序后的列表元素连接成为字符串
end repeat
上述语句执行之后,变量sorted的值为:" .07acaeghiimnoorrstuw"。如果将变量ascending赋值为false,则上述过程将变量string中的字符以降序进行排序。
以下过程将变量string中的大写字母转换为小写字母,小写字母转换为大写字母。
string:="authorware 7 is coming"
casereverse:="" --用于存放转换后的字符串
repeat with i:=1 to charcount(string)
--以下三行内容属于同一行程序代码,根据每个字符的ascⅱ码判断是否进行大
--小写转换。大写字母的ascⅱ码范围是65~90,小写字母的ascⅱ码范围是97~122
casereverse:=casereverse^test(code(substr(string, i, ﹁
i))>64&code(substr(string, i, i))<91, lowercase(substr(string, i, ﹁
i)), (test(code(substr(string, i, i))>96& ﹁
code(substr(string, i, i))<123, uppercase(substr(string, i, i)),substr(string, i, i))))
end repeat
上述语句执行之后,变量casereverse的值为:"authorware 7 is coming"。
以下过程将变量string中的字符串进行简单加密。加密原理是:依次获取每个字符的ascⅱ码字符串,并利用reverse过程反转ascⅱ码中的数值顺序。例如字符"a"的ascⅱ码字符串是"65",经反转之后得到字符串"56"。
string:="authorware 7 is coming"
encode:="" --用于存放加密后的字符串
repeat with i:=1 to charcount(string)
ascii:=string(code(substr(string, i, i)))
--以下通过reverse过程,反转ascⅱ码中的数值顺序
reverse:=""
repeat with j:=1 to charcount(ascii)
reverse:=substr(ascii, j, j)^reverse
end repeat
encode:=encode^reverse^" " --将反转后的ascⅱ码以空格分隔,连接成为字符串
end repeat
上述语句执行之后,变量encode的值为:"56 711 611 401 111 411 911 79 411 101 23 55 64 84 23 501 511 23 76 111 901 501 011 301 "。在aws中单个变量最多可存储512k个字符,因此加密过程可以对长达128k的字符串进行加密。
以下过程将变量encode中的字符串(由上述加密过程形成)进行解密。解密是加密的逆过程,例如将字符串"56"反转之后得到字符串"65",再由"65"得到字符"a"。以下过程同样利用了reverse过程。
decode:="" --用于存放解密后的字符串
--根据加密字符串中的反转ascⅱ码数量开展循环
repeat with i:=1 to wordcount(encode)
ascii=getword(i, encode)
--以下通过reverse过程,得到正确的ascⅱ码
reverse:=""
repeat with j:=1 to charcount(ascii)
reverse:=substr(ascii, j, j)^reverse
end repeat
decode:=decode^ char(reverse)
end repeat
上述语句执行之后,变量decode的值为:"authorware 7.0 is coming "。
上述过程全部以代码片段的形式保存在chapter03文件夹下的ece7.xml文件中。读者可以打开该文件,如图3-36所示,将其中的代码片段复制到自己的ece7.xml文件中(它通常位于c:/documents and settings/<用户名>/application data/macromedia /authorware 7路径中)。读者也可以直接使用光盘中的ece7.xml文件替换自己的ece7.xml文件,并取消文件的只读属性,在此之前请做好ece7.xml文件的备份工作,这样在authorware 7.0中就可以通过插入代码片段的方式使用这些过程,如图3-37所示。在使用代码片段时,需要创建在上述过程中以粗体表示的自定义变量。
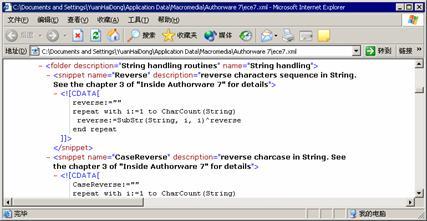
图3-36 ece7.xml中的自定义过程
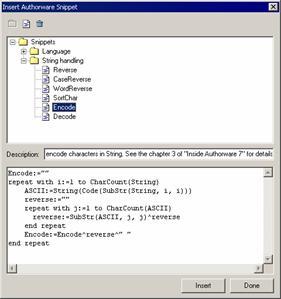
图3-37 自定义代码片段
可以将平时经常使用的过程都创建为代码片段。这样在以后的设计过程中,就不必重复输入大量相同或相似的内容,从而可以有效地提高工作效率。但代码片段通常只是一段代码的框架,在插入到运算窗口中后还需要进行完善(例如创建或重新命名变量,避免和程序中已有的变量发生冲突)。
新闻热点






疑难解答













