在MySQL中,我们通常都使用limit来完成数据集获取的分页操作,而在Oracle数据库中,并没有类似limit一样的方便方法来实现分页,因此我们通常都是直接在SQL语句中完成分页,这里就需要借助于rownum伪列或row_number()函数了,本文将分别展示使用rownum伪列和row_number()分析函数来完成Oracle数据分页操作的具体使用方法,并分析和比较两者的性能优劣。
一、初始化测试数据
首先测试数据我选取了数据字典all_objects表中的70000条数据,创建步骤如下:
-- 为了方便验证结果集以及避免不必要的排序,这里我直接使用了rownum来产生了有序的OBJECT_ID列
SQL> create table my_objects as
2 select rownum as OBJECT_ID,OBJECT_NAME,OBJECT_TYPE
3 from all_objects where rownum < 70001;
Table created.
-- 对OJBECT_ID列建立主键
SQL> alter table my_objects add primary key (object_id);
Table altered.
SQL> select count(*) from my_objects;
COUNT(*)
----------
70000
-- 分析该表
SQL> exec dbms_stats.gather_table_stats(user,'my_objects',cascade => TRUE);
PL/SQL procedure successfully completed.
二、分页数据获取
为了完成分页,我们需要获得该表中的第59991-60000条的10条记录,这个工作我们分别使用rownum和rown_number()来实现
-- 方法一,rownum伪列方式
SQL> select t.* from (select d.*,rownum num from my_objects d where rownum<=60000) t where t.num>=59991;
OBJECT_ID OBJECT_NAME OBJECT_TYPE NUM
---------- ------------------------------ ------------------- ----------
59991 /585bb929_DicomRepos24 JAVA CLASS 59991
59992 /13a1874f_DicomRepos25 JAVA CLASS 59992
59993 /2322ccf0_DicomRepos26 JAVA CLASS 59993
59994 /6c82abc6_DicomRepos27 JAVA CLASS 59994
59995 /34be1a57_DicomRepos28 JAVA CLASS 59995
59996 /b7ee0c7f_DicomRepos29 JAVA CLASS 59996
59997 /bb1d935c_DicomRepos30 JAVA CLASS 59997
59998 /deb95b4f_DicomRepos31 JAVA CLASS 59998
59999 /9b5f55c0_DicomRepos32 JAVA CLASS 59999
60000 /572f1657_DicomRepos33 JAVA CLASS 60000
10 rows selected.
-- 方法二,row_number分析函数方式
SQL> select * from
2 (select t.*,row_number() over (order by t.OBJECT_ID) as num
3 from my_objects t)
4 where num between 59991 and 60000;
OBJECT_ID OBJECT_NAME OBJECT_TYPE NUM
---------- ------------------------------ ------------------- ----------
59991 /585bb929_DicomRepos24 JAVA CLASS 59991
59992 /13a1874f_DicomRepos25 JAVA CLASS 59992
59993 /2322ccf0_DicomRepos26 JAVA CLASS 59993
59994 /6c82abc6_DicomRepos27 JAVA CLASS 59994
59995 /34be1a57_DicomRepos28 JAVA CLASS 59995
59996 /b7ee0c7f_DicomRepos29 JAVA CLASS 59996
59997 /bb1d935c_DicomRepos30 JAVA CLASS 59997
59998 /deb95b4f_DicomRepos31 JAVA CLASS 59998
59999 /9b5f55c0_DicomRepos32 JAVA CLASS 59999
60000 /572f1657_DicomRepos33 JAVA CLASS 60000
10 rows selected.
