本文阐述了批处理在 sql server 2005 中的缓存和重用方式,并就最大限度重用已缓存的计划提供了相应的最佳实务。另外,文中还说明了一些重新编译批处理的方案,并针对减少或消除不必要的重新编译,给出了最佳实务。
一、本白皮书的目的
此白皮书的目的有几个。阐述了批处理在 sql server 2005 中的缓存和重用方式,并就最大限度重用已缓存的计划提供了相应的最佳实务。另外,文中还说明了一些重新编译批处理的方案,并针对减少或消除不必要的重新编译,给出了最佳实务。本白皮书阐述了 sql server 2005 的“语句级重新编译”功能。另外,还介绍了许多工具及实用程序,它们可在查询编译、查询重新编译、计划缓存和计划重用过程中充当很有用的观测工具。我们在整篇文章中对比了 sql server 2000 和 sql server 2005 的不同表现,以便读者能够更好地了解文中的内容。本文档所列举的语句均适用于 sql server 2000 和 sql server 2005。同时,明确指出了这两个 sql server 版本在行为上的差异。
本文面向三类读者:
用户:使用、维护并为 sql server 开发应用程序的人员。初识 sql server 2005 的用户及正从 sql server 2000 进行迁移的人员将在这里找到有用的信息。
开发人员:sql server 开发人员将在这里找到有用的背景信息。
测试人员和项目经理:本文档将对“sql server 2005 中的编译和重新编译”功能提供说明。
二、重新编译:定义
在查询、批处理、存储过程、触发器、被准备语句或动态 sql 语句(以下称为“批处理”)在 sql server 上开始执行以前,批处理将被编译成计划。然后,将执行该计划以便发挥其效力或生成结果。
|||一个批处理可包含一个或多个 select、insert、update 和 delete 语句、存储过程调用(t-sql“粘连”或控制结构(比如:set、if、while、declare)可能使其产生交错)、ddl 语句(比如:create、drop)以及与权限相关的语句(比如:grant、deny 和 revoke)。批处理还可包含 clr 构造的定义和用法(比如:用户定义的类型、函数、过程和聚合)。
已编译的计划被保存到 sql server 的一部分内存中,这部分内存称为计划缓存。将搜索计划缓存以获得重用计划的机会。如果对某个批处理重用计划,就可避免编译工作。请注意,在有关 sql server 的文献中,过去所用的“过程缓存”一词在本文中被称为“计划缓存”。“计划缓存”用词更准确,因为计划缓存不仅仅保存存储过程的查询计划。
在涉及 sql server 的用语中,上段所提到的编译过程有时会被误认为是“重新编译”,但该过程仅涉及“编译”。
重新编译的定义:假设某个批处理被编译成一个或多个查询计划的集合。在 sql server 开始执行任何单独的查询计划之前,服务器将检查该查询计划的有效性(正确性)和最优性。如果某个检查失败了,将重新编译相应查询计划所对应的语句或整个批处理,并可能生成一个不同的查询计划。这种编译称为“重新编译”。
请特别注意,不必预先缓存该批处理的查询计划。实际上,某些批处理类型从不被缓存,但仍能引发重新编译。举个例,有个批处理包含一个大于 8 kb 的文本。假设该批处理创建了一个临时表,并在表中插入了 20 行。所插入的第七行将导致重新编译,但由于其包含的文本较大,将不缓存该批处理。
在 sql server 中执行的多数重新编译都是有根据的。有些是为了确保语句的正确性;另一些是为了在 sql server 数据库中的数据发生变化时,获得最佳的查询执行计划。然而,重新编译有时会大大延缓批处理执行的速度。这时,就有必要减少进行重新编译的次数。
|||三、比较 sql server 2000 和 sql server 2005 中的重新编译
在 sql server 2000 中重新编译批处理时,将重新编译批处理中的所有语句,而不仅仅是触发重新编译的语句。sql server 2005 在该行为上做了改进,只编译导致重新编译的语句,而不是整个批处理。与 sql server 2000 相比,这一“语句级重新编译”功能将改善 sql server 2005 的重新编译行为。尤其,在批处理重新编译过程中,sql server 2005 所用的 cpu 时间和内存更少,而得到的编译块也更少。
语句级重新编译有一个优点显而易见:不必再只是为了减少较长的存储过程的重新编译罚点,而将其分成多个较短的存储过程。
四、计划缓存
在处理重新编译问题之前,本文将用较大的篇幅来讨论查询计划缓存的相关及重要的主题。缓存计划以便重用。如果未缓存查询计划,重用机会将为零。这种计划将在每次执行时被编译,从而导致性能低下。只有在极少数情况下,才不需要进行缓存。本文将在后面指出这些情况。
sql server 可缓存许多批处理类型的查询计划。以下列举了这些类型。对于每种类型,我们都说明了重用计划的必要条件。请注意,这些条件不一定充分。稍后,读者将在本文中看到完整的相关内容。
1.
