概述
当你的sql server数据库系统运行缓慢的时候,你或许多多少少知道可以使用sql server profiler(中文叫sql事件探查器)工具来进行跟踪和分析。是的,profiler可以用来捕获发送到sql server的所有语句以及语句的执行性能相关数据(如语句的read/writes页面数目,cpu的使用量,以及语句的duration等)以供以后分析。但本文并不介绍如何使用profiler 工具,而是将介绍如何使用read80trace(有关该工具见后面介绍)工具结合自定义的存储过程来提纲挈领地分析profiler捕获的trace文件,最终得出令人兴奋的数据分析报表,从而使你可以高屋建瓴地优化sql server数据库系统。
本文对那些需要分析sql server大型数据库系统性能的读者如dba等特别有用。在规模较大、应用逻辑复杂的数据库系统中profiler产生的文件往往非常巨大,比如说在profiler中仅仅配置捕获基本的语句事件,运行二小时后捕获的trace文件就可能有gb级的大小。应用本文介绍的方法不但可以大大节省分析trace的时间和金钱,把你从trace文件的海量数据中解放出来,更是让你对数据库系统的访问模式了如指掌,从而知道哪一类语句对性能影响最大,哪类语句需要优化等等。
profiler trace文件性能分析的传统方法以及局限
先说一下什么是数据库系统的访问模式。除了可以使用trace文件解决如死锁,阻塞,超时等问题外,最常用也是最主要的功能是可以从trace文件中得到如下三个非常重要的信息:
1.运行最频繁的语句
2.最影响系统性能的关键语句
3.各类语句群占用的比例以及相关性能统计信息
本文提到的访问模式就是上面三个信息。我们知道,数据库系统的模块是基本固定的,每个模块访问sql server的方式也是差不多固定的,具体到某个菜单,某个按钮,都是基本不变的,所以,在足够长的时间内,访问sql server的各类语句及其占用的比例也基本上是固定的。换句话说,只要profiler采样的时间足够长(我一般运行2小时以上),那么从trace文件中就肯定可以统计出数据库系统的访问模式。每一个数据库系统都有它自己独一无二的访问模式。分析profiler trace文件的一个重要目标就是找出数据库系统的访问模式。一旦得到访问模式,你就可以在优化系统的时候做到胸有成竹,心中了然。可惜直到目前为止还没有任何工具可以方便地得到这些信息。
传统的trace分析方法有两种。一种是使用profiler工具本身。比如说可以使用profiler的filter功能过滤出那些运行时间超过10秒以上的语句,或按照cpu排序找出最耗费cpu的语句等。另一种是把trace文件导入到数据库中,然后使用t-sql语句来进行统计分析。这两种方法对较小的trace文件是有效的。但是,如果trace文件数目比较多比较大(如4个500mb以上的trace文件),那么这两种方法就有很大的局限性。其局限性之一是因为文件巨大的原因,分析和统计都非常不易,常常使你无法从全局的高度提纲挈领地掌握所有语句的执行性能。你很容易被一些语句迷惑而把精力耗费在上面,而实际上它却不是真正需要关注的关键语句。局限性之二是你发现尽管很多语句模式都非常类似(仅仅是执行时参数不同),却没有一个简单的方法把他们归类到一起进行统计。简而言之,你无法轻而易举地得到数据库系统的访问模式,无法在优化的时候做到高屋建瓴,纲举目张。这就是传统分析方法的局限性。使用下面介绍的read80trace工具以及自定义的存储过程可以克服这样的局限性。
read80trace工具介绍以及它的normalization 功能
read80trace工具是一个命令行工具。使用read80trace工具可以大大节省分析trace文件的时间,有事半功倍的效果。read80trace的主要工作原理是读取trace文件,然后对语句进行normalize (标准化),导入到数据库,生成性能统计分析的html页面。另外,read80trace可以生成rml文件,然后ostress工具使用rml文件多线程地重放trace文件中的所有事件。这对于那些想把profiler捕获的语句在另外一台服务器上重放成为可能。本文不详细介绍read80trace或ostress工具,有兴趣的读者请自行参阅相关资料,相关软件可以从微软网站下载(注:软件名称为rml)
http://www.microsoft.com/downloads/
我要利用的是read80trace的标准化功能。什么是标准化?就是把那些语句模式类似,但参数不一样的语句全部归类到一起。举例说trace中有几条语句如下:
select * from authors where au_lname = 'white'
select * from authors where au_lname = 'green'
select * from authors where au_lname = 'carson'
经过标准化后,上面的语句就变成如下的样子:
select * from authors where au_lname = {str}
select * from authors where au_lname = {str}
select * from authors where au_lname = {str}
有了标准化后的语句,统计出数据库系统的访问模式就不再是难事。运行read80trace 的时候我一般使用如下的命令行:
read80trace –f –dmydb –imytrace.trc
