函数名 | 函数功能 |
ASCII | 返回与指定的字符对应的十进制数 select ascii(ename) ,job from emp; |
CHR | 参数为整数,表示某个字符的Unicode码,返回对应的字符 |
|
|
CONCAT | 连接两个字符串 select concat(ename,'---') name from emp; select concat(concat(ename,'--'),job) name from emp; 连接字符串也可以使用|| |
|
|
LOWER | 返回字符串,并将所有的字符小写 select lower(ename) ename ,job from emp; |
UPPER | 返回字符串,并将所有的字符大写 select upper(lower(ename)) ename ,job from emp |
INITCAP | 返回字符串并将字符串的第一个字母变为大写 select INITCAP('sdaf dsfasd') from emp; |
|
|
INSTR | 在一个字符串中搜索指定的字符,返回发现指定的字符的位置 select instr('aab','aa') from dual; select * from emp where instr(ename,'A')!=0; select instr(‘Oracle training’,’ra’,1,2) instring from dual;
|
LENGTH | 返回字符串的长度 select * from emp where length(ename)>5 |
|
|
RPAD | 在列的右边粘贴字符 select rpad(ename,10,'*') ename from emp; |
LPAD | 在列的左边粘贴字符 |
|
|
|
|
SUBSTR | 取子字符串 select substr('abcdefg' ,2,5) from dual; 取身份证的生日; |
REPLACE | 将一个字符串中的子字符串替换成其他的字符串 select replace('abc','ab') from dual; select replace('abc','ab') from dual;
|
TRIM | 删除字符串两边的字符串,如删除字符串两边的空格,删除字符串两边的#字符 select trim(' sd sdf ') from dual; 应用 登陆 select * from emp where ename=trim(' SCOTT '); select trim(' ' from ' sdfdf ds ') from dual; select trim('a' from 'aasdfaaadf dsaaa') from dual 删除123Tech111两端的1字符 SQL>select trim (both ‘1’ from ‘123tech111’) from dual;
SQL> select trim(leading ‘0’ from ‘000123’) from dual;
删除Tech1尾部的1字符 SQL>select trim(trailing ‘1’ from ‘Tech1’) from dual;
|
LTRIM 删除左边出现的字符串
RTRIM 删除右边出现的字符串
|
|
示例3.3:
SQL> SELECT CONCAT(‘010-’,’88888888’) || ‘转23’ 电话号码 from dual;
连接010、88888888、转23这3个字符串
字符串连接可以有两种方法,一是使用CONCAT函数,二是使用||字符串连接符。
美国人的名字中每个单词的首字母必须大写显示,这是英语的习惯。下面要显示迈克尔杰克逊人名,需要将每个单词首字符大写
示例3.4:
SQL> select initcap(‘michael jackson’) as name from dual;
有些时候,我们可能需要在一长串字符中找某个字符串,并且有可能需要找到第几次出现的位置,这时可以使用instr函数。
在oracle traning字符串中找ra字符,从第一个字符开始,查找第二次出现的位置示例3.5:
SQL> select instr(‘oracle training’,’ra’,1,2) instring from dual;
INSTR一共有4个参数,第一个是被查找的字符串,第二个是要查找的字符串,我们要查找ra字符串,第三个参数是一个数字,表示从哪个位置开始找,此参数可选,如果省略默认为1。第四个参数表示要查找第几次出现的ra,此参数可选,如果省略默认为1。
在英语信息中,有时我们可能需要可能首字符大写、全大写和全小写的形式向客户展示我们的信息,这时我们可以使用initcap,upper,lower函数。
示例3.6:
SQL> select initcap(ename), upper(ename), lower(ename) from emp;
上面的例子分别以首字符大写、全大写和全小写的形式显示emp表中的姓名(ename)字段
电子商务中,我们有时需要在源字符串的基础上在其前后增加若干个特殊字符,已达到某一个固定的长度。这时可以使用lpad,rpad函数
示例3.7:
SQL> select lpad(rpad(‘gao’,10,’#’),17,’*’) from dual;
上面的示例将gao字符串右边增加若干个#使总长度达到10,然后再左边增加若干个*,使总长度达到17
