XML和JSP是这些天以来最炙手可热的东西,本文将给伙伴们介绍XML联合JSP技术建设动态网站,你还可以同时看一下dom,xpath,xsl,和其它java-xml技术的示例代码喔。
我们在此假设你已经了解javaserver pages(jsp)和extensible markup language (xml)。但也许你对该如何综合使用它们仍然有些迷惑。
jsp的应用很容易,你可以用它设计网页,使之看起来似乎和html一样。唯一的不同是jsp是动态执行的。例如,它们可以处理表单form和读写数据库。
xml的应用的说明则比较困难。似乎所有的产品都支持它,每个人也好象都以各种不同目的在使用它。
在本文中,你可以看到如何使用一种相当先进的方式用xml来设计一个系统。许多站点有巨量数据收集并以一种很标准或很不标准的方式来显示它们。我将设计一个系统,它使用xml文件在web服务器上进行存储,并用jsp来显示数据。
xml vs 关系型数据库
"等一下!"你可能问,"你用xml文件存储数据吗?为什么不使用数据库?"
这个问题问的很好。我的回答是,对很多目的用途来说,用数据库太过浪费了。.要使用一个数据库,你必须安装和支持一个分离的服务器处理进程(a separate server process),它常要求有安装和支持它的administrator。你必须学习sql, 并用sql写查询,然后转换数据,再返回。而如果你用xml文件存储数据,将可减少额外的服务器的负荷。还有,你还找到了一个编辑数据的简单方法。你只要使用文本编辑器,而不必使用复杂的数据库工具。xml文件很容易备份,和朋友共享,或下载到你的客户端。同样的,你可以方便地通过ftp上载新的数据到你的站点。
xml还有一个更抽象的优点,即作为层次型的格式比关系型的更好。 它可以用一种很直接的方式来设计数据结构来符合你的需要。你不需要使用一个实体-关系编辑器,也不需要使你的图表(schema)标准化。 如果你有一个元素(element)包含了另一个元素,你可以直接在格式中表示它,而不需要使用表的关联。
注意,在很多应用中,依靠文件系统是不够充分的。如果更新很多,文件系统会因为同时写入而受到破坏。数据库则通常支持事务处理,可以应付所发生的请求而不至于损坏。对于复杂的查询统计要有反复、及时的更新,此时数据库表现都很优秀。当然,关系型数据库还有很多优点,包括丰富的查询语言,图表化工具,可伸缩性,存取控制等等。
(注意:你可以使用简单的文件锁定来提供一个事务处理服务器,你还可以在java中执行一种 xml index-and-search工具,不过这已经是另外一篇文章的主题了。)
在下面这样的案例中,正如大多数中小规模的、基于发布信息的站点一样,你可能涉及的大多数数据存取都是读,而不是写,数据虽然可能很大,但相对来说并没有经常的更新变化,你也不需要做很复杂的查询,即使你需要做,也将用一个独立的查询工具,那么成熟的rdbms的优点消失了,而面向对象型的数据模型的优点则可以得到体现。
最后,为你的数据库提供一个查询器外壳来进行sql查询并将他们转化进入xml stream也是完全有可能的。
所以你可以选择这二种方式之一。xml正变成一种非常健壮的,便于编程的工具,作为某个成熟的数据库的前端工具来进行存储和查询。(oracle的xsql servlet即是这种技术的一个很好的例子。)
应用篇:一个在线相册
所有人都喜欢照相!他们喜欢展示自己的,亲人的,朋友的,度假时的照片,而 web 是他们展示的好地方。-- 即使千里之外的亲戚都可以看到。我将着重于定义一个单独的picture对象。(这一应用的源代码在resources中可以取得) 。该对象描述了表示一张照片所需要的字段:title,date,一个可选的标题,以及对图片来源的一个指向。
一个图象,需要它自己的一些字段:源文件( gif/jpeg)的定位,宽度和高度像素(以协助建立 标记。 这里可以看到一个很简单的优点,即使用文件系统来代替数据库的时候,你可以将图形文件存放在与数据文件相同的目录中。
最后,让我们来用一个元素扩展图片记录,该元素定义了一套缩略图(thumbnail)来用于内容表或其它地方。这里我用了和先前同样定义的图片内容。
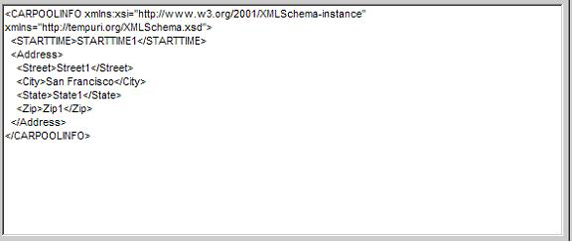
一张图片的xml表示可以是这样的:
trying in vain to get a tan
注意,通过使用xml, 你将一张单独图片的全部信息放到了一个单独的文件中,而不是将它分散放入3-4个表中。 我们将这称为 .pix file
-- 于是你的文件系统会是这样的:
summer99/alex-beach.pix
summer99/alex-beach.jpg
summer99/alex-beach-sm.jpg
summer99/alex-beach-med.jpg
summer99/alex-snorkeling.pix
etc.