其中-f开关是不生成rml文件,因为我不需要重放的功能。生成的rml文件比较大,建议读者如果不需要重放的话,也使用-f开关。
-d开关告诉read80trace把trace文件的处理结果存到mydb数据库中。我们后面创建的存储过程正是访问read80trace在mydb中生成的表来进行统计的。-i开关是指定要分析的的trace文件名。read80trace工具很聪明,如果该目录下有profiler产生的一系列trace文件,如mytrace.trc,mytrace1.trc,mytrace2.trc等,那么它会一一顺序读取进行处理。
除了上面介绍的外,read80trace还有很多其它有趣的开关。比如说使用-i开关使得read80trace可以从zip或cab文件中读取trace文件,不用自己解压。所有开关在read80trace.chm中有详细介绍。我最欣赏的地方是read80trace的性能。分析几个gb大小的trace文件不足一小时就搞定了。我的计算机是一台内存仅为512mb的老机器,有这样的性能我很满意。
你也许会使用read80trace分析压力测试产生的trace文件。我建议还是分析从生产环境中捕获的trace文件为好。因为很多压力测试工具都不能够真正模拟现实的环境,其得到的trace文件也就不能真实反映实际的情况。甚至有些压力测试工具是循环执行自己写的语句,更不能反映准确的访问模式。建议仅仅把压力测试产生的trace作为参考使用。
使用存储过程分析normalize后的数据
有了标准化后的语句就可以使用存储过程进行统计分析了。分析的基本思想是把所有模式一样的语句的reads,cpu和duration做group by统计,得出访问模式信息:
1.某类语句的总共执行次数,平均读页面数(reads)/平均cpu时间/平均执行时间等。
2.该类语句在所有语句的比例,如执行次数比例,reads比例,cpu比例等。
存储过程的定义以及说明如下:
create procedure usp_getaccesspattern 8000
@duration_filter int=-1 --传入的参数,可以按照语句执行的时间过滤统计
as begin
/*首先得到全部语句的性能数据的总和*/
declare @sum_total float,@sum_cpu float,@sum_reads float,@sum_duration float,@sum_writes float
select @sum_total=count(*)*0.01,--这是所有语句的总数。
@sum_cpu=sum(cpu)*0.01, --这是所有语句耗费的cpu时间
@sum_reads=sum(reads)*0.01, --这是所有语句耗费的reads数目,8k为单位。
@sum_writes=sum(writes)*0.01,--这是所有语句耗费的writes数目,8k为单位。
@sum_duration=sum(duration)*0.01--这是所有语句的执行时间总和。
from tblbatches --这是read80trace产生的表,包括了trace文件中所有的语句。
where duration>[email protected]_filter --是否按照执行时间过滤
/*然后进行group by,得到某类语句占用的比例*/
select ltrim(str(count(*))) exec_stats,''+ str(count(*)/@sum_total,4,1)+'%' execratio,
ltrim(str(sum(cpu)))+' : '++ltrim(str(avg(cpu))) cpu_stats,''+str(sum(cpu)/@sum_cpu,4,1)+'%' cpuratio,
ltrim(str(sum(reads) ))+' : '+ltrim(str(avg(reads) )) reads_stats,''+str(sum(reads)/@sum_reads,4,1) +'%' readsratio ,
--ltrim(str(sum(writes) ))+' : '+ltrim(str(avg(writes) )) --writes_stats,''+str(sum(writes)/@sum_writes,4,1) +'%)',
ltrim(str(sum(duration) ))+' : '+ltrim(str(avg(duration))) duration_stats,''+str(sum(duration)/@sum_duration,4,1)+'%' durratio ,
textdata,count(*)/@sum_total tp,sum(cpu)/@sum_cpu cp,sum(reads)/@sum_reads rp,sum(duration)/@sum_duration dp
into #queries_staticstics from
/* tbluniquebatches表中存放了所有标准化的语句。*/
(select reads,cpu,duration,writes,convert(varchar(2000),normtext)textdata from tblbatches
inner join tbluniquebatches on tblbatches.hashid=tbluniquebatches.hashid where duration>@duration_filter
) b group by textdata --这个group by很重要,它对语句进行归类统计。
