现在来关注一下数据库镜像状态,从主服务器和数据库开始。
主服务器数据库状态
当safety设置为full,主数据库的正常操作状态时synchronized状态。当safety设置为off,主数据库的正常操作状态是synchronzing状态。
◆如果safety设置为full,主数据库的起始状态始终是synchronizing,当主数据库和镜像数据库事务日志同步后,数据库状态就转换成synchronized,
◆如果safety设置为full并且主服务器断开了和见证服务器的连接但依然可以进行事务处理,那么数据库状态为exposed。
◆如果safety设置为full并且主服务器无法和其他服务器组成quorum,那么将无法提供数据库服务。不允许任何的用户连接和事务处理。
下表显示了主数据库可能的状态,以及导致状态转换的一些事件。
表5:主数据库状态,safety为full以及safety为off
safety | 主服务器初始状态 | 事件 | 导致结果 | quorum | exposed | 能否提供数据库服务 |
full | synchronizing | 同步发生 | synchronized | 是 | 否 | 是 |
full | synchronized | 会话暂停 | suspended | 是 | 是 | 是 |
full | synchronized | 镜像服务器上出现redo错误 | suspended | 是,使用见证服务器 | 是 | 是 |
否,没有见证服务器 | - | 否 | ||||
full | synchronized | 镜像服务器不可用 | disconnected | 是,使用见证服务器 | 是 | 是 |
否,没有见证服务器 | - | 否 | ||||
off | synchronizing | 会话暂停 | suspended | - | 是 | 是 |
off | synchronizing | 镜像服务器上出现redo错误 | suspended | - | 是 | 是 |
off | synchronizing | 镜像服务器不可用 | disconnected | - | 是 | 是 |
当safety设置为full,主数据库首先进入synchronizing状态,只要和镜像数据库同步,两个伙伴都进入synchronized状态。当safety设置为off,伙伴数据库从synchronizing状态开始并在整个镜像过程中保持该状态。
对于这两个safety设置,如果会话被挂起或者出现了镜像服务器的redo错误,那么主数据库进入suspended状态。如果镜像服务器不可用,那么主数据库进入disconnected状态。
在disconnected和suspended状态下:
◆当safety设置为full,如果主服务器无法和见证服务器或者镜像服务器自称quorum,那么主数据库被视为exposed。这意味着主数据库为活动状态,支持用户连接和事务处理。 但是没有日志记录被发送到镜像数据库。因此如果主数据库失败了,那么镜像数据库不包含任何自主数据库进入exposed状态后主服务器上发生的事务。同样的,也不可以清理主数据库的事务日志,这导致日志文件的无限增长。
◆当safety设置为full,如果主服务器无法和其他服务器组成quorum,它将不能提供数据库服务。所有用户将被断开连接,也不允许新的事务处理。
◆当safety设置为off,朱数据库被视为exposed,因为没有事务日志记录被发送到镜像。
注意:management studio's object explorer会在server树图中数据库名称的旁边报告主数据库状态。将主数据库的synchronized状态报告为 'principal, synchronizing',disconnected状态报告为'principal, disconnected.'
镜像数据库状态
镜像数据库具有和主数据库相同的状态,但是由于镜像数据库始终处于nonrecovered状态,因此在担当镜像角色的时候不能提供数据库服务。下表显示了可以导致镜像服务器和数据库状态改变的一些最常见事件。
表6:镜像服务器状态,safety为full以及safety为off
safety | 镜像服务器状态 | 事件 | 导致的结果 |
full | synchronizing | 同步发生 | synchronized |
full | synchronized | 会话暂停 | suspended |
full | synchronized | 镜像服务器上出现redo错误 | suspended |
full | synchronized | 主数据库不可用 | disconnected |
off | synchronizing | 会话暂停 | suspended |
off | synchronizing | 镜像服务器上出现redo错误 | suspended |
和主数据库一样,management studio's object explorer在server树的数据库名称旁边报告镜像数据库状态。镜像数据库的synchronized状态报告为'mirror, synchronizing',disconnected状态报告为'mirror, disconnected.'