特殊查询。特殊查询是一种包含 select、insert、update 或 delete 语句的批处理。sql server 要求两个特殊查询的文本完全匹配。文本必须在大小写和空格上都匹配。例如,下列这两个查询不共享相同的查询计划。(出现在本白皮书中的所有 t-sql 代码段都在 sql server 2005 的 adventureworks 数据库中。)
select productid
from sales.salesorderdetail
group by productid
having avg(orderqty) > 5
order by productid
select productid
from sales.salesorderdetail
group by productid
having avg(orderqty) > 5
order by productid |||2.
自动参数化查询。对于某些查询,sql server 2005 将常量文本值替换为变量,并编译查询计划。如果后续的查询仅在常量的值上有所不同,那么其将与自动参数化查询相匹配。通常,sql server 2005 会对那些查询计划不取决于常量文本的特定值的查询进行自动参数化处理。
附录 a 包含一个语句类型列表,sql server 2005 将不对其上列出的语句类型进行自动参数化处理。
作为 sql server 2005 中自动参数化的一个示例,下列这两个查询可重用查询计划:
select productid, salesorderid, linenumber
from sales.salesorderdetail
where productid > 1000
order by productid
select productid, salesorderid, linenumber
from sales.salesorderdetail
where productid > 2000
order by productid上方查询的自动参数化形式为:
select productid, salesorderid, linenumber
from sales.salesorderdetail
where productid > @p1
order by productid当出现在查询中的常量文本的值会影响查询计划时,将不对该查询进行自动参数化处理。这类查询的查询计划将被缓存,但同时会插入常量,而不是占位符(比如:@p1)。
sql server 的“showplan”功能可用于确定是否已对查询进行了自动参数化处理。例如,可在“set showplan_xml on”模式下提交查询。如果结果 showplan 包含诸如 @p1 和 @p2 等占位符,那么将对查询进行自动参数化处理;否则将不进行自动参数化处理。xml 格式的 sql server showplan 还包含在编译时(‘showplan_xml’和‘statistics xml’模式)和执行时(仅‘statistics xml’模式)的参数值的相关信息。
|||,欢迎访问网页设计爱好者web开发。3.
sp_executesql 过程。这是促进查询计划重用的方法之一。当使用 sp_executesql 时,用户或应用程序将明确地确定参数。例如:
exec sp_executesql n'select p.productid, p.name, p.productnumber
from production.product p
inner join production.productdescription pd
on p.productid = pd.productdescriptionid
where p.productid = @a', n'@a int', 170
exec sp_executesql n'select p.productid, p.name, p.productnumber
from production.product p inner join production.productdescription pd
on p.productid = pd.productdescriptionid
where p.productid = @a', n'@a int', 1201可通过逐一列举来指定多个参数。实际的参数值遵照相应的参数定义。根据查询文本(sp_executesql 后的第一个参数)的匹配情况以及查询文本(上例中的 n'@a int')后面所带的所有参数来预测计划重用机会。不考虑参数值(170 和 1201)的文本是否匹配。因此,在上述例子中,两个 sp_executesql 语句会发生计划重用。
4.