RPAD 是在列的右边粘贴字符包括有3个参数,第一个是原字符串gao,第二个参数是增加后达到10个字符,第三个参数表示要加#字符。
示例3.8:
SQL> select ltrim(rtrim(‘’****gao qian jing ,’ ’),’*’) from dual;
上面的示例删除了”****gao qian jing “字符串左边的*,再删除右边的空格
取字符串的子串在实际的业务中用的非常多,如取身份证的某几位得到某人的出生年月日,再如获得一个移动电话的后8位等等。
示例3.9:
SQL> select substr(‘13088888888’,3,8) from dual;
上面的示例从13088888888中取子字符串,从3开始,取8个
将字符串中的子串替换成新的值在业务中也有使用,比如我们将信息中的一些不雅的词语替换成****,这时我们可以使用replace函数
示例3.10:
SQL> select replace(‘he love you’,’he’,’I’) from dual;
上面的示例替换he love you字符串中的he为i
用户输入时用户名或密码时有可能输入空格,我们可以使用trim删除两端的空格
示例3.11:
SQL> select trim(‘ tech ‘) from dual;
trim('字符1' from '字符串2') 分别从字符2串的两边开始,删除指定的字符1
SQL>select trim(‘ ‘ from ‘ tech ‘) from dual;
删除000123头部的0字符
SQL> select trim(leading ‘0’ from ‘000123’) from dual;
删除Tech1尾部的1字符
SQL>select trim(trailing ‘1’ from ‘Tech1’) from dual;
删除123Tech111两端的1字符
SQL>select trim (both ‘1’ from ‘123tech111’) from dual;
注意:leading表示从字符串的头开始删除。Trailing表示从字符串的尾部开始删除。Borth表示从字符串的两边删除。
当然也可以简化成
select ltrim('****gao qian jing------','*') from dual
函数名 | 函数功能 |
ABS | 返回指定值的绝对值 |
CEIL | 返回大于或等于给出数字的最小整数 |
FLOOR | 对给定的数字取整数 |
MOD(n1,n2) | 返回一个n1除以n2的余数 |
POWER(n1,n2) | 返回n1的n2次方 |
SIGN | 取数字n的符号,大于0返回1,小于0返回-1,等于0返回0 |
SQRT | 返回数字的根 |
ROUND | 按照指定的精度四舍五入 |
TRUNC | 按照指定的精度截取一个数 |
天花板函数示例3.12:
SQL> select ceil(3.1415927) from dual;
地板函数 示例3.13:
select floor(2345.67) from dual;
示例3.14:
SQL> select round(124.1666,-2) , round(124.1666,2) from dual;
SQL> select trunc(124.1666,-2) , trunc(124.16666,2) from dual;
注意:Round函数进行四舍五入,trunc函数进行截取。第二个参数为正时,表示从小数位计算。第二个参数为负时,表示从整数位计算。
日期函数以DATE类型为参数。除了MONTHS_BETWEEN函数,它返回NUMBER类型,它返回DATE或日期时间类型。日期函数常用的格式模型如表3-1-1所示
表3-1-3 格式模型
模板 | 描述 |
HH | 一天的小时数 (01-12) |
HH12 | 一天的小时数 (01-12) |
HH24 | 一天的小时数 (00-23) |
MI | 分钟 (00-59) |
SS | 秒 (00-59) |
MS | 毫秒 (000-999) |
US | 微秒 (000000-999999) |
SSSS | 午夜后的秒 (0-86399) |
AM 或 A.M. 或 PM 或 P.M. | 正午标识(大写) |
am 或 a.m. 或 pm 或 p.m. | 正午标识(小写) |
Y,YYY | 带逗号的年(4 和更多位) |
YYYY | 年(4和更多位) |
YYY | 年的后三位 |
YY | 年的后两位 |
Y | 年的最后一位 |
BC 或 B.C. 或 AD 或 A.D. | 年标识(大写) |
bc 或 b.c. 或 ad 或 a.d. | 年标识(小写) |
MONTH | 全长大写月份名(9字符) 英文的月份 或者4月 |
Month | 全长混合大小写月份名(9字符) |
month | 全长小写月份名(9字符) |
MON | 大写缩写月份名(3字符) |
Mon | 缩写混合大小写月份名(3字符) |
mon | 小写缩写月份名(3字符) |
MM | 月份 (01-12) |
DAY | 全长大写日期名(9字符) |
Day | 全长混合大小写日期名(9字符) |
day | 全长小写日期名(9字符) |
DY | 缩写大写日期名(3字符) |
Dy | 缩写混合大小写日期名(3字符) |
dy | 缩写小写日期名(3字符) |
DDD | 一年里的日子(001-366) |
DD | 一个月里的日子(01-31) |
D | 一周里的日子(1-7;SUN=1) |