见证服务器状态
在sys.database_mirroring目录视图中有三种见证服务器状态,connected、 disconnected和unknown。
表7:witness服务器状态(记录在伙伴服务器上)
见证服务器状态 | 事件 | 导致的结果 |
connected | 见证服务器不可用 | disconnected |
主服务器无法初始化镜像 | unknown |
由于见证服务器状态真正记录在伙伴服务器而不是见证服务器上,因此这些状态是从有利于伙伴的角度来设置的,因此当您看到见证服务器为disconnected状态时,意味着伙伴和见证服务器断开了。数据库镜像启动后,如果镜像服务器无法与主服务器进行初始化,那么见证服务器进入unknown状态。
传输事务日志记录
sql server主服务器和镜像服务器传输消息和日志记录的次序根据事务安全性的设置而不同。我们先研究同步传输,然后再研究异步传输。
当sql server将事务事件记录在事务日志中时,日志记录被写入磁盘前暂时存放在日志缓冲区中。 数据库镜像时,每次日志缓冲区被输出到硬盘时(硬化),主服务器也将相同的日志记录块发送到镜像服务器。
1. 当safety设置为full,只要sql server主服务器硬化它的日志记录块,就同时将相同的日志记录块发送到镜像服务器,并认为本地的日志i/o和远程镜像服务器的日志i/o从本质上来说是一样 的。这种传输称为同步的,因为在一个事务提交之前,主服务器既要等待本地的i/o(硬化)还要等待等待镜像服务器有关完成i/o(硬化)的答复。
每次主服务器或者镜像服务器硬化日志缓冲区时,都会将缓冲区中最高的日志序列号(lsn)+ 1作为mirroring_failover_lsn记录在元数据中。
mirroring_failover_lsn用于协商事务日志最后的保障点,这样两个伙伴数据库就可以在初始化时保持同步,在故障转移后也保持同步。
当主服务器发送日志记录给镜像服务器时,主服务器上的mirroring_failover_lsn通常会提前一些。镜像服务器硬化日志记录时会记录其mirroring_failover_lsn,然后回复主服务器。但是等主服务器接收到来自镜像的确认信息时,主服务器可能已经开始硬化新的一组日志记录了。
表8显示了主服务器和镜像服务器safety为full时的一个事件序列示例。
表8:safety为full (同步传输)事件序列的示例
server a | server b |
principal, synchronized | mirror, synchronized |
开始一个包含数据更新的多语句事务 | |
主数据库的事务日志记录被放入事务日志缓冲区 | |
事务日志缓冲区内容被写入磁盘(硬化),日志记录块被发送到镜像服务器,主服务器记录日志块的 mirroring_failover_lsn,然后等待镜像服务器的确认。 | |
镜像服务器接收日志记录并放入事务日志缓冲区 | |
镜像服务器将日志缓冲区输出到磁盘,记录 mirroring_failover_lsn,然后通知主服务器日志块已被硬化 | |
主服务器接收日志记录已被镜像服务器硬化到磁盘的通知 | 镜像服务器继续重新执行redo队列中的事务日志 |
包含了commit的日志写入事务日志缓冲区 | |
事务日志缓冲区内容被写入磁盘(硬化), 包含了commit的日志记录块被发送到镜像服务器,主服务器记录日志块的 mirroring_failover_lsn,然后等待镜像服务器的确认。 | |
镜像服务器接收日志记录并放入事务日志缓冲区 | |
镜像服务器将日志缓冲区输出到磁盘,记录the mirroring_failover_lsn,然后通知主服务器日志块已被硬化 | |
主服务器接收日志记录已被镜像服务器硬化到磁盘的通知,至此整个事务提交 | 镜像服务器继续重新执行redo队列中包含了commit的事务日志,修改数据页面 |
新事务被写入主服务器的日志缓冲区 |
以上事件序列中关键的一点就是:当 safety设置为full时,主服务器硬化日志缓冲区以及将日志缓冲区中日志记录的副本发送到镜像服务器,二者是同时进行的。然后主服务器开始等待自己的i/o以及镜像服务器的i/o,两个i/o都完成后才认为事务完成了。当主服务器接收到来自镜像的答复后,再开始处理下一次硬化。
当safety设置为full时,尽管主服务器和镜像服务器之间协调紧密,但是数据库镜像不是分布式事务,也不使用两阶段提交协议。
◆在数据库镜像中,两个事务分别在两台服务器上执行,并不是一个跨服务器的分布式事务。
◆数据库镜像不使用伙伴服务器作为分布式事务中的资源管理器。
◆数据库镜像事务不经历准备和提交阶段。
◆最重要的是,镜像服务器上事务提交失败不会导致主服务器上的事务会滚,这一点与分布式事务不同。