技术篇
俗话说,要剥下猫的皮的方法何止一种。同样,将xml数据放到jsp中也不止一种办法。这里列举了其中一些方法,(其实,很多其它工具也可以做得同样出色。)
dom: 你可以使用类(classes)来调用dom接口(interface)对xml文件进行分析检查。
xmlentrylist: 你可以使用我的代码来将xml加载到name-value pairs 的java.util.list中。
xpath: 你可以使用一个 xpath处理器(如resin)通过路径名在xml文件中定位元素。
xsl:你可以使用某种xsl处理器将xml转换成为html。
cocoon: 你可以使用开放源码的cocoon framework
运行你自己的bean: 你可以写一个外壳类(wrapper class),使用某种其它技术来将数据加载到字定义的javabean中。
请注意这些技术将和一个你从另外来源取得的xml stream执行得同样出色,例如一个客户端或者一个应用服务器。
javaserver pages
jsp规范有很多替身,不同的jsp产品表现也不尽相同,不同版本之间也有差别。我选择了tomcat,这基于以下原因:
它支持大多数最新的jsp/servlet规范
它受到 sun和apache认同
你可以独立运行它而不需要另外配置一个web服务器。
它是开放源码的
你可以选择任何你喜欢的jsp引擎,但要自己配置它,它必须至少支持jsp 1.0规范。0.91和1.0之间有了许多区别。而jswdk (java server web development kit) 可能刚刚好地适合要求。
jsp结构
当创建一个jsp网站 (webapp), 我喜欢将公用的函数、导入、常量、变量声明都放入到一个单独的文件init.jsp中。 然后用 加载到每一个文件中去。 就象c语言的 #include, include在编译时使其中的文本作为一个部分被加入并一起进行编译,相对地,
查找文件
当jsp启动时,初始化后第一件事情就是查找你要的xml文件。它是怎么知道在众多文件中你要找的是哪一个? 它来自与一个参数,使用者会在调用jsp的url中加入参数: picture.jsp?file=summer99/alex-beach.pix (或者通过html表单来传递文件参数)。
但是,当jsp接受此参数以后,你仍然只完成了一半工作,因为还要知道文件系统的根目录在哪里。例如,在unix系统中,实际文件可能在这样的路径:
/home/alex/public_html/pictures/summer99/alex-beach.pix。
jsp文件在执行状态时没有当前路径概念。所以你为java.io包要给出一个绝对路径。
servlet api可以提供一个方法来将一个url路径,从相对于当前jsp或servlet的路径转化成为一个绝对的文件系统路径。方法是:
servletcontext.getrealpath(string)。
每一个jsp有一个叫做application的 servletcontext对象。所以代码可以是:
string picturefile =
application.getrealpath("/" + request.getparameter("file"));
或者
string picturefile =
getservletcontext().getrealpath("/" + request.getparameter("file"));
它也可以在servlet中工作。(你必须加上 / 因为此方法需要传递request.getpathinfo()的结果。)
这里有一个重要的提示:每当你存取本地的资源,要非常小心地检查输入数据的合法性。黑客或者粗心的用户,可能发送伪造的或错误的数据来破坏你的站点。例如,请想一下以下的表达会发生什么结果:
如果输入了file=../../../../etc/passwd。这样用户回读到你的服务器的password文件!
dom (document object model)
dom 代表文档对象模型document object model。它是浏览xml文档的一种标准api,由world wide web consortium (w3c)发展。 接口在org.w3c.dom包中,文档参见w3c站点。
有许多可用的dom分析器工具。我选择了 ibm的xml4j。但你可以使用任何其它的dom分析器。这是因为dom是一套接口,而不是类 --所有的dom分析器(parser)必须返回同样地处理这些接口的对象。
遗憾的是,虽然很标准,dom还是有两大缺陷:
1 api虽然也是面向对象的,还是相当笨重。
dom parser并没有标准的api,所以, 当每一个分析器返回一个org.w3c.dom对象,文档对象--分析器初始化和文件自身加载的方式,对应于不同分析器通常总是特定的。
这个简单的上面已描述的图片文件在dom中可以在一个树结构中通过一些对象表示如下:
document node
--> element node "picture"
--> text node "/n " (whitespace)
--> element node "title"
--> text node "alex on the beach"
--> element node "date"
--> ... etc.
为了取得“alex on the beach”,你要做一些方法调用,游历dom树,而且,分析器可能选择分散“whitespace”文本nodes的一些数据,你不得不使用循环和串联等 (你可以通过调用normalize()来纠正这个问题。)分析器可能还包含了分离的xml实体(如 &), cdata nodes或者其它实体nodes (如big会被变成至少三个node。也没有办法在dom中简单表示"get me the text value of the title element." 总之,在dom中游历有一点笨重。(参见本文用xpath取代dom章节。)
2 从更高处看,dom的问题是xml对象无法象java对象一样可以直接得到,它们需要通过 dom api一个一个地得到。
你可以参考我的为java-xml data binding技术讨论做的一些归纳,那里也用了这种直接使用java的方法来存取xml数据。
我写了一个小的工具类,叫做domutils,包含了静态方法来执行公用的dom任务。例如,要获得根(图片)元素的title子元素的文本内容,你可以编写如下代码:
document doc = domutils.xml4jparse(picturefile);
element noderoot = doc.getdocumentelement();
node nodetitle = domutils.getchild(noderoot, "title");
string title = (nodetitle == null) ? null : domutils.gettextvalue(nodetitle);
以上就是XML联合JSP技术建设动态网站的全部内容,如果大家想了解更多相关内容,请持续关注本站,本站小编将在第一时间为大家带来更好的经典内容。


新闻热点






疑难解答