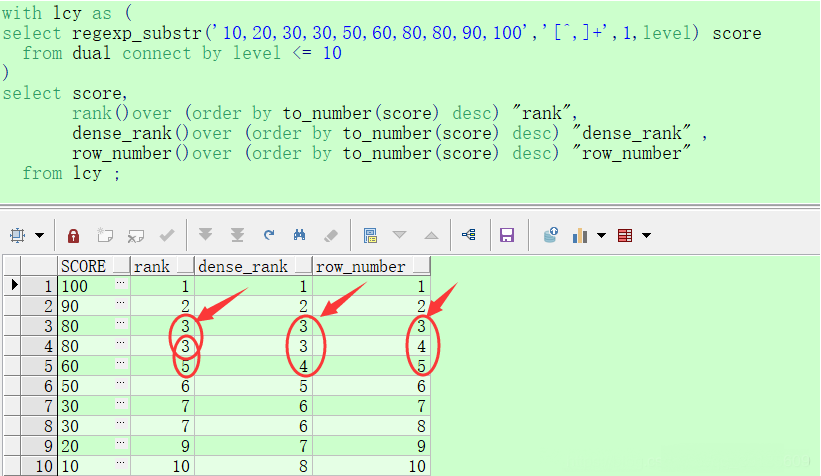
可以看到这两种方式都返回了正确的结果集;在rownum方法中,由于不可以直接使用rownum伪列执行”大于“比较运算,所以这里是先从子查询中使用rownum来获得前60000条数据,然后在外层查询中使用大于运算去除不需要的行。而对于row_number()方法,row_number()分析函数以OBJECT_ID排序并为其生成了唯一的标识,然后通过between这种便于理解的方式来获取区间数据,那么实际的执行是不是这样的呢?我们来简单分析一下两者的执行细节。
三、分页性能分析
首先还是看一下他们的执行计划:
SQL> set autotrace traceonly
SQL> set linesize 200
-- rownum伪列分页的执行计划
SQL> select t.* from (select d.*,rownum num from my_objects d where rownum<=60000) t where t.num>=59991;
10 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 341064162
----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 60000 | 3164K| 103 (0)| 00:00:02 |
|* 1 | VIEW | | 60000 | 3164K| 103 (0)| 00:00:02 |
|* 2 | COUNT STOPKEY | | | | | |
| 3 | TABLE ACCESS FULL| MY_OBJECTS | 60000 | 2226K| 103 (0)| 00:00:02 |
----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("T"."NUM">=59991)
2 - filter(ROWNUM<=60000)
Statistics
----------------------------------------------------------
163 recursive calls
0 db block gets
399 consistent gets
0 physical reads
0 redo size
1030 bytes sent via SQL*Net to client
419 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
5 sorts (memory)
0 sorts (disk)
10 rows processed
-- row_number()分页的执行计划
SQL> select * from
2 (select t.*,row_number() over (order by t.OBJECT_ID) as num
3 from my_objects t)
4 where num between 59991 and 60000;
10 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 2942654422
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 70000 | 3691K| 565 (1)| 00:00:07 |
|* 1 | VIEW | | 70000 | 3691K| 565 (1)| 00:00:07 |
|* 2 | WINDOW NOSORT STOPKEY | | 70000 | 2597K| 565 (1)| 00:00:07 |
| 3 | TABLE ACCESS BY INDEX ROWID| MY_OBJECTS | 70000 | 2597K| 565 (1)| 00:00:07 |
| 4 | INDEX FULL SCAN | SYS_C0011057 | 70000 | | 146 (0)| 00:00:02 |
----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("NUM">=59991 AND "NUM"<=60000)
2 - filter(ROW_NUMBER() OVER ( ORDER BY "T"."OBJECT_ID")<=60000)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
490 consistent gets
0 physical reads
0 redo size
1030 bytes sent via SQL*Net to client
419 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
10 rows processed
从上面的执行计划中我们可以看出,rownum方法使用了全表扫描来获得表中的前60000行,然后使用谓词条件”T”.”NUM”>=59991来过滤掉了不需要的行;而row_number()方法虽然利用到了主键索引来省去了分析函数本身产生的window的排序操作,但它还是先获取了表中的所有70000行数据,然后再使用between关键字来过滤数据行,这个操作的很多资源都消耗在了数据读取上了,所以上面的例子中,rownum伪列方法获得了较好的性能,而实际上,在大多数情况下,第一种rownum方法都会获得较好的性能。
可能有人会疑问,既然row_number()方法在数据读取上面花费了这么多的资源,为什么不直接让它全表扫描呢,那么我们来看看使用全表扫描的情形:
-- 直接禁用主键
SQL> alter table my_objects disable primary key;
Table altered.