print 'top 10 order by cpu+reads+duration'
select top 10 * from #queries_staticstics order by cp+rp+dp desc
print 'top 10 order by cpu'
select top 10 * from #queries_staticstics order by cp desc
print 'top 10 order by reads'
select top 10 * from #queries_staticstics order by rp desc
print 'top 10 order by duration'
select top 10 * from #queries_staticstics order by dp desc
print 'top 10 order by batches'
select top 10 * from #queries_staticstics order by tp desc
end
考虑到输出结果横向较长,存储过程中把writes去掉了。这是因为大部分的数据库系统都是reads为主的。你可以轻易的修改存储过程把write也包括进去。
存储过程并不复杂,很容易理解。可以看到统计的结果放在queries_staticstics表中,然后按照不同的条件排序后输出。举例说:
select top 10 * from #queries_staticstics order by cp desc
上面的语句将把queries_staticstics表中的记录按照某类语句占用总cpu量的比例cp(即sum(cpu)/@sum_cpu)进行排序输出。这让你在分析服务器cpu性能问题的时候快速定位哪一类语句最耗cpu资源,从而对症下药。
现在让我们看一个实例的输出:
use mydb
exec usp_getaccesspattern
/*你可以输入一个执行时间作为过滤参数,毫秒为单位。如usp_getaccesspattern 1000*/
输出结果如图 1所示(是部分结果,另外,因为原输出结果横向很长,为方便阅读,把结果从中截断为两部分):
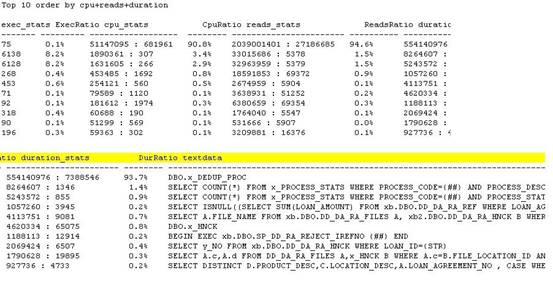
图 1:输出结果采样一
上面的例子采样于一家大型公司的业务系统。该系统的问题是应用程序运行缓慢,sql server 服务器的cpu高居不下(8个cpu都在90%~100%间波动)。我使用pssdiag工具采样2小时左右的数据,然后运行read80trace和usp_getaccesspattern得出上面的结果。报表一目了然。存储过程dbo.x_dedup_proc在两小时内共运行75次,却占用了90.8%的cpu资源,94.6%的reads,从访问模式的角度,该存储过程正是导致cpu高和系统性能慢的关键语句。一旦优化了该存储过程,系统的性能问题将迎刃而解。你也许有疑问,两小时内共运行75次,不是很频繁啊。其实你看看这条存储过程的平均cpu时间是681961毫秒,大概11分钟左右。也就是说一个cpu两小时内最多可以执行(60*2)/11=10条左右,该系统总共有8个cpu,即使全部cpu都用来运行该语句,那么最多也就是10*8=80条左右。上面执行总数是75,说明该存储过程一直在连续不断地运行。
那么该系统运行最频繁的语句是什么呢?我从结果中摘取另外一部分如下(图 2):
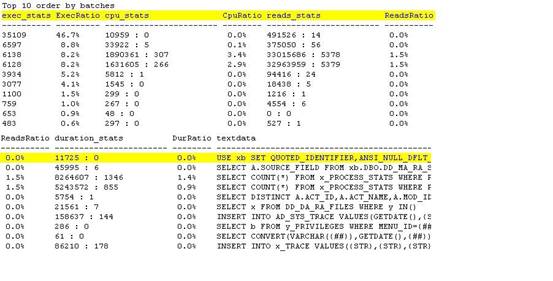
图 2:输出结果采样二
从上表可以看出,最频繁运行的语句是
use xb set quoted_identifier,ansi_null_dflt_on…
显然这是一条执行环境配置语句,没有参考价值。倒是另外两条占用语句总数8.2%的语句值得关注:
select count(*) from x_process_stats where process……
select count(*) from x_process_stats where process……
在这个例子中,因为关键语句dbo.x_dedup_proc非常突出,甚至上面的两条语句都可以忽略了。
让我们再多看一个例子(图 3):

图 3:输出结果采样三
从上面的例子中, 可以得出关键的语句是:
select count(*) from gtbl7ms
select caseno from patientdata_sum where mrn = @p1
后续的检查发现相关的表没有有效的索引,加上索引后性能立即整体地提高了不少.。解决了这两个语句,需要使用同样的手段继续分析和优化,直到系统的性能能够接受为止.。注意性能调优是一个长期的过程,你不太可能一两天就可以把所有的问题都解决。也许一开始可以解决80%的问题,但是后面20%的问题却需要另外80%的时间。
使用usp_getaccesspattern的一些技巧
usp_getaccesspattern的输出报表包含了非常丰富的信息。分析报表的时候需要有大局观。你也可以有目的性地选择你需要的信息。如果是cpu性能瓶颈的系统,那么你需要关注cpu占用比例高的那类语句。如果是磁盘io出现性能瓶颈那么你需要找到那些reads占用比例大而且平均reads也很高的语句。需要注意的是有时候运行频繁的语句未必就是你需要关注的关键语句。一个最理想的情况是关键语句正好就是最频繁的语句。有时候即使最频繁语句占用的资源比例不高,但如果还可以优化,那么因为放大效应,微小的优化也会给系统带来可观的好处。