2. 当safety设置为off时,主服务器不等待来自镜像服务器的确认消息,因此主服务器上已提交事务数量可能多于镜像服务器,如图9所示:
表9:safety为off (异步传输)事件序列的示例
server a | server b |
principal, synchronizing | mirror, synchronizing |
开始一个包含数据更新的多语句事务 | |
数据更新的事务日志记录被写入事务日志缓冲区 | |
事务日志缓冲区内容被强制输出到磁盘(硬化),日志记录块被发送到镜像服务器,主服务器记录日志块的 mirroring_failover_lsn | |
包含了commit的日志被写入事务日志缓冲区,加上其他的事务活动 | 镜像服务器接收日志记录并放入事务日志缓冲区 |
事务日志缓冲区内容被写入磁盘, 包含了commit的日志记录块被发送到镜像服务器 | 镜像服务器将日志缓冲区输出到磁盘,记录the mirroring_failover_lsn,然后通知主服务器日志块已被硬化 |
提交事务 | 镜像服务器继续重新执行redo队列中的事务日志 |
镜像服务器接收日志记录并放入事务日志缓冲区 | |
镜像服务器将日志缓冲区输出到磁盘,记录the mirroring_failover_lsn,然后通知主服务器日志块已被硬化 |
数据库镜像角色转换
可以从数据库镜像服务器或者应用程序的角度来思考数据库镜像故障转移问题。从数据库镜像服务器角度,故障转移就是将镜像服务器转换为主服务器,以及使用新恢复的数据库作为主数据库。故障转移可以是自动的、手动的、或者forced service。
◆自动的 – 只有高可用模式下才会产生(safety设置为full以及见证服务器的参与)
◆手动的 - 只有高可用和高保护操作模式下才会产生(safety设置为full),两个伙伴数据库都是synchronized。
◆forced service (允许数据丢失) - 主要是在高性能模式下(safety off)用于立刻和手动的恢复镜像数据库
当safety设置为full时,用于互换服务器角色的最好的方式是使用手动故障转移,而不是forced service。
自动故障转移
自动故障转移是高可用模式下(safety为full使用见证服务器)数据库镜像的功能。大多数情况下,sql server可以在几秒钟内完成自动故障转移。sql server可以进行局部自动故障转移,因为包含在数据库镜像会话中的sql服务器会彼此测试对方的存在。该过程称为“ping”,但包含的操作远不止一个普通的 ip地址ping。镜像服务器和见证服务器联系主服务器以检查主物理服务器是否存在、sql server是否存在、以及主数据库是否可用。类似的, 主服务器和见证服务器ping镜像服务器以检查镜像物理服务器和sql server实例的可用性,以及镜像数据库的还原状态。
假设使用safety full和见证服务器配置了数据库镜像。镜像服务器即server b通过ping发现主服务server a不可用。server b与见证服务器通信并收到见证服务器也看不到server a的确认消息。那么server b将和见证服务器组成quorum并将自己提升为主服务器角色。它将恢复它的数据库并且通知见证服务器如今自己担当了主服务器的角色(尽管数据库处于disconnected状态,新主数据库的事务日志也不能被截断)。
server b的新主数据库继续重新执行事务日志中的活动,但是它将持续redo状态而且大多数情况下只有很少的工作需要完成。在所有sql server版本中,新主数据库只要完成redo过程就立刻可用了。当数据库进入undo状态时将可以接收用户连接了。完成redo通常只需几秒钟,尽管余下的undo阶段时间可能很长。在数据库镜像中,新的主数据库只要redo阶段完成就可以为用户连接提供服务。新主服务器b的数据库处于disconnected状态而且是exposed,但是只要redo过程完成就可以提供数据库服务。
通常将整个应用程序从主服务器重新定向到新主服务器花费的时间要多于数据库镜像的自动故障转移。应用程序必须检测和重试连接,这样也会增加该过程的整体时间。此外,如果将新的sql server验证登陆账号添加到服务器,还需要使用系统存储过程sp_change_users_login将这些登陆账户映射到新主数据库的用户账户。如果旧的主服务器上一些关键对象,如sql agent作业还没有拷贝到新主服务器上,也会耽误应用程序故障转移的完成。(更多信息请阅读该白皮书实现数据库镜像部分的“为故障转移准备镜像服务器”)
现在假设旧的主服务器联机了。如果是手动故障转移,或者旧的主服务器被快速修复的自动故障转移场景,两台服务器需要进行角色互换,那么就必须进行一个协商过程。在数据库镜像重新开始之前,两台伙伴服务器需要决定彼此怎样进行同步。镜像故障转移lsn这个过程中扮演了一个关键角色。
