默认nginx不支持tcp的负载均衡,需要打补丁,(连接方式:从客户端收到一个连接,将从本地新建一个连接发起到后端服务器),具体配置如下:
一、安装Nginx
1.下载nginx
2.下载tcp模块补丁
源码主页: https://github.com/yaoweibin/nginx_tcp_proxy_module
3.安装nginx
二、修改配置文件
修改nginx.conf配置文件
三、启动nginx
查看1433端口:
四、测试
五、使用sql server client工具测试

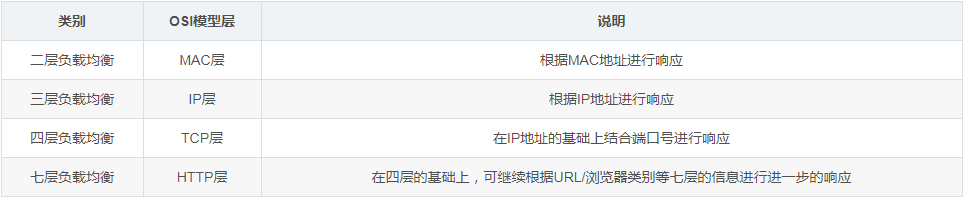
六、TCP负载均衡的执行原理
当Nginx从监听端口收到一个新的客户端链接时,立刻执行路由调度算法,获得指定需要连接的服务IP,然后创建一个新的上游连接,连接到指定服务器。

TCP负载均衡支持Nginx原有的调度算法,包括Round Robin(默认,轮询调度),哈希(选择一致)等。同时,调度信息数据也会和健壮性检测模块一起协作,为每个连接选择适当的目标上游服务器。如果使用Hash负载均衡的调度方法,你可以使用$remote_addr(客户端IP)来达成简单持久化会话(同一个客户端IP的连接,总是落到同一个服务server上)。
和其他upstream模块一样,TCP的stream模块也支持自定义负载均和的转发权重(配置“weight=2”),还有backup和down的参数,用于踢掉失效的上游服务器。max_conns参数可以限制一台服务器的TCP连接数量,根据服务器的容量来设置恰当的配置数值,尤其在高并发的场景下,可以达到过载保护的目的。
Nginx监控客户端连接和上游连接,一旦接收到数据,则Nginx会立刻读取并且推送到上游连接,不会做TCP连接内的数据检测。Nginx维护一份内存缓冲区,用于客户端和上游数据的写入。如果客户端或者服务端传输了量很大的数据,缓冲区会适当增加内存的大小。

当Nginx收到任意一方的关闭连接通知,或者TCP连接被闲置超过了proxy_timeout配置的时间,连接将会被关闭。对于TCP长连接,我们更应该选择适当的proxy_timeout的时间,同时,关注监听socke的so_keepalive参数,防止过早地断开连接。
PS:服务健壮性监控
TCP负载均衡模块支持内置健壮性检测,一台上游服务器如果拒绝TCP连接超过proxy_connect_timeout配置的时间,将会被认为已经失效。在这种情况下,Nginx立刻尝试连接upstream组内的另一台正常的服务器。连接失败信息将会记录到Nginx的错误日志中。
如果一台服务器,反复失败(超过了max_fails或者fail_timeout配置的参数),Nginx也会踢掉这台服务器。服务器被踢掉60秒后,Nginx会偶尔尝试重连它,检测它是否恢复正常。如果服务器恢复正常,Nginx将它加回到upstream组内,缓慢加大连接请求的比例。
之所“缓慢加大”,因为通常一个服务都有“热点数据”,也就是说,80%以上甚至更多的请求,实际都会被阻挡在“热点数据缓存”中,真正执行处理的请求只有很少的一部分。在机器刚刚启动的时候,“热点数据缓存”实际上还没有建立,这个时候爆发性地转发大量请求过来,很可能导致机器无法“承受”而再次挂掉。以mysql为例子,我们的mysql查询,通常95%以上都是落在了内存cache中,真正执行查询的并不多。
其实,无论是单台机器或者一个集群,在高并发请求场景下,重启或者切换,都存在这个风险,解决的途径主要是两种:
(1)请求逐步增加,从少到多,逐步积累热点数据,最终达到正常服务状态。
(2)提前准备好“常用”的数据,主动对服务做“预热”,预热完成之后,再开放服务器的访问。
TCP负载均衡原理上和LVS等是一致的,工作在更为底层,性能会高于原来HTTP负载均衡不少。但是,不会比LVS更为出色,LVS被置于内核模块,而Nginx工作在用户态,而且,Nginx相对比较重。另外一点,令人感到非常可惜,这个模块竟然是个付费功能。
TCP负载均衡模块支持内置健壮性检测,一台上游服务器如果拒绝TCP连接超过proxy_connect_timeout配置的时间,将会被认为已经失效。在这种情况下,Nginx立刻尝试连接upstream组内的另一台正常的服务器。连接失败信息将会记录到Nginx的错误日志中。

如果一台服务器,反复失败(超过了max_fails或者fail_timeout配置的参数),Nginx也会踢掉这台服务器。服务器被踢掉60秒后,Nginx会偶尔尝试重连它,检测它是否恢复正常。如果服务器恢复正常,Nginx将它加回到upstream组内,缓慢加大连接请求的比例。
之所“缓慢加大”,因为通常一个服务都有“热点数据”,也就是说,80%以上甚至更多的请求,实际都会被阻挡在“热点数据缓存”中,真正执行处理的请求只有很少的一部分。在机器刚刚启动的时候,“热点数据缓存”实际上还没有建立,这个时候爆发性地转发大量请求过来,很可能导致机器无法“承受”而再次挂掉。以mysql为例子,我们的mysql查询,通常95%以上都是落在了内存cache中,真正执行查询的并不多。
其实,无论是单台机器或者一个集群,在高并发请求场景下,重启或者切换,都存在这个风险,解决的途径主要是两种:
(1)请求逐步增加,从少到多,逐步积累热点数据,最终达到正常服务状态。
(2)提前准备好“常用”的数据,主动对服务做“预热”,预热完成之后,再开放服务器的访问。
TCP负载均衡原理上和LVS等是一致的,工作在更为底层,性能会高于原来HTTP负载均衡不少。但是,不会比LVS更为出色,LVS被置于内核模块,而Nginx工作在用户态,而且,Nginx相对比较重。另外一点,令人感到非常可惜,这个模块竟然是个付费功能。