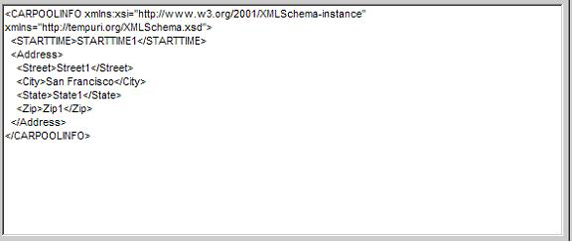
我们今天的主题不是论述xml的好处,而是讨论在c#中如何使用xml。下面我们来了解一下使用程序访问xml的一些基础理论知识。
访问的两种模型:
在程序中访问进而操作xml文件一般有两种模型,分别是使用dom(文档对象模型)和流模型,使用dom的好处在于它允许编辑和更新xml文档,可以随机访问文档中的数据,可以使用xpath查询,但是,dom的缺点在于它需要一次性的加载整个文档到内存中,对于大型的文档,这会造成资源问题。流模型很好的解决了这个问题,因为它对xml文件的访问采用的是流的概念,也就是说,任何时候在内存中只有当前节点,但它也有它的不足,它是只读的,仅向前的,不能在文档中执行向后导航操作。虽然是各有千秋,但我们也可以在程序中两者并用实现优劣互补嘛,呵呵,这是题外话了!我们今天主要讨论xml的读取,那我们就详细讨论一下流模型吧!
流模型中的变体:
流模型每次迭代xml文档中的一个节点,适合于处理较大的文档,所耗内存空间小。流模型中有两种变体——“推”模型和“拉”模型。
推模型也就是常说的sax,sax是一种靠事件驱动的模型,也就是说:它每发现一个节点就用推模型引发一个事件,而我们必须编写这些事件的处理程序,这样的做法非常的不灵活,也很麻烦。
.net中使用的是基于“拉”模型的实现方案,“拉”模型在遍历文档时会把感兴趣的文档部分从读取器中拉出,不需要引发事件,允许我们以编程的方式访问文档,这大大的提高了灵活性,在性能上“拉”模型可以选择性的处理节点,而sax每发现一个节点都会通知客户机,从而,使用“拉”模型可以提高application的整体效率。在.net中“拉”模型是作为xmlreader类实现的,下面看一下该类的继承结构:
我们今天来讲一下该体系结构中的xmltextreader类,该类提供对xml文件进行读取的功能,它可以验证文档是否格式良好,如果不是格式良好的xml文档,该类在读取过程中将会抛出xmlexception异常,可使用该类提供的一些方法对文档节点进行读取,筛选等操作以及得到节点的名称和值,请牢记:xmltextreader是基于流模型的实现,打个不恰当的比喻,xml文件就好象水源,闸一开水就流出,流过了就流过了不会也不可以往回流。内存中任何时候只有当前节点,你可以使用xmltextreader类的read()方法读取下一个节点。好了,说了这么多来看一个例子,编程要注重实际对吧。看代码前先看下运行效果吧!
example1按纽遍历文档读取数据,example2,example3按纽得到节点类型,example4过滤文档只获得数据内容,example5得到属性节点,example6按纽得到命名空间,example7显示整个xml文档,为此,我专门写一个类来封装以上功能,该类代码如下:
//---------------------------------------------------------------------------------------------------
//xmlreader类用于xml文件的一般读取操作,以下对这个类做简单介绍:
//
//attributes(属性):
//listbox: 设置该属性主要为了得到客户端控件以便于显示所读到的文件的内容(这里是listbox控件)
//xmlpath: 设置该属性为了得到一个确定的xml文件的绝对路径
//
//basilic using(重要的引用):
//system.xml: 该命名空间中封装有对xml进行操作的常用类,本类中使用了其中的xmltextreader类
//xmltextreader: 该类提供对xml文件进行读取的功能,它可以验证文档是否格式良好,如果不是格式 // 良好的xml文档,该类在读取过程中将会抛出xmlexception异常,可使用该类提供的
// 一些方法对文档节点进行读取,筛选等操作以及得到节点的名称和值
//
//bool xmltextreader.read(): 读取流中下一个节点,当读完最后一个节点再次调用该方法该方法返回false
//xmlnodetype xmltextreader.nodetype: 该属性返回当前节点的类型
// xmlnodetype.element 元素节点
// xmlnodetype.endelement 结尾元素节点
// xmlnodetype.xmldeclaration 文档的第一个节点
// xmlnodetype.text 文本节点
//bool xmltextreader.hasattributes: 当前节点有没有属性,返回true或false
//string xmltextreader.name: 返回当前节点的名称
//string xmltextreader.value: 返回当前节点的值
//string xmltextreader.localname: 返回当前节点的本地名称
//string xmltextreader.namespaceuri: 返回当前节点的命名空间uri
//string xmltextreader.prefix: 返回当前节点的前缀
//bool xmltextreader.movetonextattribute(): 移动到当前节点的下一个属性
//---------------------------------------------------------------------------------------------------
namespace xmlreading
{
using system;
using system.xml;
using system.windows.forms;
using system.componentmodel;
/// <summary>
/// xml文件读取器
/// </summary>
public class xmlreader : idisposable
{
private string _xmlpath;
private const string _errmsg = "error occurred while reading ";
private listbox _listbox;
private xmltextreader xmltxtrd;
#region xmlreader 的构造器
public xmlreader()
{
this._xmlpath = string.empty;
this._listbox = null;
this.xmltxtrd = null;
}
/// <summary>
/// 构造器
/// </summary>
/// <param name="_xmlpath">xml文件绝对路径</param>