server a (新镜像服务器)落后了,但它并不清楚自己落后了多少。server a向server b(新主服务器)报告它从server b接收的最后的镜像故障转移lsn。另一方面,server b由于某些提交的工作而导致它有最新的镜像故障转移lsn,server a必须要追赶上server b。server b将足够数量的事务日志发送给server a,使server a通过重新这些执行事务并与server b同步。
手动故障转移
手动故障转移就是依次交换两个伙伴服务器的角色。它要求safety设置为full,并且主服务器和镜像服务器处于synchronized状态。
在主服务器上使用下面的alter database命令进行手动故障转移:
| alter database adventureworks set partner failover; |
或者在management studio的database properties/mirroring对话框中单击failover按钮。手动故障转移在旧的主数据库上断开所有用户连接并回滚所有未完成的事务。通过完成所有redo队列中已提交的事务,回滚所有未完成的事务(在undo阶段)来恢复镜像数据库。旧的旧的镜像数据库被分配了主数据库角色,而旧的主数据库则担当新的镜像数据库角色。两台服务器根据它们的镜像故障转移lsn协商数据库镜像的新起点,然后处理角色互换。
可以使用手动故障转移作为实现操作系统或者sql server实例的‘滚动升级’的一种方式来,假如您在初始化镜像服务器之前首先升级镜像服务器。更多信息请参阅sql server books online中'manual failover' 主题。
forced service
在镜像服务器上使用alter database命令进行forced service:
alter database adventureworks set partner force_service_allow_data_loss; |
通常只有当safety为off并且主服务器再也无法运转时才使用这种方式。也可以在safety为full使使用该命令,但是如果恢复的镜像服务器无法组成quorum,它也不能提供数据库服务。因此最好在safety为off(高性能操作模式)是使用该命令。由于异步的数据传输无法保证镜像数据库包含所有主服务器上提交的最新事务,因此有些数据可能会丢失。
数据库镜像可用性场景
在这一部分,您将根据以下两类事件对数据库镜像预期的可用性结果进行研究:
◆一个或多个服务器或者数据库失败
◆服务器之间一条或多条通信连路失败
服务器失败可能是由于某个镜像伙伴数据库、或者某个sql server实例不可用。此外,即使服务器本身可以继续运转,但是数据库镜像伙伴服务器之间的通信连路可能中断。
以下场景中,两个组件的同时失败被视为一个组件紧接着另一个组件的顺序失败。例如,server a和b出现了同时失败,镜像系统将该事件视为一个顺序事件:server a失败然后server b失败,或者反过来。
使用下面的规则来判定一个不可用事件的预期结果:
1.当safety设置为full时,主服务器需要至少一台其他服务器才能形成quorum来保持数据库可用。
如果主服务器无法组成quorum,也就无法再提供数据库服务了。
2.当safety设置为full,如果镜像服务器和见证服务器都无法联系到主服务器,那么镜像服务器可以和见证服务器组成quorum并且改变其角色,使之成为新的主服务器。
这就是自动的故障转移。
3.当safety设置为full,如果主服务器和见证服务器合作组成quorum,但是断开了和镜像服务器的连接,那么主服务器失败将不允许镜像服务器和见证服务器组成quorum,也不允许镜像服务器承担主服务器的角色。
这样可以防止所做的工作由于会话中断而丢失。
4.当safety设置为full,如果失败的主服务器在停机或者孤立后重新加入会话,同时旧的镜像服务器已经承担了主服务器的角色(和见证服务器组成quorum),那么旧的主服务器将在此次会话中承担新镜像服务器角色。
在故障转移过程中,镜像服务器和见证服务器会增加镜像角色顺序计数器。因为主服务器的镜像角色顺序计数器 小于另一个伙伴服务器和见证服务器的顺序计数器,因此那两台服务器会在旧的主服务器重新加入会话之前组成quorum并开始工作。旧的主服务器担当起镜像的角色。
5.当safety设置为full并且会话中没有见证服务器,或者见证不知何故退出了会话,镜像伙伴服务器的失败将导致无法组成quorum,主服务器也因此不再保持主数据库可以使用。