W | 一个月里的周数(1-5),这里第一周从该月第一天开始 |
WW | 一年里的周数(1-53),这里的第一周从该年的第一天开始 |
Q | 季度 |
表3-1-4 日期函数
函数名 | 函数功能 |
SYSDATE | 用来得到系统的当前日期 插入当前时间 使用默认格式字符串直接插入 Todate 日期的格式 Tochar |
ADD_MONTHS | 增加或减去月份 |
trunc(date,fmt)按照给出的要求将日期截断,如果fmt='mi'表示保留分,截断秒
|
|
LAST_DAY | 返回日期的最后一天 |
MONTHS_BETWEEN(date2,date1)
| 给出date2和date1相差的月份 |
NEXT_DAY(date,'day') | 给出日期date和星期x之后计算下一个星期的日期
|
示例3.15:
SQL> select sysdate, to_char(sysdate,’dd-mm-yyyy day’) from dual;
有时我们想按照自己的格式显示今天几号星期几,可以采用以上写法
trunc(date,fmt)按照给出的要求将日期截断,如果fmt='mi'表示保留分,截断秒
想得到某个日期前后若干月是哪一天,可以使用ADD_MONTHS函数增加或减去月份
示例3.16:
SQL> select to_char(add_months(to_date('1999-12','yyyy-mm'),2),'yyyy-mm') from dual;
在人员管理系统中,我们可能需要得到某两个日期相差多少个月,或某日期和今天相差月份,可以使用MONTHS_BETWEEN函数
示例3.17:
SQL> select months_between('9-12月-1999','19-3月-1999') mon_between from dual;
转换函数是将PL/SQL数据由一种数据类型转到另一种数据类型,例如to_date to_char tonumber
PL/SQL将会通过对转换函数的隐式调用进行自动转换。但是,隐式调用转换函数时无法对使用的格式指定符进行控制,这时我们最好使用显式调用转换函数。
SQL> select * from test;
AGE
----------
1
SQL> select * from test where age='1';
表3-1-5 转换函数
函数 | 返回 | 描述 | 例子 |
to_char(timestamp, text) | text | 把 timestamp 转换成 string | to_char(timestamp 'now','HH12:MI:SS') |
to_char(int, text) | text | 把 int4/int8 转换成 string | to_char(125, '999') |
to_char(double PRecision, text) | text | 把 real/double precision 转换成 string | to_char(125.8, '999D9') |
to_char(numeric, text) | text | 把 numeric 转换成 string | to_char(numeric '-125.8', '999D99S') |
to_date(text, text) | date | 把 string 转换成 date | to_date('05 Dec 2000', 'DD Mon YYYY') |
to_timestamp(text, text) | date | 把 string 转换成 timestamp | to_timestamp('05 Dec 2000', 'DD Mon YYYY') |
to_number(text, text) | numeric | 把 string 转换成 numeric | to_number('12,454.8-', '99G999D9S') |
将今天按照某种特殊的格式显示,可以使用to_char
示例18:
SQL> select to_char(sysdate,'yyyy/mm/dd hh24:mi:ss') from dual;
表3-1-6 to_date函数格式模板
模板 | 描述 |
HH | 一天的小时数 (01-12) |
HH12 | 一天的小时数 (01-12) |
HH24 | 一天的小时数 (00-23) |
MI | 分钟 (00-59) |
SS | 秒 (00-59) |
MS | 毫秒 (000-999) |
US | 微秒 (000000-999999) |
SSSS | 午夜后的秒 (0-86399) |
AM 或 A.M. 或 PM 或 P.M. | 正午标识(大写) |
am 或 a.m. 或 pm 或 p.m. | 正午标识(小写) |
Y,YYY | 带逗号的年(4 和更多位) |
YYYY | 年(4和更多位) |
YYY | 年的后三位 |
YY | 年的后两位 |
Y | 年的最后一位 |
BC 或 B.C. 或 AD 或 A.D. | 年标识(大写) |
bc 或 b.c. 或 ad 或 a.d. | 年标识(小写) |
MONTH | 全长大写月份名(9字符) |
Month | 全长混合大小写月份名(9字符) |
month | 全长小写月份名(9字符) |
MON | 大写缩写月份名(3字符) |
Mon | 缩写混合大小写月份名(3字符) |
mon | 小写缩写月份名(3字符) |
