简介
XML,或称为可扩展标记语言(Extensible Markup Language),是一种您可以用来创建自己的标记的标记语言。它由万维网协会(W3C)创建,用来克服 HTML(即超文本标记语言(Hypertext Markup Language),它是所有网页的基础)的局限。和 HTML 一样,XML 基于 SGML � 标准通用标记语言(Standard Generalized Markup Language)。尽管 SGML 已在出版业使用了数十年,但其理解方面的复杂性使许多本打算使用它的人望而却步(SGML 也代表“听起来很棒,但或许以后会用(Sounds great, maybe later)”)。XML 是为 Web 设计的。
我们为什么需要 XML?
HTML 始终是最成功的标记语言。您几乎可以在任何设备(从掌上电脑到大型机)上查看最简单的 HTML 标记,并且您甚至可以用合适的工具将 HTML 标记转换成语音和其它格式。既然 HTML 成功了,为什么 W3C 还要创建 XML 呢?为了回答这个问题,请查看下面这个文档:
<p><b>Mrs. Mary McGoon</b>
<br>
1401 Main Street
<br>
Anytown, NC 34829</p>
HTML 的问题在于它是为人设计的。即使不用浏览器查看上面的 HTML 文档,您和我也会知道那是某个人的邮政地址。(具体而言,它是美国某个人的邮政地址;即使您一点也不熟悉美国邮政地址的格式,您可能也会猜出这表示什么。)作为人,您和我具有理解大多数文档的含义和意图的聪明。遗憾的是机器不能做到。尽管这个文档中的标记告诉浏览器如何显示该信息,但标记没有告诉浏览器信息是什么。您和我知道它是一个地址,但机器不知道。
显示 HTML
要显示 HTML,浏览器只需遵循 HTML 文档中的指令即可。段标记告诉浏览器在新的一行显示,并且通常在前面有一个空行,而两个换行标记则告诉浏览器前进到下一行,并且行之间没有空行。尽管浏览器出色地将文档格式化,但机器仍不知道这是地址。 处理 HTML
处理 HTML
为了完成对样本 HTML 文档的讨论,请考虑从该地址抽取邮政编码的任务。下面是一个在 HTML 标记中查找邮政编码的算法(我有意使用脆弱的算法),假如您找到有两个 <br> 标记的段落,那么邮政编码就是第二个换行标记下面第一个逗号之后的第二个词。
尽管该算法对于这个示例起作用,但对于全世界许多完全有效的地址,该算法根本不起作用。即使您可以编写算法来找出任何用 HTML 编写的地址的邮政编码,但许多具有两个换行标记的段落根本不包含地址。即便有可能编写算法来查看任意 HTML 段落并找出其中的任意邮政编码,也是极其困难的。
样本 XML 文档
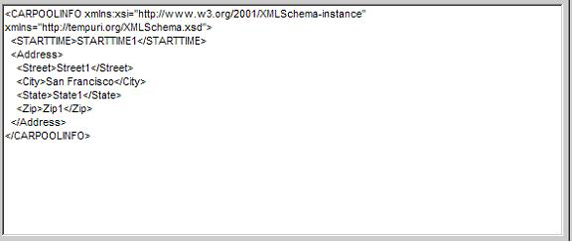
现在让我们来看一个样本 XML 文档。使用 XML,您可以给文档中的标记赋予某种含意。更重要的是,机器也轻易处理这样的信息。您只需通过找到 <postal-code> 和 </postal-code> 标记之间的内容(技术上称为 <postal-code> 元素),就可以从该文档抽取邮政编码。
<address>
<name>
<title>Mrs.</title>
<first-name>
Mary
</first-name>
<last-name>
McGoon
</last-name>
</name>
<street>
1401 Main Street
</street>
<city>Anytown</city>
<state>NC</state>
<postal-code>
34829
</postal-code>
新闻热点






疑难解答