预备的查询.该方法——类似于 sp_executesql 方法——还促进了查询计划重用。在“准备”时发送批处理文本。sql server 2005 通过返回一个句柄(可用于在执行时调用批处理)进行响应。在执行时,一个句柄和一些参数值会被发送到服务器。odbc 和 ole db 通过 sqlprepare/sqlexecute 和 icommandprepare 显露该功能。例如,使用 odbc 的代码段可能如下所示:
sqlprepare(hstmt, "select salesorderid, sum(linetotal) as subtotal
from sales.salesorderdetail sod
where salesorderid < ?
group by salesorderid
order by salesorderid", sql_nts)
sqlexecute(hstmt) |||国内最大的酷站演示中心!5.
存储过程(含触发器)。存储过程设计用于促进计划重用。计划重用基于存储过程或触发器的名称。(但是,无法直接调用触发器。)sql server 在内部将存储过程的名称转化为 id,而随后的计划重用将根据该 id 的值来进行。触发器的计划缓存和重新编译行为与存储过程略有不同。我们将在本文档的适当位置指出这些不同之处。
当首次编译一个存储过程时,执行调用所提供的参数的值被用于优化该存储过程中的语句。这个过程被称为“参数嗅探”。如果这些值都是典型的,那么针对该存储过程的所有调用将从一个高效的查询计划中获益。本文随后将讨论可用于防止缓存带有非典型的存储过程参数值的查询计划。
6.
批处理.如果批处理文本完全匹配,那么将对相应的批处理进行查询计划重用。文本必须在大小写和空格上都匹配。
7.
通过 exec ( ...) 执行查询。sql server 2005 可缓存通过 exec 提交的字符串以便执行。这些字符串称为“动态 sql”。例如:
exec ( 'select *' + ' from production.product pr
inner join production.productphoto ph' + '
on pr.productid = ph.productphotoid' +
' where pr.makeflag = ' + @mkflag )计划重用基于在执行语句时将变量(比如:上例中的 @mkflag )替换为其实际值后得到的连锁字符串。
多级缓存
认识到多“级”缓存匹配将独立进行,这一点很重要。举个例子。假设批处理 1(非存储过程)包含下列语句(及其他):
exec dbo.proca批处理 2(也不是存储过程)与批处理 1 在文本上不相匹配,但包含引用相同存储过程的 “exec dbo.proca”。这里,批处理 1 和批处理 2 的查询计划不相匹配。然而,只要在这两个批处理的一个中执行 “exec dbo.proca”,同时在执行当前批处理之前执行了另一个批处理,而 proca 的查询计划仍存在于计划缓存中,就有可能实现 proca 的查询计划重用。但是,每次单独执行 proca 都会得到执行上下文。该执行上下文要么刚刚生成(如果正在使用所有现有的执行上下文),要么被重用(如果未使用的执行上下文可用)。即使使用 exec 执行了动态 sql,或者在批处理 1 和批处理 2 内部执行了自动参数化语句,也有可能产生某种类型的重用。总之,下列三类批处理会启动他们自己的“级别”(无论任何包含级别中是否存在缓存匹配,都会在这些级别中产生缓存匹配):
|||商业源码热门下载www.html.org.cn
• 存储过程执行(比如:“exec dbo.stored_proc_name”)
• 动态 sql 执行(比如:“exec query_string”)
• 自动参数化查询
对于上述规则,存储过程是一个例外。例如,如果两个不同的存储过程都包含“exec proca”语句,那么就不会产生 proca 的查询计划和执行上下文重用。
查询计划和执行上下文