MM | 月份 (01-12) |
DAY | 全长大写日期名(9字符) |
Day | 全长混合大小写日期名(9字符) |
day | 全长小写日期名(9字符) |
DY | 缩写大写日期名(3字符) |
Dy | 缩写混合大小写日期名(3字符) |
dy | 缩写小写日期名(3字符) |
DDD | 一年里的日子(001-366) |
DD | 一个月里的日子(01-31) |
D | 一周里的日子(1-7;SUN=1) |
W | 一个月里的周数(1-5),这里第一周从该月第一天开始 |
WW | 一年里的周数(1-53),这里的第一周从该年的第一天开始 |
IW | ISO 一年里的周数(第一个星期四在第一周里) |
CC | 世纪(2 位) |
J | Julian 日期(自公元前4712年1月1日来的日期) |
Q | 季度 |
RM | 罗马数字的月份(I-XII;I=JAN)-大写 |
rm | 罗马数字的月份(I-XII;I=JAN)-小写 |
TZ | 时区字串 - 大写 |
tz | 时区字串 - 小写 |
示例19:
SQL> select * from emp where hiredate> to_date(‘1990-12-2’,’yyyy-mm-dd’);
SQL> select to_date(‘3月 7,1999’,’Month DD,yyyy) from dual;
SQL>select to_char(hiredate,’yyyy-MM-dd day’) from emp where rownum<10;
将字符串转化为ORACLE中的一个日期
保存到数据库中的数据可能是字符串,但是我们可以将其转换为数字再参与数学运算,这时使用to_number函数。如年份可能保存成字符,计算1999年后是哪一年
示例20:
SQL> select to_number(‘1999’) + 10 year from dual;
其他函数
函数名 | 函数功能 |
UID | 返回标识当前用户的唯一整数
|
USER | 返回当前用户的名字
|
NVL(expr1, expr2) | NVL(expr1, expr2)表示如果expr1为NULL,返回expr2;不为NULL,返回expr1。注意expr1和expr2两者的类型要一致 |
NVL2 (expr1, expr2, expr3) | expr1不为NULL,返回expr2;为NULL,返回expr3。expr2和expr3类型不同的话,expr3会转换为expr2的类型 |
NULLIF (expr1, expr2) | expr1和expr2相等返回NULL,不等返回expr1
|
用户登录成功后,我们可能要记录当前登录用户的姓名和id,这时我们要使用UID,USER函数
示例20:
SQL> select uid from dual;
SQL> select username,user_id from user_users where user_id = uid;
显示当前用户编号,当然我们可以把这个编号存入自己定义的日志表中。
在数据库中,经常出现某个字段值为空。这时,我们希望字段值为空时,显示某个值,否则显示自身。例如奖金字段(comm)的值为null,返回0,不为null显示comm.
示例21:
SQL>select empno,ename,hiredate,sal,nvl(comm,0) ,sal+nvl(comm,0) from emp;
除了nvl外,还可以使用nvl2函数。Nvl2有3个参数,如果参数1不为NULL, 返回第二个参数;为NULL,返回第三个参数。
示例22:
SQL> SELECT COMM,NVL2(COMM,COMM,0) FROM EMP;
奖金字段COMM不为NULL,返回COMM;为NULL,返回0。
聚合函数将多条记录聚合成一条记录。聚合函数有AVG,MAX,MIN,COUNT,SUM
示例23:创建示例表和示例数据
SQL> create table test(xm varchar(8),sal number(7,2));
语句已处理。
SQL> insert into table3 values(‘gao’,1111.11);
SQL> insert into table3 values(‘gao’,1111.11);
SQL> insert into table3 values(‘zhu’,5555.55);
SQL> commit;
得到不同的sal的平均值,如果出现相同的sal值,如1111.11出现两次,只算一次。
SQL> select avg(distinct sal) from test;
得到所有的sal的平均值,如果出现相同的sal值,如1111.11出现两次,算两次。
SQL> select avg(all sal) from gao.test;
意:如果什么都不写,默认是all
3.8 Oracle分析函数Oracle从8.1.6开始提供分析函数,分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是对于每个组返回多行,而聚合函数对于每个组只返回一行。 常用的分析函数如下所列: row_number() over (partition by ... order by ...) rank() over (partition by ... order by ...) dense_rank() over (partition by ... order by ...)