无法组成quorum,因此不可能进行自动的故障转移,如果见证服务器不包含在safety为full的会话中。
高可用场景中服务器失败
高可用操作模式下的数据库镜像其目的就是尽可能增加数据库的可用性。在这种模式下,如果主数据库无法访问,那么数据库镜像将迅速使镜像数据库可以接受访问。在下面的一组场景中,我们的讨论将从高可用配置加上三台独立的服务器开始。
在下面的高可用场景中,server a作为主服务器启动,server b是镜像服务器,而server w是见证服务器,如图1所示:
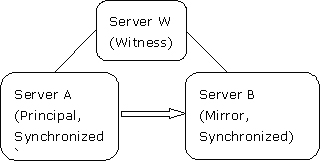
图1:示例数据库镜像会话在高可用操作模式下启动
所有这三台服务器可以在同一个站点使用局域网连接,也可以在不同的站点使用wan进行连接。server a和server b可以互换角色,但是server w始终作为见证服务器。
现在来考虑如果其中一台服务器出现故障时产生的结果。
场景 hasl1.1:主服务器失败
下面的场景分析了在高可用模式下主服务器失败时会发生什么。图 2显示了不同的角色,以及镜像伙伴之间如何做角色转换。

图2:在高可用模式下,当主服务器server a失败,故障转移发生
主服务器server a失败后,镜像和见证服务器组成quorum,自动的故障转移产生。如果重新恢复了原始的主服务器,它将担当起镜像服务器的角色。
注意:要导致高可用模式下的故障转移,失败可以发生在不同的级别上:服务服务器可能停机、主服务器上的sql server实例可能停止或者失败、服务器上的主数据库可能不可用或状态可疑。在下面场景中,主服务器失败可能由这些事件中的任何一个引起。
因为server b和w可以组成quorum,并且二者均无法联系server a,那么server b可以将自己提升为新的主服务器。但是如果没有镜像服务器,镜像会话就被认为是exposed。
server a恢复后,它成为新的主服务器,镜像会话也不再是exposed。
单服务器失败事件并不多见,两台服务器失败就更少见了,因此研究在这种情况下出现的结果十分有用。
两台服务器可以同时或者几乎同时失败,但从数据库镜像的角度来看,其结果被视为一台服务器失败紧接着另一台也失败了。因此这些场景只考虑当多台服务器顺序失败时的后果。
接下来的两个场景分析主服务器 server a失败,紧接着其他两台服务器也失败时会产生的结果。
◆新的主服务器 server b失败;
◆见证服务器 server w失败;
场景 hasl1.2:主服务器失败,随后新的主服务器失败
同前面的场景一样,在高可用操作模式下,如果主服务器首先失败,那么故障转移发生。图3显示了如果新的主服务器接下来也失败了,那么无论怎样恢复这些服务器,新的主服务器(server b)始终保持其主服务器的角色。
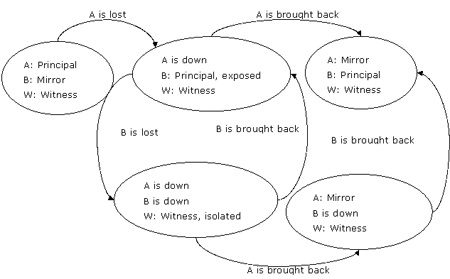
图3:由于主服务器失败,接着新主服务器也失败而导致角色转换
server a失败后,server b成为新的主服务器,但是无法将数据发送给镜像服务器,因此主服务器处于exposed,即使它仍然提供数据库服务。当server a失败紧接着server b也失败,那么就不存在数据库镜像了,因为server b已经停工了。
如果server a首先恢复,它从见证服务器的mirroring_role_sequence号中检测到见证服务器已经组成了新的quorum。
server a接纳了镜像服务器的角色,然后等待server b恢复。server b一旦恢复,立刻开始了和server a的数据库镜像过程。如果server b先恢复,那么就重新回到了在hasl1。1中显示的初始场景。
注意:如果server w在server a和server b相继失败后也宣告失败,导致所有三台服务器均停工,那么无论以什么次序恢复见证服务器,已经转换完成的server a和server b的角色将保持不变。
场景 hasl1.3:主服务器失败,随后见证服务器失败
主服务器失败后发生故障转移。见证服务器可能接下来也失败,如图4所示:
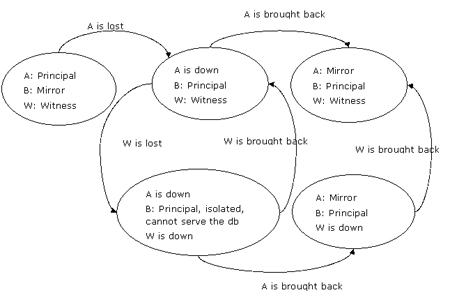
图4:见证服务器紧随原始主服务器出现失败,那么新主服务器无法提供数据库服务
当见证服务器 server w主服务器 server a失败后也出现失败,那么新主服务器 server b依然为主服务器但被孤立,无法组成quorum,也不能提供数据库服务。
如果server a首先恢复,server b的mirroring_role_sequence号将比server a的大1,因为产生了故障转移。这些信息指示server a如今server b在server a只有担当了主服务器的角色。server a和server b组成quorum 并成为一对镜像,此后两台服务器保持同步。除非server w恢复,否则不会产生自动故障转移。