SQL> select * from
2 (select t.*,row_number() over (order by t.OBJECT_ID) as num
3 from my_objects t)
4 where num between 59991 and 60000;
10 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 2855691782
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 70000 | 3691K| | 812 (1)| 00:00:10 |
|* 1 | VIEW | | 70000 | 3691K| | 812 (1)| 00:00:10 |
|* 2 | WINDOW SORT PUSHED RANK| | 70000 | 2597K| 3304K| 812 (1)| 00:00:10 |
| 3 | TABLE ACCESS FULL | MY_OBJECTS | 70000 | 2597K| | 120 (1)| 00:00:02 |
-----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("NUM">=59991 AND "NUM"<=60000)
2 - filter(ROW_NUMBER() OVER ( ORDER BY "T"."OBJECT_ID")<=60000)
Statistics
----------------------------------------------------------
190 recursive calls
0 db block gets
450 consistent gets
0 physical reads
0 redo size
1030 bytes sent via SQL*Net to client
419 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
6 sorts (memory)
0 sorts (disk)
10 rows processed
可以看到这种全表扫描的情形发生WINDOW SORT PUSHED RANK方法,也就是说这会cpu资源又花在了对object_id的排序上了,尽管在本例中object_id已经有序了,性能上同样不及rownum方式。
所以在写程序的过程中,对于Oracle的分页操作我还是倾向于使用如下的rownum的方式来完成,通常的写法如下:
-- 返回第20页数据,每页10行
SQL> define pagenum=20
SQL> define pagerecord=10
SQL> select t.* from (select d.*,rownum num from my_objects d
2 where rownum<=&pagerecord*&pagenum) t
3 where t.num>=(&pagenum-1)*&pagerecord +1;
old 2: where rownum<=&pagerecord*&pagenum) t
new 2: where rownum<=10*20) t
old 3: where t.num>=(&pagenum-1)*&pagerecord +1
new 3: where t.num>=(20-1)*10 +1
OBJECT_ID OBJECT_NAME OBJECT_TYPE NUM
---------- ------------------------------ ------------------- ----------
191 SQLOBJ$DATA_PKEY INDEX 191
192 SQLOBJ$AUXDATA TABLE 192
193 I_SQLOBJ$AUXDATA_PKEY INDEX 193
194 I_SQLOBJ$AUXDATA_TASK INDEX 194
195 OBJECT_USAGE TABLE 195
196 I_STATS_OBJ# INDEX 196
197 PROCEDURE$ TABLE 197
198 PROCEDUREINFO$ TABLE 198
199 ARGUMENT$ TABLE 199
200 SOURCE$ TABLE 200
10 rows selected.
备注:
在写程序的时候为了便于理解,也会有人在rownum方法中使用between来限定数据行,写法如下:
select t.* from (select rownum num, d.* from my_objects d) t where t.num between 59991 and 60000;
在他们看来,这样写返回的数据行和第一种rownum方法是一致的,Oracle会推进谓词between部分到子查询内部,同样也不影响性能,而这种想法是完全错误的,我们来看一下它的具体执行计划:
SQL> select t.* from (select rownum num, d.* from my_objects d) t where t.num between 59991 and 60000;
10 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 1665864874
----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 70000 | 3691K| 120 (1)| 00:00:02 |
|* 1 | VIEW | | 70000 | 3691K| 120 (1)| 00:00:02 |
| 2 | COUNT | | | | | |
| 3 | TABLE ACCESS FULL| MY_OBJECTS | 70000 | 2597K| 120 (1)| 00:00:02 |
----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("T"."NUM"<=60000 AND "T"."NUM">=59991)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
423 consistent gets
0 physical reads
0 redo size
1030 bytes sent via SQL*Net to client
419 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
10 rows processed
可以非常醒目的看到这个查询先发生了70000行的全表扫描,并非预想的60000行,原因还是rownum,在子查询中使用rownum直接禁用了查询转换阶段的谓语前推功能,所以上面的查询只能先获得所有的数据再应用between来过滤了。可以参考我的这篇【CBO-查询转换探究】。
说了这么多,其实也就是Oracle的分页的三条SQL语句,对于数据量非常大的分页问题,单纯这样做是不会获得高效的,因此还需要借助于一些其他技术,比如反范式化设计,预先计算或者在应用层建立适当的缓存机制。