count() over (partition by ... order by ...) max() over (partition by ... order by ...) min() over (partition by ... order by ...) sum() over (partition by ... order by ...) avg() over (partition by ... order by ...)
OVER子句前面必须是排名函数或者是聚合函数。
注意:下面例子中使用的表来自Oracle自带的HR用户下的表,如果没有安装该用户,可以在SYS用户下运行 $ORACLE_HOME/demo/schema/human_resources/hr_main.sql来创建。
开窗函数的的理解: 开窗函数指定了分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化
举例如下: over(order by salary) 按照salary排序进行累计,order by是个默认的开窗函数 over(partition by deptno)按照部门分区 over(order by salary range between 50 preceding and 150 following) 每行对应的数据窗口是之前行幅度值不超过50,之后行幅度值不超过150 over(order by salary rows between 50 preceding and 150 following) 每行对应的数据窗口是之前50行,之后150行 over(order by salary rows between unbounded preceding and unbounded following) 每行对应的数据窗口是从第一行到最后一行
等效: over(order by salary range between unbounded preceding and unbounded following) 先查询 后开窗 然后再统计
示例3.24:
下面的例子中列c_mavg计算员工表中每个员工的平均薪水报告,按照manager_id分组
SQL>select manager_id, last_name, hire_date, salary,
Avg(salary) over (partition by manager_id) as c_mavg from employees;
示例3.25:下面的例子中列c_mavg计算员工表中每个员工的平均薪水报告,该平均值由当前员工和与之具有相同经理的前一个和后一个三者的平均数得来;
SQL>SELECT manager_id, last_name, hire_date, salary,
AVG(salary) OVER (PARTITION BY manager_id order by hire_date rows BETWEEN 1 PRECEDING and 3 FOLLOWING ) AS c_mavg
FROM employees;
示例3.27:下面例子中dept_max返回当前行所在部门的最大薪水值 SQL>SELECT department_id, last_name, salary, MAX(salary) OVER (PARTITION BY department_id) AS dept_max
FROM employees WHERE department_id in (10,20,30);
实例3.28:下面例子中dept_min返回当前行所在部门的最小薪水值 SQL>SELECT department_id, last_name, salary, MIN(salary) OVER (PARTITION BY department_id) AS dept_min FROM employees WHERE department_id in (10,20,30);
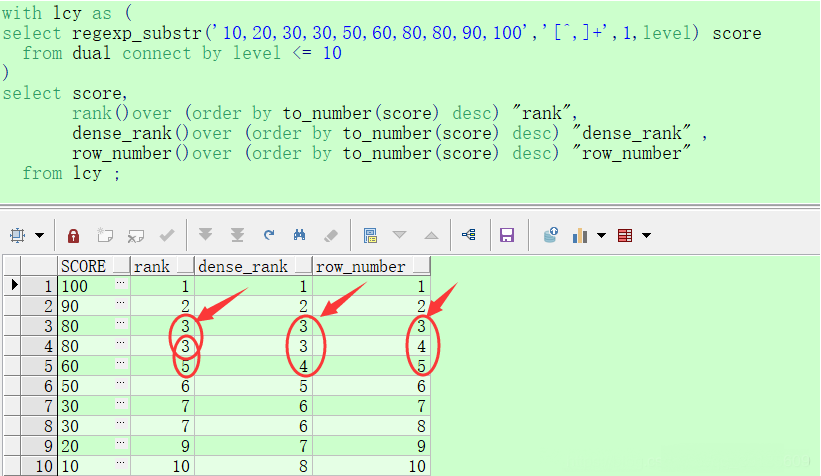
示例3.29 . DENSE_RANK 功能描述:根据ORDER BY子句中表达式的值,从查询返回的每一行,计算它们与其它行的相对位置。组内的数据按ORDER BY子句排序,然后给每一行赋一个号,从而形成一个序列,该序列从1开始,往后累加。每次ORDER BY表达式的值发生变化时,该序列也随之增加。有同样值的行得到同样的数字序号(认为null时相等的)。密集的序列返回的时没有间隔的数
下例中计算每个员工按部门分区再按薪水排序,依次出现的序列号(注意与RANK函数的区别)