注意: 如果server w在server a和server b相继之后也宣告失败,那么无论以什么次序恢复见证服务器,已经转换完成的server a和server b的角色将保持不变。
场景 hasl2.1:镜像服务器失败
如果镜像服务器首先失败,那么主服务器被视为exposed,因为它无法发送数据给镜像服务器。图 5显示了server b,即镜像服务器失败时的行为。
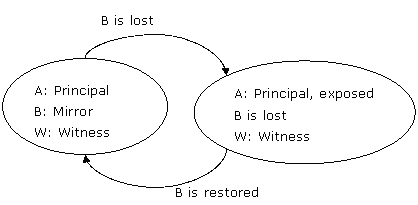
图5:在高可用模式下,当镜像服务器server b失败时不产生故障转移
没有自动故障转移发生,镜像伙伴也不会交换角色。当server b恢复时,所有三台服务器还原到其初始角色和状态。
下表显示了镜像服务器server b失败以及恢复时数据库状态。
由于没有镜像服务器,数据无法存放在冗余数据库中,因此会话处于exposed。
server b一旦恢复立刻重新担当起它的镜像服务器角色。只要两台服务器同步,镜像会话就不再被视为exposed。
接下来的两个场景考虑镜像服务器server b失败,紧接着主服务器server a或者见证服务器server w失败时产生的结果。
场景 hasl2.2:镜像服务器失败,随后主服务器失败
紧随镜像服务器之后主服务器也失败了,镜像伙伴服务器的角色保持不变。图6显示了采用不同方式还原服务器时角色将如何转换。
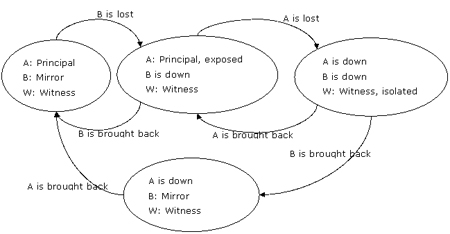
图6:镜像服务器失败随后主服务器主失败,那么见证服务器被孤立
在server b和server a都失败后,各服务器状态显示在图中的右上角处。
如果server b首先恢复,它将从见证服务器server w处检测到server a依然为主服务器并且还没有产生故障转移,mirroring_failover_lsn也没有增加。其结果为,server b依然为镜像服务器。server w恢复后将会话还原到初始状态。
注意:如果server w在server b和server a相继失败之后也宣告失败了,那么以任何顺序还原这些服务器将导致相同结果。
场景 hasl2.3:镜像服务器失败,随后见证服务器失败
镜像服务器失败,随后见证服务器也失败,那么主服务器被孤立并且无法和任何其他服务器组成quorum。因此它必须停止数据库的工作,如图7右上角所示。
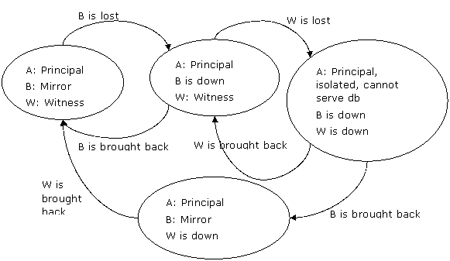
图7:a镜像服务器失败,随后见证服务器失败,导致主服务器无法提供数据库服务
由于镜像服务器故障以及随后的见证服务器失败,主服务器 server a保持其主服务器角色,由于无法和任何其他服务器组成quorum,而safety又被设置成full,因此不再为数据库提供服务,并断开所有的用户连接。
如果server b首先恢复,那么数据库镜像将重新开始工作,尽管由于缺失见证服务器而不会产生自动故障转移。
如果server w首先恢复,那么情况与图5中显示的一样。
注意:如果server a在server b和server w相继失败之后也宣告失败,那么以任何次序还原这些服务器其最终结果保持不变。
场景 hasl3.1:见证服务器失败
见证服务器失败时,数据库镜像继续进行但是不可能产生自动的故障转移。如果再有一台或多台服务器失败,就意味着没法组成quorum,那么主服务器上的数据库也不再服务于数据库用户。
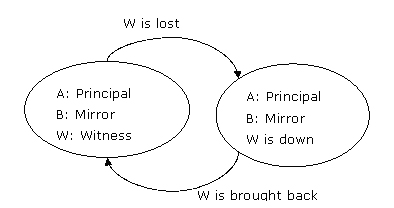
图8:在高可用模式下,见证服务器server w首先失败,那么数据库镜像继续
server w恢复后,两个伙伴服务器server a和server b维持它们的初始角色。
下表显示了见证服务器失败以及恢复后,数据库状态以及quorum的变化。
下面的两个场景考虑见证服务器server w失败,紧接着主服务器 server a或者镜像服务器server b失败时产生的结果。
场景 hasl3.2:见证服务器失败,随后主服务器失败
见证服务器首先失败,那么数据库镜像将继续进行,但是不可能产生自动的故障转移。其余两台服务器中任何一台失败将导致无法组成quorum,余下的那台服务器将被孤立。
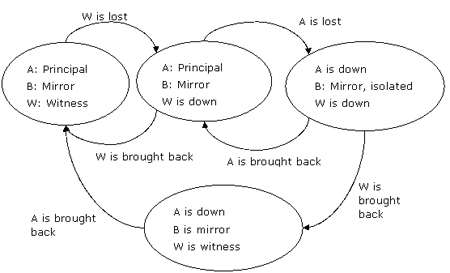
图9:原始见证服务器失败,随后主服务器失败,镜像伙伴角色保持不变
如果server w首先恢复,那么server b将从见证服务器那里检测到最后的主服务器是server a,同时server b依然是镜像服务器。最终server a恢复时,它将保持其主服务器角色。
