数据库系统性能的提升不仅有赖于对数据库本身性能的优化,还需要对应用程序的性能进行优化。本文主要从应用程序方面进行介绍。
一个数据库系统的生命周期可以分成设计、开发和成品三个阶段。在设计阶段进行数据库性能优化的成本最低,收益最大。在成品阶段进行数据库性能优化的成本最高,收益最小。数据库的优化可以通过对网络、硬件、操作系统、数据库参数和应用程序的优化来进行。最常见的优化手段就是对硬件的升级。据统计,对网络、硬件、操作系统、数据库参数进行优化所获得的性能提升,全部加起来只占数据库系统性能提升的40%左右,其余的60%系统性能提升来自对应用程序的优化。许多优化专家认为,对应用程序的优化可以得到80%的系统性能的提升。
数据库性能的优化
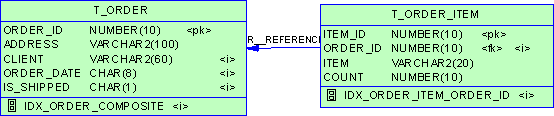
数据库设计是应用程序设计的基础,其性能直接影响应用程序的性能。数据库性能包括存储空间需求量的大小和查询响应时间的长短两个方面。为了优化数据库性能,需要对数据库中的表进行规范化。规范化的范式可分为第一范式、第二范式、第三范式、BCNF范式、第四范式和第五范式。一般来说,逻辑数据库设计会满足规范化的前3级标准,但由于满足第三范式的表结构容易维护且基本满足实际应用的要求。因此,实际应用中一般都按照第三范式的标准进行规范化。但是,规范化也有缺点:由于将一个表拆分成为多个表,在查询时需要多表连接,降低了查询速度。
由于规范化有可能导致查询速度慢的缺点,考虑到一些应用需要较快的响应速度,在设计表时应同时考虑对某些表进行反规范化。反规范化可以采用以下几种方法:
1. 分割表
分割表包括水平分割和垂直分割。
水平分割是按照行将一个表分割为多个表,这可以提高每个表的查询速度,但查询、更新时要选择不同的表,统计时要汇总多个表,因此应用程序会更复杂。
垂直分割是对于一个列很多的表,若某些列的访问频率远远高于其它列,就可以将主键和这些列作为一个表,将主键和其它列作为另外一个表。通过减少列的宽度,增加了每个数据页的行数,一次I/O就可以扫描更多的行,从而提高了访问每一个表的速度。但是由于造成了多表连接,所以应该在同时查询或更新不同分割表中的列的情况比较少的情况下使用。
2. 保留冗余列
当两个或多个表在查询中经常需要连接时,可以在其中一个表上增加若干冗余的列,以避免表之间的连接过于频繁。由于对冗余列的更新操作必须对多个表同步进行,所以一般在冗余列的数据不经常变动的情况下使用。
3. 增加派生列
派生列是由表中的其它多个列计算所得,增加派生列可以减少统计运算,在数据汇总时可以大大缩短运算时间。
应用程序性能的优化
应用程序的优化通常可分为两个方面:源代码和SQL语句。由于涉及到对程序逻辑的改变,源代码的优化在时间成本和风险上代价很高,而对数据库系统性能的提升收效有限,因此应用程序的优化应着重在SQL语句的优化。对于海量数据,劣质SQL语句和优质SQL语句之间的速度差别可以达到上百倍,可见对于一个系统不是简单地能实现其功能就行,而是要写出高质量的SQL语句,提高系统的可用性。
下面就某些SQL语句的where子句编写中需要注意的问题作详细介绍。在这些where子句中,即使某些列存在索引,但是由于编写了劣质的SQL,系统在运行该SQL语句时也不能使用该索引,而同样使用全表扫描,这就造成了响应速度的极大降低。
1. IS NULL 与 IS NOT NULL
不能用null作索引,任何包含null值的列都将不会被包含在索引中。即使索引有多列的情况下,只要这些列中有一列含有null,该列就会从索引中排除。也就是说如果某列存在空值,即使对该列建索引也不会提高性能。
任何在where子句中使用is null或is not null的语句优化器是不允许使用索引的。
2. 联接列
对于有联接的列,即使最后的联接值为一个静态值,优化器不会使用索引的。例如,假定有一个职工表(employee),对于一个职工的姓和名分成两列存放(FIRST_NAME和LAST_NAME),现在要查询一个叫乔治・布什(George Bush)的职工。 下面是一个采用联接查询的SQL语句:
|
上面这条语句完全可以查询出是否有George Bush这个员工,但是这里需要注意,系统优化器对基于last_name创建的索引没有使用。
当采用下面这种SQL语句的编写,Oracle系统就可以采用基于last_name创建的索引:
|
遇到下面这种情况又如何处理呢?如果一个变量(name)中存放着George Bush这个员工的姓名,对于这种情况我们又如何避免全程遍历使用索引呢?可以使用一个函数,将变量name中的姓和名分开就可以了,但是有一点需要注意,这个函数是不能作用在索引列上。下面是SQL查询脚本:
|
3. 带通配符(%)的like语句
同样以上面的例子来看这种情况。目前的需求是这样的,要求在职工表中查询名字中包含Bush的人。可以采用如下的查询SQL语句:
|
这里由于通配符(%)在搜寻词首出现,所以Oracle系统不使用last_name的索引。在很多情况下可能无法避免这种情况,但是一定要心中有底,通配符如此使用会降低查询速度。然而当通配符出现在字符串其他位置时,优化器就能利用索引。例如,在下面的查询中索引得到了使用:
|
新闻热点






疑难解答