/// <param name="_listbox">列表框用于显示xml</param>
public xmlreader(string _xmlpath, listbox _listbox)
{
this._xmlpath = _xmlpath;
this._listbox = _listbox;
this.xmltxtrd = null;
}
#endregion
#region xmlreader 的资源释放方法
/// <summary>
/// 清理该对象所有正在使用的资源
/// </summary>
public void dispose()
{
this.dispose(true);
gc.suppressfinalize(this);
}
/// <summary>
/// 释放该对象的实例变量
/// </summary>
/// <param name="disposing"></param>
protected virtual void dispose(bool disposing)
{
if (!disposing)
return;
if (this.xmltxtrd != null)
{
this.xmltxtrd.close();
this.xmltxtrd = null;
}
if (this._xmlpath != null)
{
this._xmlpath = null;
}
}
#endregion
#region xmlreader 的属性
/// <summary>
/// 获取或设置列表框用于显示xml
/// </summary>
public listbox listbox
{
get
{
return this._listbox;
}
set
{
this._listbox = value;
}
}
/// <summary>
/// 获取或设置xml文件的绝对路径
/// </summary>
public string xmlpath
{
get
{
return this._xmlpath;
}
set
{
this._xmlpath = value;
}
}
#endregion
/// <summary>
/// 遍历xml文件
/// </summary>
public void eachxml()
{
this._listbox.items.clear();
this.xmltxtrd = new xmltextreader(this._xmlpath);
try
{
while(xmltxtrd.read())
{
this._listbox.items.add(this.xmltxtrd.value);
}
}
catch(xmlexception exp)
{
throw new xmlexception(_errmsg + this._xmlpath + exp.tostring());
}
finally
{
if (this.xmltxtrd != null)
this.xmltxtrd.close();
}
}
/// <summary>
/// 读取xml文件的节点类型
/// </summary>
public void readxmlbynodetype()
{
this._listbox.items.clear();
this.xmltxtrd = new xmltextreader(this._xmlpath);
try
{
while(xmltxtrd.read())
{
this._listbox.items.add(this.xmltxtrd.nodetype.tostring());
}
}
catch(xmlexception exp)
{
throw new xmlexception(_errmsg + this._xmlpath + exp.tostring());
}
finally
{
if (this.xmltxtrd != null)
this.xmltxtrd.close();
}
}
/// <summary>
/// 根据节点类型过滤xml文档
/// </summary>
/// <param name="xmlntype">xmlnodetype 节点类型的数组</param>
public void filterbynodetype(xmlnodetype[] xmlntype)
{
this._listbox.items.clear();
this.xmltxtrd = new xmltextreader(this._xmlpath);
try
{
while(xmltxtrd.read())
{
for (int i = 0; i < xmlntype.length; i++)
{
if (xmltxtrd.nodetype == xmlntype[i])
{
this._listbox.items.add(xmltxtrd.name + " is type " + xmltxtrd.nodetype.tostring());
}
}
}
}
catch(xmlexception exp)
{
throw new xmlexception(_errmsg + this.xmlpath + exp.tostring());
}
finally
{
if (this.xmltxtrd != null)
this.xmltxtrd.close();
}
}
/// <summary>
/// 读取xml文件的所有文本节点值
/// </summary>
public void readxmltextvalue()
{
this._listbox.items.clear();
this.xmltxtrd = new xmltextreader(this._xmlpath);
try
{
while(xmltxtrd.read())
{
if (xmltxtrd.nodetype == xmlnodetype.text)
{
this._listbox.items.add(xmltxtrd.value);
}
}
}
catch(xmlexception xmlexp)
{
throw new xmlexception(_errmsg + this._xmlpath + xmlexp.tostring());
}
finally
{
if (this.xmltxtrd != null)
this.xmltxtrd.close();
}
}
/// <summary>
/// 读取xml文件的属性
/// </summary>
public void readxmlattributes()
{
this._listbox.items.clear();