注意: 如果server b在server w和server a相继失败后也宣告失败了,那么以任意次序还原这些服务器都不会影响最终结果。
场景 hasl3.3:见证服务器失败,随后镜像服务器失败
如果见证服务器失败,随后镜像服务器也失败,那么主服务器被孤立。由于safety设置为full并且主服务器无法组成quorum,它将不再提供数据库服务,如图10所示。
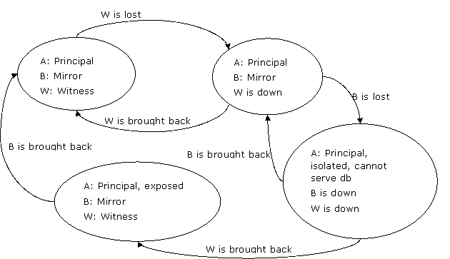
图10:见证服务器失败,随后镜像服务器失败,主服务器必须停止其数据库服务
注意: 如果server a在server w和server b相继失败之后也宣告失败, 那么以任意次序还原这些服务器都不会影响最终结果。
总结:高可用场景中服务器失败
从这些场景中可以得出几个结论。在高可用操作模式下:
1.如果主服务器首先不可用,那么产生自动的故障转移,原先的镜像服务器将担当主服务器角色,并使其数据库服务于用户活动。后续的服务器失败和恢复不会影响使用新主服务器的数据库镜像的整体配置。数据库镜像将以相反的方向继续进行。
2.如果镜像首先不可用,那么产生自动的故障转移 。后续的服务器失败以及恢复次序都不会影响镜像伙伴角色。
3.如果见证服务器首先不可用,那么不可能产生自动的故障转移,镜像伙伴服务器将保持其初始角色。后续的服务器失败以及恢复都不会影响镜像伙伴角色。
下表总结了在高可用场景中出现一台或两台服务器失败时产生的结果。表中假设的条件是safety设置为full并且镜像会话中的服务器满足下列条件:
a:主服务器, synchronized
b:镜像服务器,synchronized
w:见证服务器,connected
表中使用灰色加亮显示故障转移场景。
表10:总结:单服务器或者双服务器失败,显示伙伴服务器角色和数据库状态
高可用场景中通信失败
高可用操作模式需要三个sql sever实例。如果这些服务器位于两个或三个独立的物理站点并且相距很远,那么这些站点间的通信就很可能出现问题。换句话说,服务器依然运转但是彼此间的通信连路中断了。这种情况比前面的那些场景要复杂一些,但原理是一样的。
下面高可用操作场景中通信失败的研究将通过两组来完成。第一组是基于三个来自不同站点的sql server实例,因此有三条独立的通信连路。第二组是基于两个独立站点上的服务器,第一个站点上的一对服务器和第二个站点上的第三台服务器之间有一条通信连路。
先从第一组开始,假设一个数据库会话中所有三台服务器之间有三条独立的通信连路。例如,主服务器、镜像服务器和见证服务器位于三个独立的协作站点上(也有可能三台服务器位于同一个站点,但使用私有网络连接)
初始条件是server a上运行主数据库并且与其镜像伙伴server b保持同步。
server b上是镜像数据库safety设置为full,见证服务器 (server w)也包含在数据库镜像会话中。图11显示了初始配置。
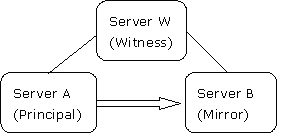
图11:高可用配置中三台独立服务器、三条独立通信连路的初始状态
注意:要获得页面上图表的解释,请参阅前面介绍的“高可用场景中服务器失败”
根据图11,三条链路可能首先中断:a/b, a/w和b/w。注意当某条通信连路中断时,所有三台服务器依然运转正常。只有主服务器和镜像服务器之间的通信连路有一些影响,如表11所示。
表11:总结:单条通信连路中断
初始条件 | 事件 | quorum | 结果 | 条件 |
a: 主服务器, synchronized b: 镜像服务器, synchronized w: 见证服务器, connected | a/b连路中断 | a和w | a上的数据库提供服务, exposed | a: 主服务器, disconnected b: 镜像服务器, disconnected w: 见证服务器, connected |
a/w | a和b | a上的数据库提供服务 | a: 主服务器, synchronized b: 镜像服务器, synchronized w: 见证服务器, connected | |
b/w | a和b | a上的数据库提供服务 | a: 主服务器, synchronized b: 镜像服务器, synchronized w: 见证服务器, connected |
只有主服务器/镜像服务器的连接中断会对镜像造成影响。其他的连路中断,例如主服务器/见证服务器或者镜像服务器/见证服务器之间的通信中断不会改变数据库镜像会话的行为。
总之,表hacl1显示出:
◆所有单条链路中断场景中只有主服务器/镜像服务器链路中断会影响数据库镜像,主服务器运行 状态为exposed,因为没有日志记录发送到镜像。
现在考虑如果第二条连路中断产生的结果。两条连路可以同时中断,也可以相继中断。