在使用usp_getaccesspattern的时候多结合@duration_filter参数使用。因为参数以毫秒为单位,建议参数不要小于1000,而应该是1000的倍数 如3000,5000等。该参数常常会给出非常有意思的输出。该输出和不带参数运行的结果会有某些重叠。重叠出现的语句通常正是需要关注的语句。要注意运行最多最密的语句未必有超过1000毫秒的执行时间,所有带参数运行的结果有可能不包括最频繁语句。我常常同时交叉分析四个结果,一个是不带参数运行得到的,另三个分别是使用1000,3000和5000毫秒为参数运行的结果。比较分析这四个结果往往使我对数据库系统的访问模式有非常清晰透彻的理解。
运行存储过程时你也许会碰到int整数溢出的错误。这是因为表tblbatches 中的reads,cpu 和writes字段是int而不是bigint。可以运行如下语句进行修正:
alter table tblbatches alter column reads bigint
alter table tblbatches alter column cpu bigint
alter table tblbatches alter column writes bigint
修正后溢出问题就会解决。
蛇足:哪个是hot 数据库?
本文到这里就基本上结束了。你已经知道如何使用read80trace和usp_getaccesspattern得到数据库系统的访问模式,以及如何从全局的高度去分析访问模式报表,从而在优化系统的时候做到提纲挈领,胸有成竹。
除此之外,你还可以应用类似的分析思想得到每个数据库的占用资源比例。这对于sql server有多个数据库的情况非常有用。从报表中你可以立即知道哪个数据库是最hot最消耗系统资源的数据库。语句如下:
print 'group by dbid'
declare @sum_total float,@sum_cpu float,@sum_reads float,@sum_duration float,@sum_writes float
select @sum_total=count(*)*0.01,@sum_cpu=sum(cpu)*0.01,@sum_reads=sum(reads)*0.01,@sum_writes=sum(writes)*0.01,
@sum_duration=sum(duration)*0.01 from tblbatches
select dbid,
ltrim(str(count(*))) exec_stats,''+ str(count(*)/@sum_total,4,1)+'%' execratio,
ltrim(str(sum(cpu)))+' : '++ltrim(str(avg(cpu))) cpu_stats,''+str(sum(cpu)/@sum_cpu,4,1)+'%' cpuratio ,
ltrim(str(sum(reads) ))+' : '+ltrim(str(avg(reads) )) reads_stats,''+str(sum(reads)/@sum_reads,4,1) +'%' readsratio ,
ltrim(str(sum(duration) ))+' : '+ltrim(str(avg(duration))) duration_stats,''+str(sum(duration)/@sum_duration,4,1)+'%' durratio ,
count(*)/@sum_total tp,sum(cpu)/@sum_cpu cp,sum(reads)/@sum_reads rp,sum(duration)/@sum_duration dp
into #queries_staticstics_groupbydb from
(select reads,cpu,duration,writes,convert(varchar(2000),normtext)textdata,dbid from tblbatches
inner join tbluniquebatches on tblbatches.hashid=tbluniquebatches.hashid
) b group by dbid order by sum(reads) desc
select dbid,execratio batches,cpuratio cpu,readsratio reads,durratio duration
from #queries_staticstics_groupbydb
下面是一个上面语句结果的一个例子:
dbid batches cpu reads duration
------ ------- ----- ------- --------
37 21.1% 18.7% 29.1% 27.1%
33 12.7% 32.4% 19.5% 24.8%
36 5.6% 28.3% 15.6% 26.1%
20 53.9% 2.9% 14.2% 2.1%
22 0.8% 7.2% 13.2% 6.6%
25 1.0% 3.6% 5.4% 3.5%
16 0.0% 1.5% 1.9% 0.7%
35 2.0% 2.7% 1.8% 5.7%
7 0. 1% 0.1% 1.1% 0.3%
上面的结果明确地告诉我们id为37,33和36的数据库是最活跃的数据库。一个有趣的事实是数据库20发出的语句总数比例是53.9%,但是其占用的系统资源比例却不高。
中国最大的web开发资源网站及技术社区,新闻热点






疑难解答