this.xmltxtrd = new xmltextreader(this._xmlpath);
try
{
while(xmltxtrd.read())
{
if (xmltxtrd.nodetype == xmlnodetype.element)
{
if (xmltxtrd.hasattributes)
{
this._listbox.items.add("the element " + xmltxtrd.name + " has " + xmltxtrd.attributecount + " attributes");
this._listbox.items.add("the attributes are:");
while(xmltxtrd.movetonextattribute())
{
this._listbox.items.add(xmltxtrd.name + " = " + xmltxtrd.value);
}
}
else
{
this._listbox.items.add("the element " + xmltxtrd.name + " has no attribute");
}
this._listbox.items.add("");
}
}
}
catch(xmlexception xmlexp)
{
throw new xmlexception(_errmsg + this._xmlpath + xmlexp.tostring());
}
finally
{
if (this.xmltxtrd != null)
this.xmltxtrd.close();
}
}
/// <summary>
/// 读取xml文件的命名空间
/// </summary>
public void readxmlnamespace()
{
this._listbox.items.clear();
this.xmltxtrd = new xmltextreader(this._xmlpath);
try
{
while(xmltxtrd.read())
{
if (xmltxtrd.nodetype == xmlnodetype.element && xmltxtrd.prefix != "")
{
this._listbox.items.add("the prefix " + xmltxtrd.prefix + " is associated with namespace " + xmltxtrd.namespaceuri);
this._listbox.items.add("the element with the local name " + xmltxtrd.localname + " is associated with" + " the namespace " + xmltxtrd.namespaceuri);
}
if (xmltxtrd.nodetype == xmlnodetype.element && xmltxtrd.hasattributes)
{
while(xmltxtrd.movetonextattribute())
{
if (xmltxtrd.prefix != "")
{
this._listbox.items.add("the prefix " + xmltxtrd.prefix + " is associated with namespace " + xmltxtrd.namespaceuri);
this._listbox.items.add("the attribute with the local name " + xmltxtrd.localname + " is associated with the namespace " + xmltxtrd.namespaceuri);
}
}
}
}
}
catch(xmlexception xmlexp)
{
throw new xmlexception(_errmsg + this._xmlpath + xmlexp.tostring());
}
finally
{
if (this.xmltxtrd != null)
this.xmltxtrd.close();
}
}
/// <summary>
/// 读取整个xml文件
/// </summary>
public void readxml()
{
string attandele = string.empty;
this._listbox.items.clear();
this.xmltxtrd = new xmltextreader(this._xmlpath);
try
{
while(xmltxtrd.read())
{
if (xmltxtrd.nodetype == xmlnodetype.xmldeclaration)
this._listbox.items.add(string.format("<?{0} {1} ?>",xmltxtrd.name,xmltxtrd.value));
else if (xmltxtrd.nodetype == xmlnodetype.element)
{
attandele = string.format("<{0} ",xmltxtrd.name);
if (xmltxtrd.hasattributes)
{
while(xmltxtrd.movetonextattribute())
{
attandele = attandele + string.format("{0}='{1}' ",xmltxtrd.name,xmltxtrd.value);
}
}
attandele = attandele.trim() + ">";
this._listbox.items.add(attandele);
}
else if (xmltxtrd.nodetype == xmlnodetype.endelement)
this._listbox.items.add(string.format("</{0}>",xmltxtrd.name));
else if (xmltxtrd.nodetype == xmlnodetype.text)
this._listbox.items.add(xmltxtrd.value);
}
}
catch(xmlexception xmlexp)
{
throw new xmlexception(_errmsg + this._xmlpath + xmlexp.tostring());
}
finally
{
if (this.xmltxtrd != null)
this.xmltxtrd.close();
}
}
}
}
新闻热点






疑难解答