如果两条连路同时中断,其最终结果与两条连路相继中断是一样的。但是无法事先预料中断的先后顺序;只有知道了先后次序才能够据此分析链路同时中断的结果。
由于这个原因,我们只考虑链路顺序中断的情形。表12列出了高可用模式中通信链路中断的一些基本场景。
表12:大部分双-通信链路中断的结果与服务器故障场景中单机故障是一样的
场景 | 第一条连路中断 | 场景 | 第一条连路中断 | 结果 | 其余服务器的等价场景 | 参阅场景 |
hacl1.1 | a/b | hacl1.2 | a/w | server a被孤立 | server a停机 | 无 |
hacl1.3 | b/w | server b 被孤立 | server b 停机 | hasl2.1 | ||
hacl2.1 | a/w | hacl2.1 | a/b | server a 被孤立 | server a 停机 | hasl1.1 |
hacl2.2 | b/w | server w 被孤立 | server w 停机 | hasl3.1 | ||
hacl3.1 | b/w | hacl3.1 | a/w | server w 被孤立 | server w 停机 | hasl3.1 |
hacl3.2 | a/b | server b 被孤立 | server b 停机 | hasl2.1 |
表hacl2显示所有顺序的双-通信链路失败都等价于前一部分介绍的单服务器故障场景,因此我们不再这里对它们作重复分析了。
值得注意的一点是:
◆两条链路中断时只有一个场景会产生故障转移:主服务器/见证服务器链路中断,随后主服务器/镜像服务器链路中断。
如果主服务器/镜像服务器链路中断,随后主服务器/见证服务器也出现链路中断,那么不会产生故障转移,即使主服务器被孤立而且镜像服务器和见证服务器无法联系上它。
我们再仔细研究一下场景 hacl1.2。
场景 hacl1.2:主服务器/镜像服务器连路中断,随后主服务器/见证服务器链路中段
如果主服务器/镜像服务器链路中段,随后主服务器和见证服务器之间的链路也中断了,那么主服务器被孤立。它看不到其他服务器并且失去了它的quorum。同时,镜像服务器和见证服务器无法知道主服务器是否依然健在,因此server b担当起主服务器,然后自动的故障转移产生。图12显示了这些事件。
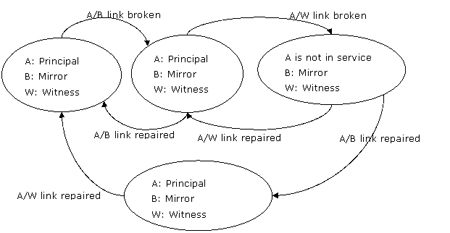
图12:在高可用模式下, 主服务器/镜像服务器链路中段,随后主服务器/见证服务器链路中段,不产生故障转移
当主服务器/镜像服务器以及主服务器/见证服务器之间的通信链路相继中断有,server a被孤立并使其数据库停止服务。server b和w无法形成quorum,因为server a可能执行了一些server b上没有的工作。
如果主服务器/见证服务器 (a/w) 链路中断首先修复,那么server a继续担当其主服务器角色,状态为disconnected。但是不会进行数据库镜像,因为主服务器和镜像服务器之间的连接还没有修复。
如果主服务器/镜像服务器 (a/b) 链路中断首先修复,那么server a将继续与server b的数据库竞相,即使没有见证服务器,因此该会话是exposed。除非主服务器/见证服务器连接最终被修复,否则不会产生自动的故障转移。
总结:高可用场景中通信失败:三个站点
下表总结了使用三台独立物理服务器时单链路和双-链路中断的行为。
表中的初始条件是safety设置为full,服务器分别是:
a:主服务器, synchronized
b:镜像服务器, synchronized
w:见证服务器, connected
使用灰色加亮显示故障转移路径。
表13:总结:单条链路中断和双-链路中断,高可用模式,三台独立服务器,safety设置为full
场景 hacl4:两个站点,见证服务器位于镜像服务器站点
如果所有服务器之间仅有一条通信连路,那么必须选择见证服务器的位置。首先,假设见证服务器和镜像数据库服务器放置在一起。两组服务器之间仅有一条通信连路,该链路可能中断,如图13所示。
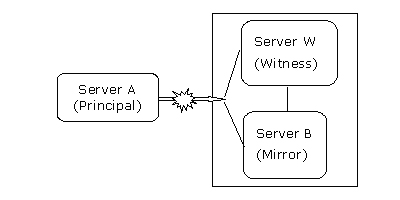
图13:主服务器和镜像服务器/见证服务器站点之间的通信连路中断了
server a看不到见证服务器server w或者镜像数据库服务器server b,因此无法组成quorum。 server b和server w可以组成quorum,但二者均无法看见主服务器server a。链路中断的结果显示在图14。
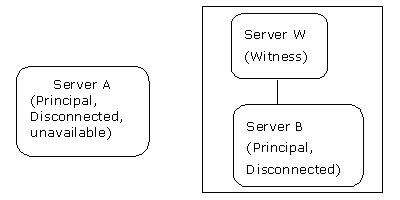
图14:通信连路中断并且见证服务器位于镜像服务器站点,产生故障转移
新闻热点






疑难解答













