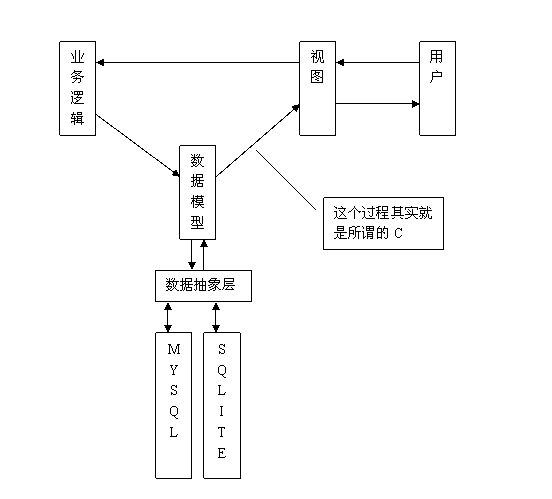
本例子是使用了file_get_contents()函数来抓取图片内容然后再使用fopen保存到本地服务器了,然后再进行地址url替换这样就实现了一个完整的页面采集功能并保存地址到本地的做法了,下面来看看例子.
首先举个例子吧,代码如下:
- <?php
- $text=file_get_contents("http://www.Vevb.com");
- //取得所有img标签,并储存至二维阵列match
- preg_match_all('/<[img|IMG].*?src=[\'|\"](.*?(?:[\.gif|\.jpg]))[\'|\"].*?[\/]?>/', $text, $match);
- //打印出match
- $houzhui = "./tp/".time().rand(10000,50000).".".png;
- $yuanname = getImage($match[1][2],$houzhui,tp);
- //下载图片方法
- function getImage($url,$filename='',$type=0){
- if($url==''){return false;}
- if($filename==''){
- $ext=strrchr($url,'.');
- if($ext!='.gif' && $ext!='.jpg'){return false;}
- $filename=time().$ext;
- }
- //文件保存路径
- if($type){
- $ch=curl_init();
- $timeout=5;
- curl_setopt($ch,CURLOPT_URL,$url);
- curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
- curl_setopt($ch,CURLOPT_CONNECTTIMEOUT,$timeout);
- $img=curl_exec($ch);
- curl_close($ch);
- }else{
- ob_start();
- readfile($url);
- $img=ob_get_contents();
- ob_end_clean();
- }
- $size=strlen($img);
- //文件大小
- $fp2=@fopen($filename,'a');
- fwrite($fp2,$img);
- fclose($fp2);
- return $filename;
- }
- ?>
案例分析,核心代码如下:
- $text=file_get_contents("http://www.Vevb.com");
- //取得所有img标签,并储存至二维阵列match
- preg_match_all('/<[img|IMG].*?src=[\'|\"](.*?(?:[\.gif|\.jpg]))[\'|\"].*?[\/]?>/', $text, $match);
这个正则就是直接获取所有图片不管是http或直接是/aa/aa.gif文件都会自动抓保存到地址了,不过这个会有一些问题图片地址未进行补全了,如我们一个 /a/a/a.gif这样我们是找不到图片的,必须是http://www.Vevb.com /a/a/a.gif 这样才可以下载到了,所以我们有必要进行两个处理方法一个是在原基本上处理,代码如下:
- //文件保存路径
- if($type){
- $ch=curl_init();
- $timeout=5;
- curl_setopt($ch,CURLOPT_URL,$url);
- curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
- curl_setopt($ch,CURLOPT_CONNECTTIMEOUT,$timeout);
- $img=curl_exec($ch);
- curl_close($ch);
上面的$url参数进行地址补全,如我采集的是http://www.Vevb.com那么地址自动补全为绝对路径了,另一种办法就是使用修改正则表达式,代码如下:
- preg_match_all("/(src|SRC)=[\"|'| ]{0,}(http:\/\/(.*)\.(gif|jpg|jpeg|png))/isU",$body,$img_array);
这样就只获取以http开头的图片文件了哦.
新闻热点






疑难解答