SQL>SELECT d.department_id , e.last_name, e.salary, DENSE_RANK() OVER (PARTITION BY e.department_id ORDER BY e.salary) as drank FROM employees e, departments d WHERE e.department_id = d.department_id AND d.department_id IN ('60', '90');
示例3.30 RANK 功能描述:根据ORDER BY子句中表达式的值,从查询返回的每一行,计算它们与其它行的相对位置。组内的数据按ORDER BY子句排序, 然后给每一行赋一个号,从而形成一个序列,该序列从1开始,往后累加。每次ORDER BY表达式的值发生变化时,该序列也随之增加。 有同样值的行得到同样的数字序号(认为null时相等的)。然而,如果两行的确得到同样的排序,则序数将随后跳跃。若两行序数为1, 则没有序数2,序列将给组中的下一行分配值3,DENSE_RANK则没有任何跳跃。
下例中计算每个员工按部门分区再按薪水排序,依次出现的序列号(注意与DENSE_RANK函数的区别) SQL>SELECT d.department_id , e.last_name, e.salary, RANK() OVER (PARTITION BY e.department_id ORDER BY e.salary) as drank FROM employees e, departments d WHERE e.department_id = d.department_id AND d.department_id IN ('60', '90');
示例3.31 ROW_NUMBER 功能描述:返回有序组中一行的偏移量,从而可用于按特定标准排序的行号。
下例返回每个员工再在每个部门中按员工号排序后的顺序号 SQL>SELECT department_id, last_name, employee_id, ROW_NUMBER() OVER (PARTITION BY department_id ORDER BY employee_id) AS emp_id FROM employees WHERE department_id < 50;
示例3.32. SUM 功能描述:该函数计算组中表达式的累积和。
下例计算同一经理下员工的薪水累积值 SQL>SELECT manager_id, last_name, salary, SUM (salary) OVER (PARTITION BY manager_id ORDER BY salary RANGE UNBOUNDED PRECEDING) l_csum FROM employees WHERE manager_id in (101,103,108);
count分析函数对一组内发生的事情进行累积计数,如果指定*或一些非空常数,count将对所有行计数,如果指定一个表达式,count返回表达式非空赋值的计数,当有相同值出现时,这些相等的值都会被纳入被计算的值;可以使用DISTINCT来记录去掉一组中完全 相同的数据后出现的行数。
示例3.26:下面例子中计算每个员工在按薪水排序中当前行附近薪水在[n-50,n+150]之间的行数,n表示当前行的薪水 例如,Philtanker的薪水2200,排在他之前的行中薪水大于等于2200-50的有1行,排在他之后的行中薪水小于等于2200+150的行 没有,所以count计数值cnt3为2(包括自己当前行);cnt2值相当于小于等于当前行的SALARY值的所有行数
SQL>SELECT last_name, salary, COUNT(*) OVER () AS cnt1, COUNT(*) OVER (ORDER BY salary) AS cnt2, COUNT(*) OVER (ORDER BY salary RANGE BETWEEN 50 PRECEDING AND 150 FOLLOWING) AS cnt3 FROM employees;
示例3.33: RATIO_TO_REPORT 功能描述:该函数计算expression/(sum(expression))的值,它给出相对于总数的百分比,即当前行对sum(expression)的贡献。
下例计算每个员工的工资占该类员工总工资的百分比 SQL>SELECT last_name, salary, RATIO_TO_REPORT(salary) OVER () AS rr FROM employees WHERE job_id = 'PU_CLERK';
任务实训部分
1、 假设学校环境如下:
一个系有若干个专业,每个专业一年只招一个班,每个班有若干个学生。现要建立关于系、学生、班级的数据库,关系模式如下:
班级表class(班号classid,专业名subject,系名deptname,入学年份entertime,人数num)