当一个可缓存的批处理被提交给 sql server 2005 进行执行时,该批处理会被编译,而它的一个查询计划会被放到计划缓存中。查询计划是一种只读的可重入结构(由多个用户共享)。任何时候,查询计划在计划缓存中最多只能有两个实例:一个用于所有的串行执行,另一个用于所有的并行执行。并行执行的副本适用于所有的并行级别。(严格说来,如果相同的用户使用带有相同会话选项的两个不同会话设置的两个相同的查询同时达到 sql server 2005,在执行时将存在两个查询计划。但是,当执行结束时,仅有一个查询计划会保留在计划缓存中。)
执行上下文是从查询计划中派生的。执行上下文是为生成查询结果而“执行”的。执行上下文也被缓存和重用。当前执行批处理的每位用户将拥有一个执行上下文,其中保存了特定于其执行的数据(比如:参数值)。虽然被重用,但是执行上下文并不是可重入的(例如,它们是单线程的)。也就是说,在任何时候,一个执行上下文只能执行一个由会话提交的批处理,而在执行时,相应的上下文不会提供给任何其他会话或用户。
查询计划与从中派生的执行上下文之间的关系如下图所示。其中,有一个查询计划,从中派生了三个执行上下文。这些执行上下文包含参数值和特定于用户的信息。对于参数值和特定于用户的信息而言,查询计划都不是明确的。
|||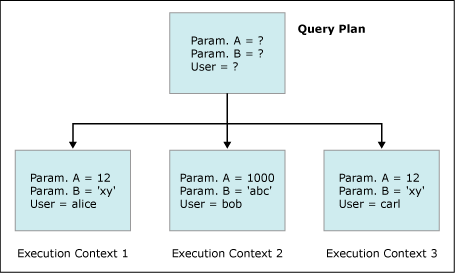
在计划缓存中,一个查询计划和多个相关联的执行上下文可以共存。然而,单个执行上下文(如果没有相关联的查询计划)无法存在于计划缓存中。只要从计划缓存中删除了查询计划,所有相关联的执行上下文也将随之被删除。
当搜索计划缓存以寻找计划重用的机会时,将比较各个查询计划,而不是各个执行上下文。一旦找到了可重用的查询计划,就能找到(导致执行上下文重用)或新生成可用的执行上下文。所以,查询计划重用不一定会导致执行上下文重用。
执行上下文是在“匆忙中 (on the fly)”派生的,其间一个主干执行上下文会在批处理执行开始之前生成。随着执行的进行,将生成必要的执行上下文片断并放入该主干中。这意味着,即便从中删除了特定于用户的信息和查询参数,两个执行上下文也不必完全相同。由于派生自相同查询计划的执行上下文的结构可以彼此不同,因此用于特定执行的执行上下文对性能有轻微的影响。随着计划缓存变“热”并达到稳定状态,这种性能差异的影响会越来越小。
例如:假设批处理 b 包含一个“if”语句。当 b 开始执行时,就会为其生成一个执行上下文。假设在首次执行时,提取了“if”的“true”分支。此外,假设在首次执行时,b 再次由另一个连接提交。因为当时唯一存在的执行上下文正被使用,所以将生成第二个执行上下文,并提供给第二个连接。假设第二个执行上下文提取了“if”的“false”分支。当这两个执行都完成之后,将有第三个连接提交 b。假设 b 的第三个执行选择了“true”分支,如果 sql server 为该连接选择了 b 的第一个执行上下文而非第二个执行上下文,那么完成该执行的速度将稍快一些。
可重用批处理 s 的执行上下文,即使 s 的调用顺序有所不同。例如,调用顺序可以是“存储过程 1 --> 存储过程 2 --> s”,而第二个调用顺序可以是“存储过程 3 --> s”。可对 s 的第二次执行重用其第一次执行的执行上下文。
如果批处理执行生成了严重级别高达 11 或更高的错误,那么其执行上下文会被破坏。如果批处理执行生成了一个警告(严重级别为 10),那么执行上下文就不会被破坏。因此,即便没有内存方面的压力——会导致计划缓存缩小,计划缓存中所缓存的(给定查询计划的)执行上下文的数量也会起伏不定。
不缓存并行计划的执行上下文。sql server 编译并行查询计划的一个必备条件是:满足了处理器关联掩码和“最高程度的并行”服务器级选项的值(可能是用“sp_configure”存储过程设置)后所剩下的处理器的最低数量大于 1。即使编译了并行查询计划,sql server 的“查询执行”组件也可能会从中生成一个串行执行上下文。不缓存派生自并行计划的任何执行上下文——串行或并行。但是,会缓存并行查询计划。
新闻热点






疑难解答