学生表student(学号studentid,姓名name,年龄age,班号classid)
系department(系号departmentid,系名deptname)
要求用sql语句完成如下功能:
(1)建表,并实现如下要求
A:每个表根据实际定义好主外键关系
B:系表中编号字段利用数据库自动化增长值实现
C:每个班级的人数不超过30人
D:学生年龄介于15到30之间
E:学生姓名不能为空,系名不能重复
(2)输入部分测试数据
department表:
1 数学
2 计算机
3 化学
4 中文
5 经济学
class表:
101 软件 计算机 1995 20
102 微电子 计算机 1996 30
111 无机化学 化学 1995 29
112 高分子化学 化学 1996 25
121 统计 数学 1995 20
131 现代语言 中文 1996 20
141 国际贸易 经济学 1997 30
142 国际金融 经济学 1998 14
student表:
8101 张三 18 101
8102 钱四 16 121
8103 王玲 17 131
8104 李飞 19 102
8105 王五 20 141
(3)完成下列查询:
A:列出所有人数大于等于28的系的编号和名称
B:列出所有开设超过两个专业的系的名字
C:显示每个学生的学号、姓名、专业、系名信息
2、oracle函数的使用
针对scott.emp表,实现如下查询操作:
(1) 把员工姓名和工作连接在一起,中间用“--”分隔显示。
(2) 分别显示工姓名的前三个字符和第四个字符后的内容
(3) 显示字母T在员工姓名中第一次和第二次出现的位置
(4) 显示12年前参加工作的员工信息
(5) 查询在当月倒数第三天参加工作的员工信息
(6) 显示每个员工的工作天数
(7) 按照每月30天,计算每个员工的日薪金
(8) 按照年和月的格式显示员工参加工作的时间(如 SMITH 1980 12)
(9) 查询在1987年2月到5月参加工作的员工信息(包括2月和5月)
(10) 显示每个员工的津贴信息,没有津贴就显示0
(11) 分别显示员工的总人数和津贴不为空的员工人数
(12) 显示部门最低工资大于900的部门和最低工资
(13) 显示每个部门工资在1400以上的所有员工的工资总额
(14) 显示部门名称以及该部门的员工总数,没有员工的以0显示
(15) 显示每个部门中最高工资的员工信息
(16) 计算每个部门的员工工资排名
(17) 计算每个部门的员工工资占整个部门的工资比例
(18) 计算同一部门员工的薪水累积值
3、员工培训系统的案例
Employee员工表:
EID Name Department Job Email passWord
10001 李明 SBB EG
10003 李四 LUCK ITM
11045 胡斐 SBB EG
10044 张三 MTD ETN
10023 王刚 MMM ETN
Training 培训记录表:
CourseId EID Course Grade orders
1 10001 T-SQL 60
3 11045 java 71
2 10003 oracle 59
1 10003 T-SQL 90
3 10044 java 78
2 10001 oracle 69
2 10023 oracle 70
3 20001 Java 69
3 10078 Java 58
完成如下sql语句:
(1)建立两个表的表结构,自行分析,根据需要设置主键
(2)用sql语句进行册书数据的添加
(3)列出所有员工参加培训的情况,要求显示:EID,Name,department,course,grade用一条sql语句完成
(4)列出未参加培训的员工信息,显示格式如上
(5)列出所有各课成绩最高的员工信息,显示格式如上
(6)把所有表2有但表1没有的员工编号插入表1中,一条语句完成
(7)统计各部门的人数
(8)统计各部门中姓李的人数
巩固练习
1.Oracle返回“Hello World”的函数是:()
A.UPPER
B.LOWER
C. INITCAP
D.CONCAT
1. 下面哪个分析函数返回连续的重复的行编号()
A.ROW_NUMBER
B.RANK
C.DENSE_RANK
2. SELECT ROUND (164.1666,-2) FROM DUAL返回值()
A.100
B.150
C.200
D.160
4.Oracle分析函数的特征有()
A.可以带over(partition by..order ..)
B.分析函数用于计算基于组的某种聚合值
C.它和聚合函数的不同之处是对于每个组返回多行,而聚合函数对于每个组只返回一行。
D.over在每组中定义了一个滑动窗口
新闻热点






疑难解答